LlaMA 구조
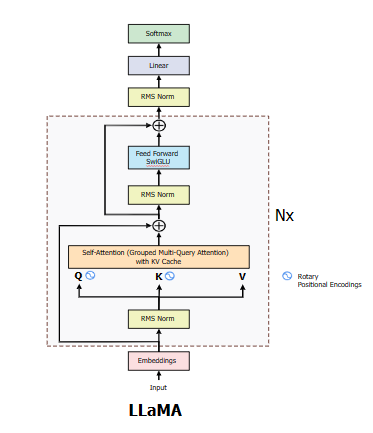
출처 : Exploring and building the LLaMA 3 Architecture : A Deep Dive into Components, Coding, and Inference Techniques
RMSNorm
hidden states의 분포를 정규화하기 위해 보통 LayerNorm을 많이 사용했지만, 현재는 RMSNorm(Root Mean Square)을 많이 사용하고 있으며 RMSNorm에 관한 수식은 아래와 같습니다.
코드로는 아래와 같이 구현되어 있습니다.
class LlamaRMSNorm:
def __init__(self, hidden_size, eps=1e-6):
self.weight = nn.Parameter(torch.ones(hidden_size))
self.variance_epsilon = eps
def forward(self, hidden_states):
input_dtype = hidden_states.dtype
hidden_states = hidden_states.to(torch.float32)
variance = hidden_states.pow(2).mean(-1, keepdim=True)
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
return self.weight * hidden_states.to(input_dtype)mean square 계산을 한 값을 variance변수에 할당하고, 루트의 역수를 취해주는 torch.rsqrt를 이용하여 계산하는 코드입니다.
Rotary Embedding
자연어처리 분야는 sequential한 데이터를 다루는 분야이고 이에 따라 모델에 position에 대한 정보를 제공해주는 연구도 지속되어 왔습니다.
Transformer는 주기를 갖는 sine, cosine을 이용해서 positional embedding을 표현했고 BERT의 경우 학습이 가능한 weight를 사용하기도 했습니다. 이러한 방법들은 입력 위치에 따른 임베딩 값을 사용하면서 absolute positional embeddings 방식이라고 표현하기도 합니다. 이 방식은 학습 중에 보지 못한 입력에 대한 확장이 어렵다는 점을 한계점으로 뽑을 수 있습니다.
이러한 한계점을 극복하기 위해 상대적인 위치 정보를 제공하는 relative positional embeddings 방식이 연구되었습니다. 이 방식은 상대적인 위치를 k로 제한하고 그 이상의 거리는 불필요한 정보로 판단하게 됩니다. 따라서 학습 중에 보지 못한 길이가 주어져도 position 정보가 상대적인 정보로 주어지기 때문에 유연하게 대처할 수 있습니다.
마지막으로 Llama에 사용된 RoPE(Rotary Position Embedding)에 대해서 알아보겠습니다. 이 전에는 position에 대한 정보를 더해주는 방식으로 진행을 했다면, Rotary embedding은 곱하는 방식으로 position 정보를 주입합니다. 그 이유는 self-attention에서 사용하는 내적 자체가 벡터 사이의 각도를 다루기 때문에 position 정보를 더해주는 것은 효율적이지 않다고 주장합니다.
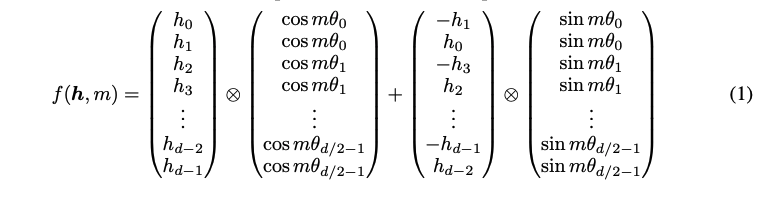
Rotary embedding은 word embedding을 복소수꼴로 변환하여 회전(rotation)시키는 방식을 이용합니다. 여기서 는 로 사용하고 있습니다. 그럼 실제로 어떻게 구현되어 있는지 살펴보겠습니다.
class LlamaRotaryEmbedding(nn.Module):
def __init__(
self,
dim=None,
max_position_embeddings=2048,
base=10000,
device=None,
scaling_factor=1.0,
rope_type="default",
config: Optional[LlamaConfig] = None,
):
super().__init__()
...
self.config = config
self.rope_init_fn = ROPE_INIT_FUNCTIONS[self.rope_type]
inv_freq, self.attention_scaling = self.rope_init_fn(self.config, device, **self.rope_kwargs)
self.register_buffer("inv_freq", inv_freq, persistent=False)
self.original_inv_freq = self.inv_freq위의 클래스 생성자에서는 중간에 config를 다루는 부분을 제외하고 최초로 rope_init_fn을 생성하고 있습니다. rope_init_fn의 종류에는 다양하게 있지만 기본 default의 함수를 살펴보면 아래와 같습니다.
