Word Embedding?
-
단어를 벡터로 표현하는 기법
-
유사한 단어는 공간상에서 가까운 거리에 위치해야 한다.
-
유사하지 않은 단어는 공간상에서 먼 거리에 위치해야 한다.
Word2Vec
Deep learning혹은 Neural Network를 사용해 word representation을 학습하는 방법
- 가정 : 문맥상 가까운 단어는 의미적으로 유사하다는 가정
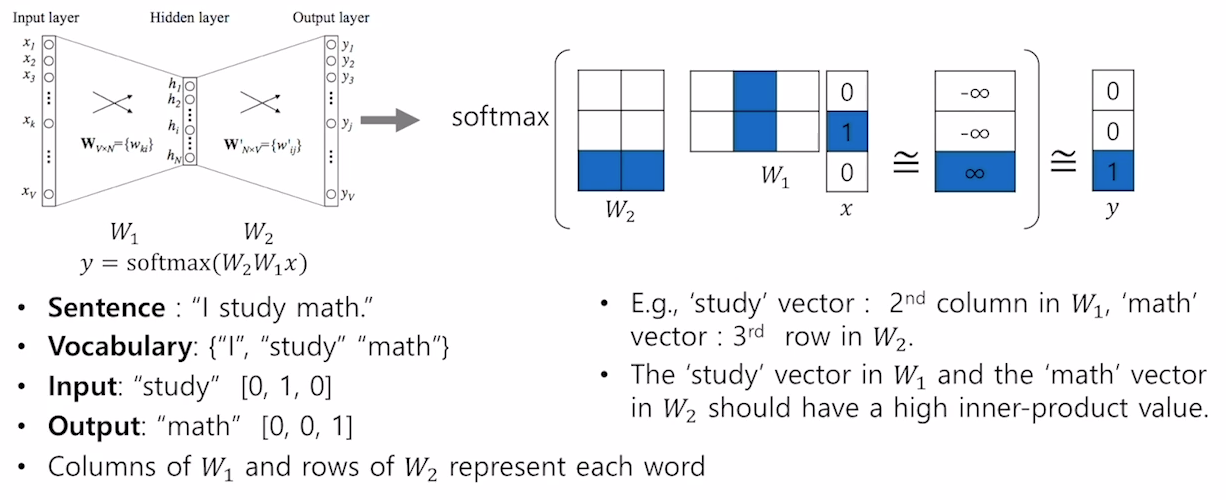
-
은 내적하면 계산량이 커 해당 index의 값을 불러오게끔 학습한다.
-
통상적으로 word embedding의 결과를 으로 사용하게 된다.
-
word2vec은 word similarity, machine translation, POS tagging, NER, sentiment anlysis, clustering 등 대부분의 NLP task에서 사용될 수 있다.
Glove
Glove도 word2vec처럼 word representation을 위한 기법이다. 큰 차이점은 word2vec은 해당 단어 주변을 통해 계산되지만 Glove는 사전에 co-occurrence matrix를 계산해 그 확률 값(을 이용해 loss를 구하는 점이다.
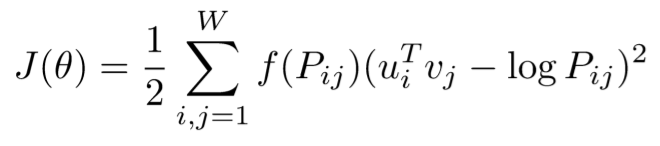
-
중복되는 계산을 줄여 학습이 더 빠르다.
-
비교적 적은 데이터에서도 잘 동작한다.
-
성능은 두 알고리즘이 비슷하다고 알려져 있다.

지식 공유