Apache Airflow 소개
Batch Process란
Batch Processing이란 예약된 시간에 실행되는 프로세스로 일회성도 가능하고 주기적인 실행도 가능하다.
Batch Process를 머신러닝 엔지니어가 알아야 하는 이유는 모델을 주기적으로 학습시키는 경우 사용한다. 또한 주기적인 Batch Serving, 그 외 개발에서 필요한 배치성 작업에서 적용할 수 있다.
예를들어 특정시간에 머신러닝 모델 학습 report결과를 보고 싶을때 사용할 수 있다.
Batch Process - Airflow 등장 전
현재도 많이 사용하고 있는 Linux Crontab을 사용해 왔다. Linux는 기본적으로 설치되어 있기 때문에 크론 표현식만 숙지하면 매우 간편하게 적용해볼 수 있다. 크론 표현식은 크론 제너레이터사이트를 이용해서도 생성할 수 있다. UTC의 시간존만 주의해서 사용하자.
Linux Crontab의 문제
- 파일을 실행하다 오류가 발생한 경우, 크론탭이 별도의 처리를 하지 않음
- 실패할 경우 자동으로 몇 번 더 재실행하고, 계속 실패한다면 알람을 받고 싶음
- 과거 실행 이력 및 실행 로그를 보기 어려움
- 여러 파일을 실행하거나 복잡한 파이프라인을 만들기 힘듬
Airflow 소개
Airflow는 실패 후 자동으로 작업 재실행, 종속성 기능(다른 작업 완료 후 시작), 모니터링(UI제공), DAG 실패에 대한 경고 등의 기능을 제공한다.
현재 스케줄링, 워크플로우 도구의 표준이 되었으며 에어비앤비에서 개발했다.
스케줄링 도구로 무거울 수 있지만 거의 모든 기능을 제공하고 확장성이 넓어 일반적으로 스케줄링과 파이프라인 작성 도구로 많이 사용하고 특히 데이터 엔지니어링 팀에서 많이 사용한다.
Apache Airflow 실습하며 배워보기
설치하고 실행하기
-
실습을 위한 가상환경을 생성 후
pip install apache-airflow==2.2.0으로 설치한다. Airflow는 버전에 따라 이슈가 많으므로 실습을 위해 같은 버전을 설치하는게 좋다. -
설치가 완료되면 Airflow 기본 디렉토리 경로를 지정해야 하는데
export AIRFLOW_HOME=.현재 위치로 적용한다. -
Airflow에서 사용할 DB를 초기화 하기 위해
airflow db init명령어를 사용한다. 초기화가 완료되면 기본 파일이 생성된 것을 확인할 수 있다.

-
Airflow는 웹 페이지에 접속할 때 계정이 필요하여 사용할 admin 계정을 생성 한다.
airflow users create --username admin --password 1234 --firstname hyunsoo --lastname kim --role Admin --email hyunsoo@naver.com -
계정 생성이 완료되면
airflow webserver --port 8080으로 웹서버를 실행시킨 후 접속해본다.

- 생성한 admin계정으로 접속해본다.

웹 대시보드 화면을 보면 스케줄러가 실행중이지 않는 경고문이 보이고 예시 DAG들을 확인할 수 있다.
- 스케줄러를 실행시키기 위해 별도의 터미널을 띄운 후
export AIRFLOW_HOME=.을 한 후airflow scheduler를 실행시킨다.