def _compute_default_rope_parameters(
config: Optional[PretrainedConfig] = None,
device: Optional["torch.device"] = None,
seq_len: Optional[int] = None,
**rope_kwargs,
) -> Tuple["torch.Tensor", float]:
if config is not None and len(rope_kwargs) > 0:
raise ValueError(
"Unexpected arguments: `**rope_kwargs` and `config` are mutually exclusive in "
f"`_compute_default_rope_parameters`, got `rope_kwargs`={rope_kwargs} and `config`={config}"
)
if len(rope_kwargs) > 0:
base = rope_kwargs["base"]
dim = rope_kwargs["dim"]
elif config is not None:
base = config.rope_theta
partial_rotary_factor = config.partial_rotary_factor if hasattr(config, "partial_rotary_factor") else 1.0
dim = int((config.hidden_size // config.num_attention_heads) * partial_rotary_factor)
attention_factor = 1.0 # Unused in this type of RoPE
# Compute the inverse frequencies
inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2, dtype=torch.int64).float().to(device) / dim))
return inv_freq, attention_factor수식에서 살펴본 것과 같이 가inv_freq인 것을 알 수 있습니다. 이렇게 구한 inv_freq는 d/2의 크기를 가지고 있기 때문에 2개를 이어 붙인 후 cosine, sine 함수를 적용하여 2개의 행렬을 구하게 됩니다.
@torch.no_grad()
def forward(self, x, position_ids):
if "dynamic" in self.rope_type:
self._dynamic_frequency_update(position_ids, device=x.device)
# Core RoPE block
inv_freq_expanded = self.inv_freq[None, :, None].float().expand(position_ids.shape[0], -1, 1)
position_ids_expanded = position_ids[:, None, :].float()
# Force float32 (see https://github.com/huggingface/transformers/pull/29285)
device_type = x.device.type
device_type = device_type if isinstance(device_type, str) and device_type != "mps" else "cpu"
with torch.autocast(device_type=device_type, enabled=False):
freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(1, 2)
emb = torch.cat((freqs, freqs), dim=-1)
cos = emb.cos()
sin = emb.sin()
# Advanced RoPE types (e.g. yarn) apply a post-processing scaling factor, equivalent to scaling attention
cos = cos * self.attention_scaling
sin = sin * self.attention_scaling
return cos.to(dtype=x.dtype), sin.to(dtype=x.dtype)마지막으로 어떻게 계산이 이루어지는지 알아보겠습니다.
def rotate_half(x):
x1 = x[..., : x.shape[-1] // 2]
x2 = x[..., x.shape[-1] // 2 :]
return torch.cat((-x2, x1), dim=-1)
def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
cos = cos.unsqueeze(unsqueeze_dim)
sin = sin.unsqueeze(unsqueeze_dim)
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embed입력으로는 query와 key 그리고 위에서 구한 cosine, sine을 입력으로 받습니다. 위의 보았던 수식 처럼 두 번째 항의 절반은 음의 값을 취하여 회전(rotation)하도록 하는 rotate_half함수를 적용합니다. 최종적으로는 를 곱하는 방식으로 query와 key의 embedding 값을 구하고 있습니다.
LlamaMLP
class LlamaMLP(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.hidden_size = config.hidden_size
self.intermediate_size = config.intermediate_size
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=config.mlp_bias)
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=config.mlp_bias)
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=config.mlp_bias)
self.act_fn = ACT2FN[config.hidden_act]
def forward(self, x):
if self.config.pretraining_tp > 1:
slice = self.intermediate_size // self.config.pretraining_tp
gate_proj_slices = self.gate_proj.weight.split(slice, dim=0)
up_proj_slices = self.up_proj.weight.split(slice, dim=0)
down_proj_slices = self.down_proj.weight.split(slice, dim=1)
gate_proj = torch.cat(
[F.linear(x, gate_proj_slices[i]) for i in range(self.config.pretraining_tp)], dim=-1
)
up_proj = torch.cat([F.linear(x, up_proj_slices[i]) for i in range(self.config.pretraining_tp)], dim=-1)
intermediate_states = (self.act_fn(gate_proj) * up_proj).split(slice, dim=2)
down_proj = [
F.linear(intermediate_states[i], down_proj_slices[i]) for i in range(self.config.pretraining_tp)
]
down_proj = sum(down_proj)
else:
down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
return down_projLlaMA의 MLP layer는 3개의 nn.Linear를 사용하여 구성되어 있습니다. 3개의 layer는 마치 attention score를 구하는 것과 유사하게 계산이 되어 지고, pretraining_tp가 1이 아니게 되면 조금 더 복잡하고 느리지만 더 정확한 로짓값을 구할 수 있다고 합니다.
