Scatter Plot
Scatter Plot이란?
-
Scatter plot은 점을 사용하여 두 feature간의 관계를 알기 위해 사용
-
산점도 등의 이름으로 사용된다.
-
직교 좌표계에서 x축/y축에 feature 값을 매핑하여 사용한다.
-
.scatter()로 사용할 수 있다.
Scatter Plot의 요소
-
점에서 다양한 variation을 사용할 수 있다.
-
색 (color)
-
모양 (marker)
-
크기 (size)
-
Scatter Plot의 목적
-
상관 관계 확인 (양/음의 상관관계 혹은 없음)
-
아래와 같은 3가지 특성을 확인할 수 있다.
-
군집
-
값 사이의 차이
-
이상치
-
정확한 Scatter Plot
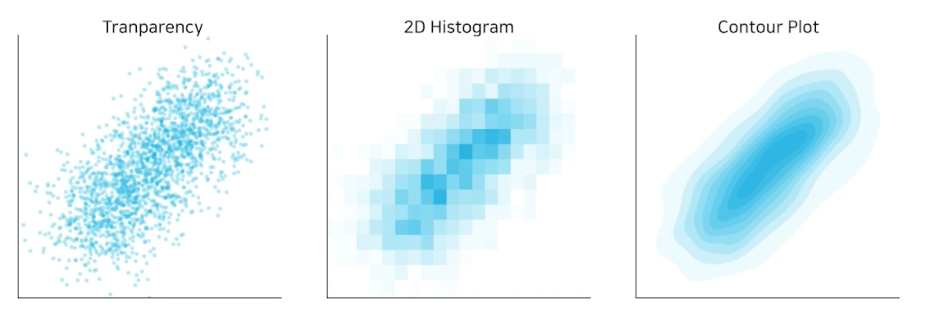
Overplotting
-
점이 많아질수록 점의 분포를 파악하기 힘들다.
-
투명도 조정
-
지터링 (jittering): 점의 위치를 약간씩 변경
-
2차원 히스토그램: 히트맵을 사용하여 깔끔한 시각화
-
Contour plot: 분포를 등고선을 사용하여 표현
-
점의 요소와 인지
-
색
- 연속은 gradient, 이산은 개별 색상으로 설정
-
마커
-
마커로 점의 양이 많아질수록 거의 구별하기 힘들다.
-
잉크 비례의 법칙에 벗어난다. (모양마다 크기가 다름)
-
-
크기
-
크기를 다르게 한 차트를 흔히 버블 차트라고 부른다.
-
구별하기는 쉽지만 오용하기 쉽다.(100을 표현한 점과 300을 표현한 점의 크기가 크게 차이 안나는 경우)
-
SWOT 분석 등에 활용할 수 있다.
-
인과관꼐와 상관관계의 구분
-
인과 관계 (causal relation)과 상관 관계(correlation)은 다르다.
-
인과 관계는 항상 사전 정보와 함께 가정으로 제시되어야 한다.
추세선
- 추세선을 사용하여 scatter의 패턴을 유추할 수 있다.
- 단, 추세선이 2개 이상이 되면 가독성이 떨어지므로 주의
ETC
-
scatter는 grid와 상성이 좋지 않아 지양한다.