경고문이 사라진것을 확인할 수 있다.
기본적으로 제공되는 여러 DAG이 있다. DAG이란 Airflow에서 실행할 작업들을 순서에 맞게 구성한 워크플로우를 의미하며 Directed Acyclic Graph의 약자이다. DAG을 구성하는 각 작업들을 태스크(Task)라고 부르며 DAG은 Task의 관계와 종속성을 반영하여 구조화 되어 있다.
Airflow는 Crontab처럼 단순히 하나의 파일을 실행하는 것이 아닌 여러 작업(Task)의 조합(DAG)도 가능하기 때문에 복잡한 워크플로우를 설계할 수 있다.
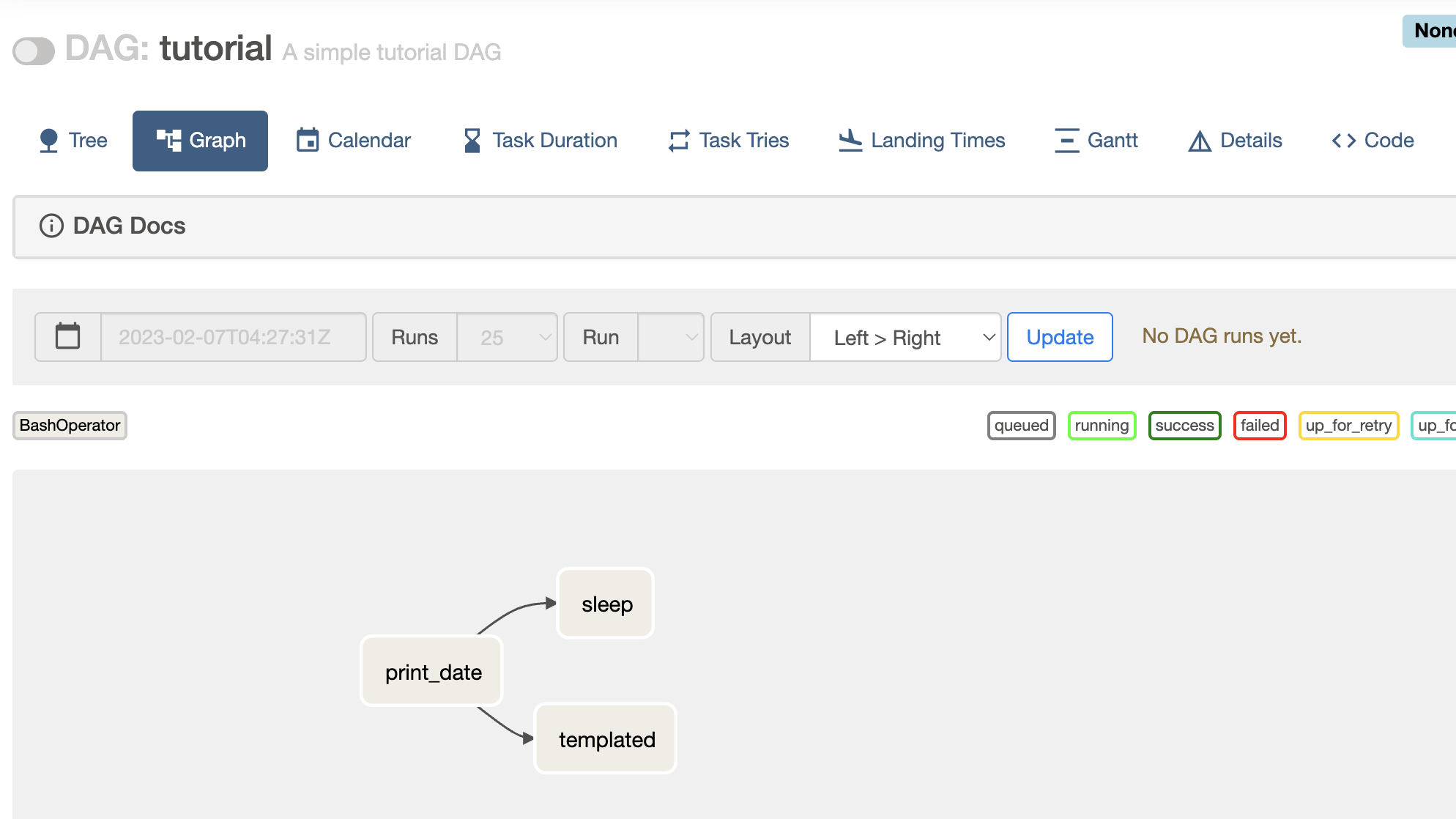
여러가지 샘플 DAG 중 tutorial_etl_dag을 확인해보면 아래와 같다.

이 DAG을 실행하면 3가지 TASK가 순차적으로 실행이 된다.
아래와 같이 Task가 꼭 순차적으로 진행하지 않게 구성할 수도 있다.
DAG 작성하기
기본적으로 DAG을 저장할 디렉토리를 생성하야 한다. (AIRFLOW_HOME에 지정한 디렉토리로 이동하여 이름은 무조건 dags로 생성한다.)

파일을 저장 후 잠깐의 시간이 흐르면 웹 UI를 확인해보면 새로운 DAG이 보인다.


현재 DAG을 실행하고 잠시 기다리면 실행된 결과를 볼 수 있다.

세로 한줄이 하나의 실행을 의미한다. 맨 위의 원은 하나의 DAG 실행을 의미하며 하나의 실행을 DAG Run이라고 부른다. 아래의 사각형은 하나의 Task를 의미한다.
사각형을 눌러 각 Task의 Log정보를 볼 수 있다.

만약 특정 DAG Run의 기록을 지우고 다시 실행시키고 싶으면 해당 원을 클릭하여 Clear를 누르면 된다.
유용한 Operator 소개
PythonOperator
-
파이썬 함수를 실행하고 함수 뿐 아니라, Callable한 객체를 파라미터로 넘겨 실행할 수 있다.
-
실행할 파이썬 로직을 함수로 생성한 후 PythonOperator로 실행할 수 있다.
BashOperator
-
Bash 커맨드를 실행할 수 있다.
-
실행해야 할 프로세스가 파이썬이 아닌 경우에도 BashOperator로 실행가능(e.g shell, scala 파일 등)
DummyOperator
-
아무것도 실행하지 않음
-
DAG 내에서 Task를 구성할 때, 여러개의 Task의 SUCCESS를 기다려야 하는 복잡한 Task 구성에서 사용

- 위와 같은 상황에서 E를 DummyOperator를 사용해서 작업을 모아두는 역할을 할 수 있다.
SimpleHttpOperator
-
특정 호스트로 HTTP 요청을 보내고 Response를 반환
-
파이썬 함수에서 requests모듈을 사용하여 PythonOperator를 사용해도 무방하지만 이런 기능이 이미 존재하는 것을 알면 좋다.
etc
-
BranchOperator
-
DockerOperator
-
KuberntesOperator
-
CustomOperator
-
Provider Packages