Self-Attention
class LlamaAttention(nn.Module):
"""Multi-headed attention from 'Attention Is All You Need' paper"""
def __init__(self, config: LlamaConfig, layer_idx: Optional[int] = None):
super().__init__()
self.config = config
self.layer_idx = layer_idx
if layer_idx is None:
logger.warning_once(
f"Instantiating {self.__class__.__name__} without passing a `layer_idx` is not recommended and will "
"lead to errors during the forward call if caching is used. Please make sure to provide a `layer_idx` "
"when creating this class."
)
self.attention_dropout = config.attention_dropout
self.hidden_size = config.hidden_size
self.num_heads = config.num_attention_heads
self.head_dim = self.hidden_size // self.num_heads
self.num_key_value_heads = config.num_key_value_heads
self.num_key_value_groups = self.num_heads // self.num_key_value_heads
self.max_position_embeddings = config.max_position_embeddings
self.rope_theta = config.rope_theta
self.is_causal = True
if (self.head_dim * self.num_heads) != self.hidden_size:
raise ValueError(
f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"
f" and `num_heads`: {self.num_heads})."
)
self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=config.attention_bias)
self.k_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=config.attention_bias)
self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=config.attention_bias)
self.o_proj = nn.Linear(self.hidden_size, self.hidden_size, bias=config.attention_bias)
# TODO (joao): remove in v4.45 (RoPE is computed in the model, not in the decoder layers)
self.rotary_emb = LlamaRotaryEmbedding(config=self.config)LLaMA의 Self-Attention은 Grouped-Query Attention을 적용해서 사용합니다. 따라서 self.num_heads와 self.num_key_value_heads, self.num_key_value_groups가 따로 존재하는 것을 확인할 수 있습니다. LLaMA-1의 경우 Multi-Query Attention을 적용했는데 이는 Key, Value의 layer가 1개로 고정되고 Query layer만 n개로 사용하는 방식이라면 현재는 Key, Value layer가 k개이고 Query layer가 n개로 사용하고 있습니다(k < n).
def forward(...):
...
query_states = self.q_proj(hidden_states)
key_states = self.k_proj(hidden_states)
value_states = self.v_proj(hidden_states)
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
if position_embeddings is None:
cos, sin = self.rotary_emb(value_states, position_ids)
else:
cos, sin = position_embeddings
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)forward()함수를 살펴 보면, query, key, value의 linear layer를 통해 각각의 states를 구한 후, 위에서 구했던 rotary embedding을 사용하여 query, key의 states에 position 정보를 추가해줍니다.
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
"""
This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
"""
batch, num_key_value_heads, slen, head_dim = hidden_states.shape
if n_rep == 1:
return hidden_states
hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
key_states = repeat_kv(key_states, self.num_key_value_groups)
value_states = repeat_kv(value_states, self.num_key_value_groups)Key, Value states는 위의 함수를 적용시키기 되는데 결국 num_key_value_heads를 num_key_value_groups만큼 반복시키기 되고 그 차원은 (Batch, Num Heads, Seq, Dim)으로 변환되어 지게 됩니다.
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
# upcast attention to fp32
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
attn_weights = nn.functional.dropout(attn_weights, p=self.attention_dropout, training=self.training)
attn_output = torch.matmul(attn_weights, value_states)
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.reshape(bsz, q_len, -1)
attn_output = self.o_proj(attn_output)마지막으로 attention계산과 o_proj를 통해 최종 출력을 구하게 됩니다.
DecoderLayer
class LlamaDecoderLayer(nn.Module):
def __init__(self, config: LlamaConfig, layer_idx: int):
super().__init__()
self.hidden_size = config.hidden_size
self.self_attn = LLAMA_ATTENTION_CLASSES[config._attn_implementation](config=config, layer_idx=layer_idx)
self.mlp = LlamaMLP(config)
self.input_layernorm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.post_attention_layernorm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)Decoder layer를 위에서 설명한 모듈들을 하나의 Layer로 합치고 있습니다.
LlamaModel
class LlamaModel(LlamaPreTrainedModel):
"""
Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`LlamaDecoderLayer`]
Args:
config: LlamaConfig
"""
def __init__(self, config: LlamaConfig):
super().__init__(config)
self.padding_idx = config.pad_token_id
self.vocab_size = config.vocab_size
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
self.layers = nn.ModuleList(
[LlamaDecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
)
self.norm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.rotary_emb = LlamaRotaryEmbedding(config=config)최종적으로, LLaMA 모델은 n개의 Decoder Layer를 갖도록 구성하고 학습되게 됩니다.
class LlamaForCausalLM(LlamaPreTrainedModel):
_tied_weights_keys = ["lm_head.weight"]
def __init__(self, config):
super().__init__(config)
self.model = LlamaModel(config)
self.vocab_size = config.vocab_size
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
# Initialize weights and apply final processing
self.post_init()추가적으로 가장 많이 사용하는 클래스인 LlamaForCausalLM 같은 경우는 LlamaModel과 nn.Linear를 이용하여 다음 토큰을 예측하도록 lm_head 구성되어 있습니다.