-
범주형이 포함된 관계에서는 heatmap 또는 bubble chart사용
실습
기본 Scatter Plot
fig = plt.figure(figsize=(7, 7))
ax = fig.add_subplot(111, aspect=1)
np.random.seed(970725)
x = np.random.rand(20)
y = np.random.rand(20)
ax.scatter(x, y)
ax.set_xlim(0, 1.05)
ax.set_ylim(0, 1.05)
plt.show()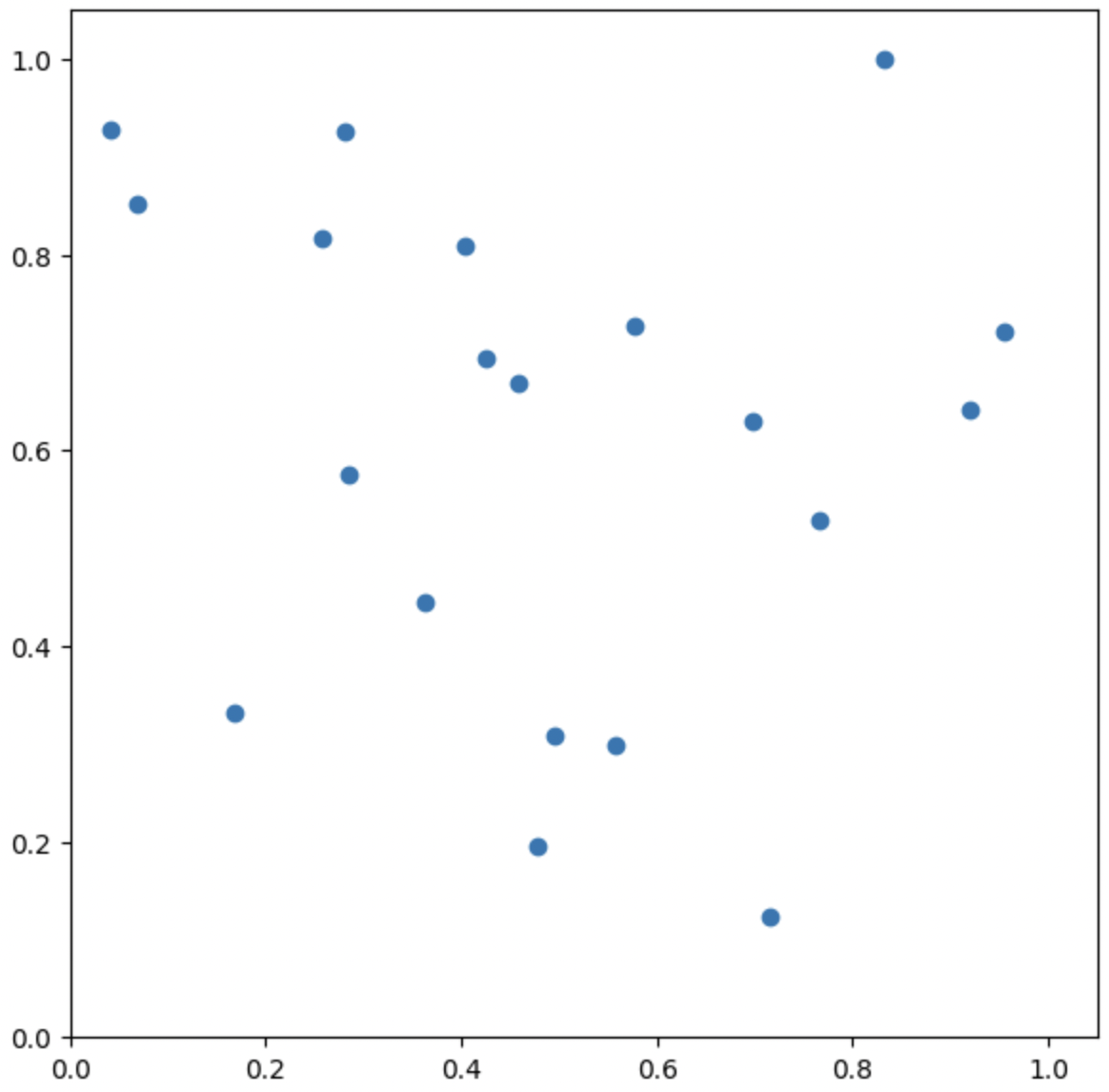
Scatter Plot의 요소
- 색(color)
- 모양(marker)
- 크기(size)
fig = plt.figure(figsize=(7, 7))
