논문 링크 : Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
Background
Problem state
- Convnet의 최상위 layer의 표현으로 이미지 정보를 사용하는 것은 정보 손실의 원인이 될 수 있음
Contribution
-
Attention을 적용한 caption(soft/hard) 제안
-
attention을 통해 어디에, 무엇을 집중하는지 시각화하여 보여줌
-
caption generation을 정량적으로 평가하여 SOTA 달성
Method
-
bold체는 vector, captial 체는 matrix를 의미
-
본 논문의 모델은 하나의 raw image와 encoding된 단어 1-of-K의 sequence로 인코딩 된 caption y를 사용
y={y1,...,yc},yi∈RKK=size of vocabularyC=length of the caption
ENCODER: Convolutional Features
- feature vector를 추출하기 위해 CNN을 사용하고, extractor는 image의 각 부분을 D차원을 가진 L개의 vector를 생산
a={a1,...,aL},ai∈RD
- 2D image 부분과 feature vectors 사이의 관련성을 얻기 위해, fully connected layer를 사용했던 이전 연구와는 달리 lower convolutional layer에서 feature를 추출함
ai는 annotation vector로 이전 연구의 feature vector와 동일한 의미이다.
DECODER: Long Short-Term Memory Network
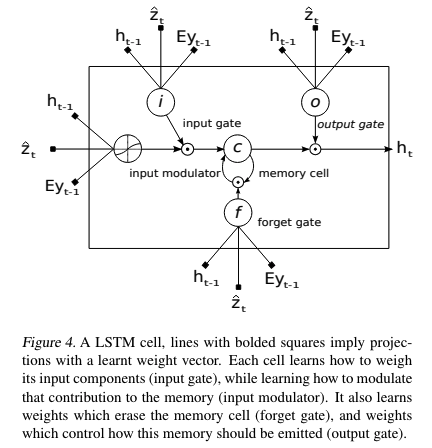
- Decoder로는 LSTM을 사용하고 아래의 수식에서 i,f,c,o,h,z^는 각각 LSTM의 input, forget, memory, output, hidden state, 입력 image의 특정 위치 정보가 담긴 context vector를 의미함
⎝⎜⎜⎜⎛itftotgt⎠⎟⎟⎟⎞=⎝⎜⎜⎜⎛σσσtanh⎠⎟⎟⎟⎞TD+m+n,n⎝⎜⎛Eyt−1ht−1z^t⎠⎟⎞ct=ft⊙ct−1+it⊙gtht=ot⊙tanh(ct)
- E∈Rm×K는 embedding matrix, m,n은 embedding과 LSTM의 차원, σ,⊙은 sigmoid activation과 element-wise multiplication을 의미함
- LSTM의 c0,h0는 아래와 같은 초기값을 사용
c0=finit,c(L1i∑Lai)h0=finit,h(L1i∑Lai)
Hard vs. Soft Attention

- attention model (fatt)의 2가지 메카니즘
Hard Attention
-
annotation vector가 one-hot encoding으로 표현되는 것. 즉, 이미지의 여러 픽셀 중 하나의 영역에 집중
-
st,i는 t시점에서의 i번째(14x14 라면, 196) 픽셀에 대한 one-hot encoding 값을 나타냄, 이때 1이 되는 확률 값은 attention score(αt,i)가 사용됨
eti=fatt(ai,ht−1)αt,i=∑k=1Lexp(etk)exp(eti)p(st,i=1∣sj<t,a)=αt,i
- st,i는 a와 곱하여 attention 결과로 사용할 수 있고 아래와 같이 표현할 수 있음
z^t=i∑st,iai
- loss function : image features(a)에 대해 caption(y)의 log likelihood를 최대화
Ls=s∑p(s∣a)logp(y∣s,a)≤logs∑p(s∣a)p(y∣s,a)=logp(y∣a)
- 위의 식에서 lower bound인 부분을 loss로 사용하고 W에 대해서 미분하면 아래와 같이 쓸 수 있음
∂W∂L=s∑[p(s∣a)∂W∂logp(y∣s,a)+logp(y∣s,a)∂W∂p(s∣a)]=s∑[p(s∣a)∂W∂logp(y∣s,a)+logp(y∣s,a)⋅p(s∣a)∂W∂logp(s∣a)]=s∑p(s∣a)[∂W∂logp(y∣s,a)+logp(y∣s,a)∂W∂logp(s∣a)]
- Monte Carlo Estimation을 적용하여 다시 작성할 수 있음. s~t는 multinoulli distribution에서 N개를 sampling하는 의미.
s~t∼MultinoulliL({αi})∂W∂Ls≈N1n=1∑N[∂W∂logp(y∣s∼n,a)+logp(y s∼n,a)]
- Monte Carlo estimator를 사용할 때 커지는 분산을 줄이기 위해 moving average를 사용함
bk=0.9×bk−1+0.1×log p(y∣s~k,a)
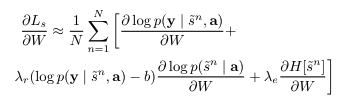
-
λr,λe는 exponential moving average와 entropy term의 비율을 타나내는 파라미터
-
0.5 확률로 s~의 값을 α로 사용
Soft Attention
- Hard Attention에서는 매 time마다 st를 sampling 해서 사용하지만 Soft Attention에서는 z^t를 사용함
Ep(st∣a)[z^t]=i=1∑Lαt,iai
-
hard attention에서는 α가 가장 높은 값 하나(one-hot)를 사용 했지만, soft attention에서는 α자체를 ai에 곱하여 사용
-
k번째 word를 예측 하기 위해 normalized weighted geometric mean을 정의
NWGM[p(yt=k∣a)]=∑jΠiexp(nt,j,i)p(st,i=1∣a)Πiexp(nt,k,i)p(st,i=1∣a)=∑jexp(Ep(st∣a)[nt,j])exp(Ep(st∣a)[nt,k])
- E[nt]=Lo(Eyt−1+Lh)E[ht]+LzE[zt^], 즉, LSTM의 output gate를 통과한 값을 의미
Doubly Stochastic Attention
-
doubly stochastic attention은 ∑iαt,i=1이 되도록 하면서 규제항(∑tαt,i=1)도 추가하여 학습
-
쉽게 말해 196개의 픽셀들의 score가 1이 되록하면서, caption의 time 별로의 pixel score도 1이 되도록 학습하는 것
-
이론적으로 모든 time 별로의 픽셀의 합이 1이 되는 것은 불가능 하지만 1이 되도록 규제를 하는 것
-
regularization loss
λi∑P(1−t∑Tat,i)2
Ld=−log(P(y∣x))+λi∑P(1−t∑Tat,i)2
Results
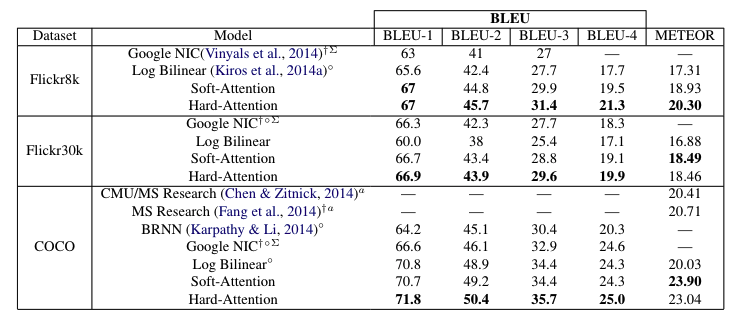
- hard attention이 soft attention보다 좋은 성능을 보여줌
Conclusion
- 기존 caption 프로세스에 attention을 추가하여 SOTA 달성