ax = fig.add_subplot(111, aspect=1)
np.random.seed(970725)
x = np.random.rand(20)
y = np.random.rand(20)
s = np.arange(20) * 20
ax.scatter(x, y,
s= s,
c='white',
marker='o',
linewidth=1,
edgecolor='black')
plt.show()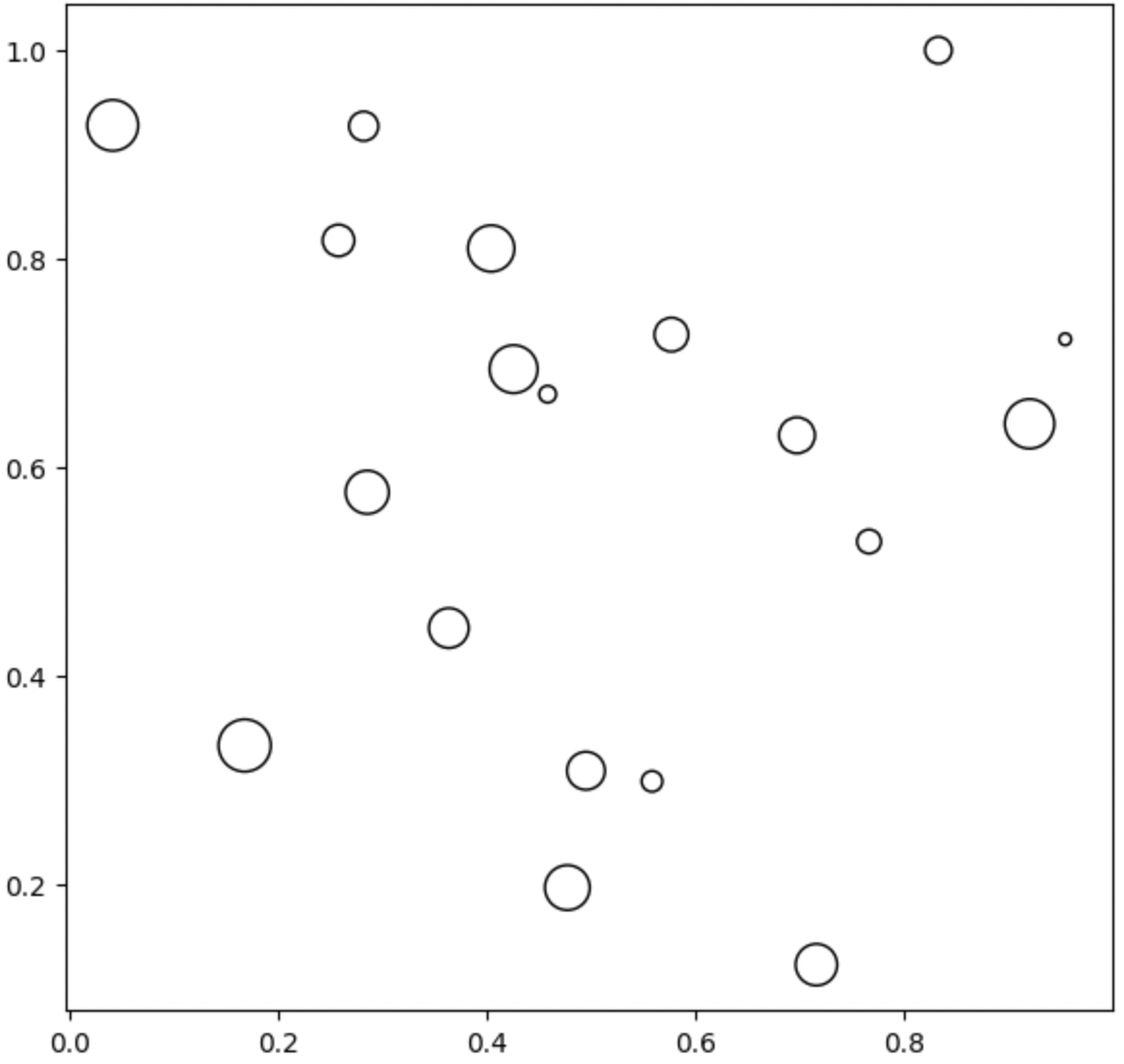
정확한 Scatter Plot 실습
Data : 봇꽃 데이터셋(iris.csv)
-
상관관계를 알아보기 위해 산점도를 그려본다.
-
seaborn이 더 적합한 라이브러리 통계부분에서는 더 특화되어 있다.
- 꽃받침의 너비와 길이의 관계
fig = plt.figure(figsize=(7, 7))
ax = fig.add_subplot(111)
ax.scatter(x=iris['SepalLengthCm'], y=iris['SepalWidthCm'])
plt.show()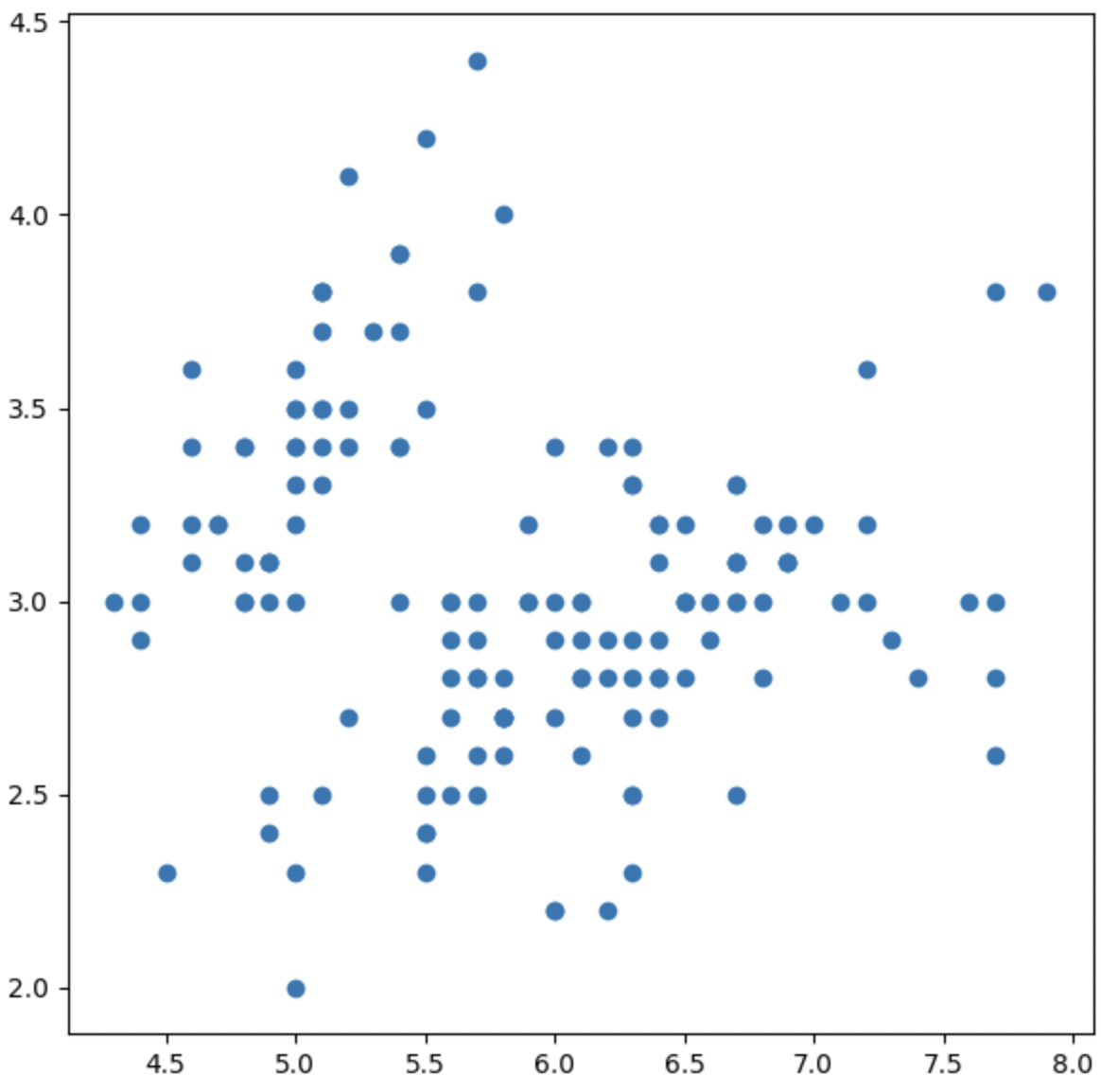
- 특정 조건에 따라 색 구분
fig = plt.figure(figsize=(7, 7))
ax = fig.add_subplot(111)
slc_mean = iris['SepalLengthCm'].mean()
swc_mean = iris['SepalWidthCm'].mean()
ax.scatter(x=iris['SepalLengthCm'],
y=iris['SepalWidthCm'],
c=['royalblue' if yy <= swc_mean else 'gray' for yy in iris['SepalWidthCm']]
)
plt.show()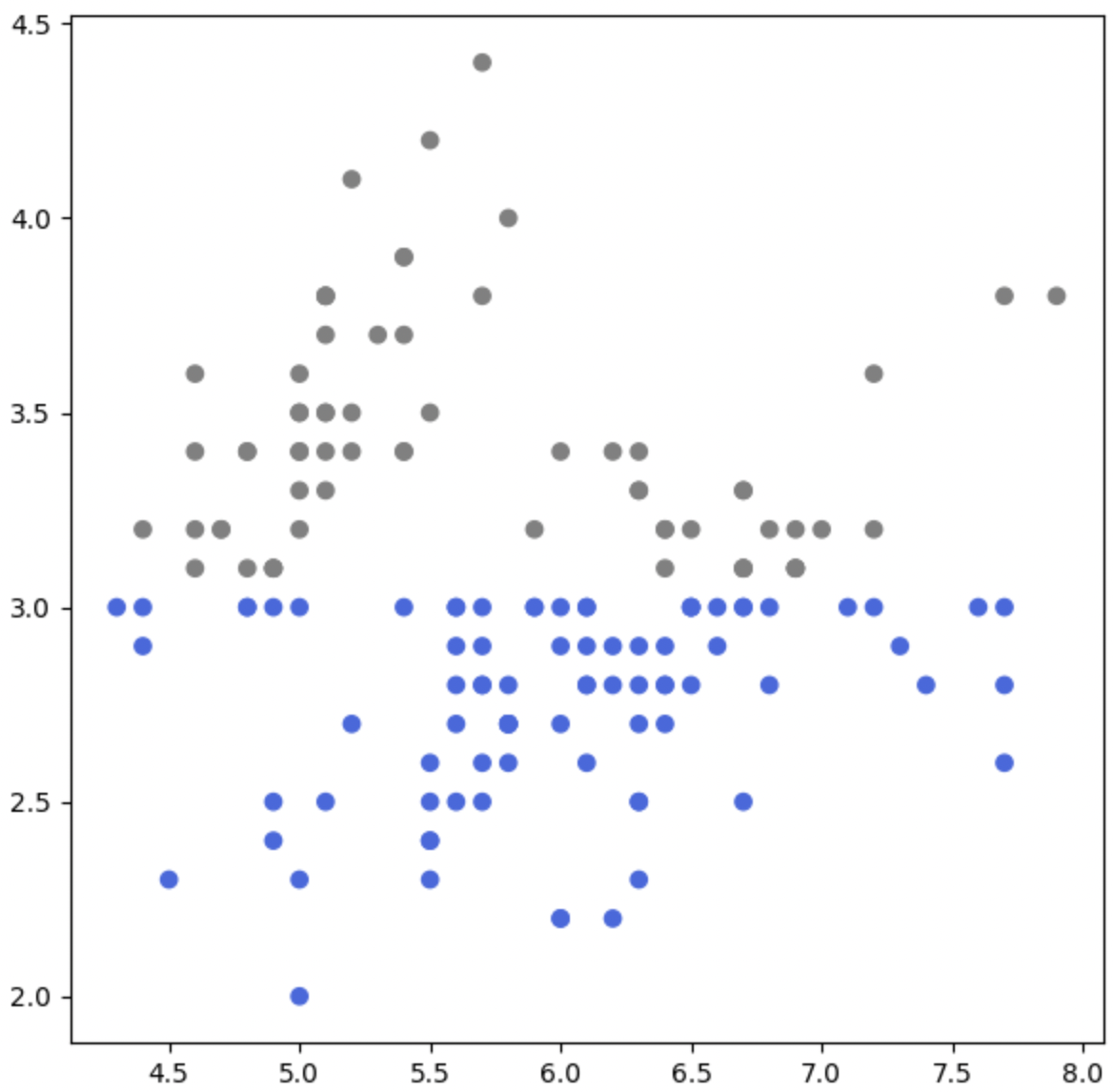
- 꽃의 종류에 따라 구분
fig = plt.figure(figsize=(7, 7))
ax = fig.add_subplot(111)
for species in iris['Species'].unique():
iris_sub = iris[iris['Species']==species]
ax.scatter(x=iris_sub['SepalLengthCm'],
y=iris_sub['SepalWidthCm'],
label=species)
ax.legend()
plt.show()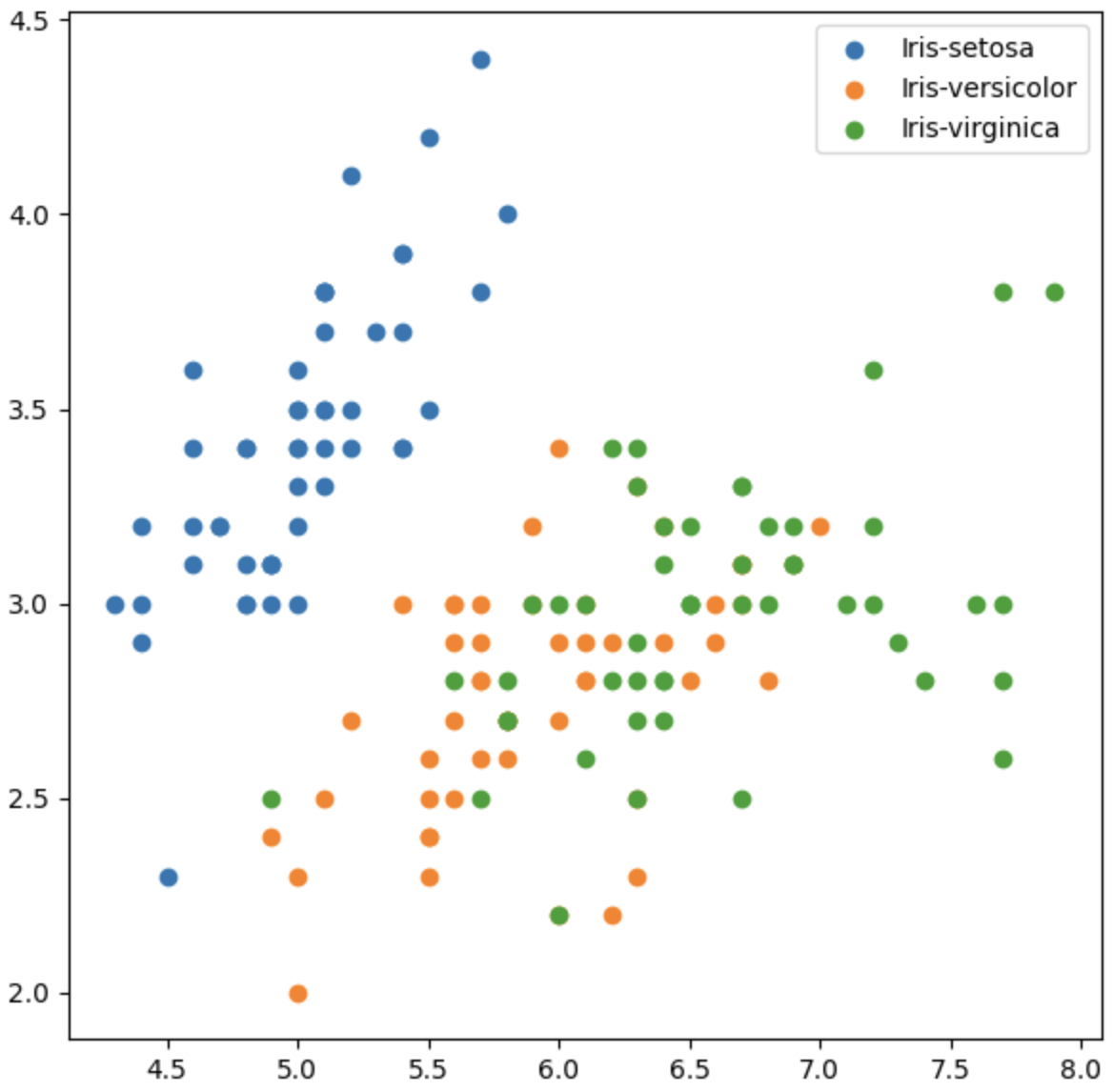
디테일 하게 세분화하여 그려보니 꽃의 종류마다의 양의 상관관계가 나타나는 것을 알 수 있으며, outlier도 확인이 가능하다.