다루지 않은 내용
Airflow DAG을 더 풍부하게 작성할 수 있는 방법으로 아래와 같은 방법이 있다.
-
Variable : Airflow Console에서 변수를 저장해 Airflow DAG에 활용가능
-
Connection & Hooks : 연결하기 위한 설정
-
Sensor : 외부 이벤트를 기다리며 특정 조건이 만족하면 실행
-
Marker : Sensor와 비슷한 경우
-
Xcoms : Task끼리 결과를 주고받고 싶은 경우 사용
Apache Airflow 아키텍처와 활용방안
기본 아키텍쳐

DAG Directory
우리가 만들었던 dags폴더를 의미하며 $AIRFLOW_HOME/dags로 경로를 설정한다. DAG_FOLDER라고도 부르며 이 폴더 내부에서 폴더 구조를 어떻게 두어도 상관 없으며 Scheduler에 의해 .py 파일은 모두 탐색되고 파싱된다.
Scheduler
Scherduler는 각종 메타 정보의 기록을 담당하며 DAG들의 스케줄링 관리 및 처리를 담당한다. 실행 진행 상황과 결과를 DB에 저장하게 되고 Executor를 통해 실제로 스케줄링된 DAG을 실행한다.
Airflow에서 가장 중요한 컴포넌트라고 할 수 있다.
Schduler - Executor
Executor는 스케줄링된 DAG을 실행하는 객체로 크게 두개의 종류로 나뉜다.
Local Executor
Local Executor는 DAG Run을 프로세스 단위로 실행하며 아래와 같이 나뉜다.
- Local Executor
- 하나의 DAG Run을 하나의 프로세스로 띄워서 실행
- 최대로 생성할 프로세스 수를 정해야 한다.
- Airflow를 간단하게 운영할때 적합
- Sequential Executor
- 하나의 프로세스에서 모든 DAG Run을 처리
- Airflow 기본 Executor로 별도 설정이 없으면 이 Executor 사용
- Airflow를 테스트로 잠시 운영할 때 적합
Remote Executor
DAG Run을 외부 프로세스로 실행한다.
- Celery Executor
- DAG Run을 Celery Worker Process로 실행
- 보통 Redis를 중간에 두고 같이 사용
- Local Executor를 사용하다 Airflow 운영 규모가 커지면 전환한다.
- Kubernetes Executor
- 쿠버네티스 상에서 Airflow를 운영할 때 사용
- DAG Run 하나가 하나의 Pod(쿠버네티스의 컨테이너 같은 개념)
- Airflow 운영 규모가 큰 팀에서 사용
이외에도 다양한 종류가 있으며 라인기술블로그를 참고할 수 있다.
Worker
DAG을 실제로 실행하는 객체이며 Scheduler에 의해 생기고 실행된다.
Executor에 따라 워커의 형태가 다르며 Celery 혹은 Local일 경우 Worker는 프로세스이며 Kubernetes인 경우 pod이다. DAG을 실행하면서 생기는 로그를 저장하는것도 Worker가 담당한다.
Metadata Database
메타 정보를 저장하는 컴포넌트이다. Scheduler에 의해 쌓이게 되며 보통 MySQL이나 Postgres를 사용하게 된다. 파싱한 DAG의 정보나 상태, 실행 내용등을 저장하며 User와 Role에 대한 정보도 저장을 하게 된다. 실제 운영 환경에서는 GCP Cloud SQL이나 AWS Aurora DB 등 외부 DB인스턴스를 사용한다.
Webserver
WEB UI를 담당하며 Metadata DB와 통신하며 유저에게 필요한 메타 데이터를 웹 브라우저에 시각화를 담당한다. 보통 Airflow 사용자들은 이 웹서버를 이용하여 DAG을 ON/OFF 하며 상태를 파악하게 된다. REST API도 제공하므로 꼭 WEB UI를 통해서 통신하지 않아도 되며 다른 컴포넌트에 비해 웹 서버가 당장 작동하지 않아도 Airflow에 큰 장애가 발생하진 않는다.
Airflow 실제 활용 사례
Airflow를 구축하는 방법으로 보통 3가지 방법을 사용한다.
-
Managed Airflow (GCP Composer, AWS MWAA)
-
VM + Docker compose
-
Kubernetes + Helm
Managed Airflow
클라우드 서비스 형태로 Airflow를 사용하는 방법이다. AWS MWAA, GCP Cloud Composer가 이에 해당한다.
보통 별도의 데이터 엔지니어가 없고 분석가로 이루어진 데이터 팀이 초기에 활용하기 좋다.
장점)
- 설치와 구축을 클릭 몇번으로 클라우드 서비스가 다 진행
- 유저는 DAG 파일을 스토리지 형태로 관리
단점)
- 비용
- 자유도가 적음. 클라우드에서 기능을 제공하지 않으면 불가능한 제약이 많음
VM + Docker compose
직접 VM 위에서 Docker compose로 Airflow를 배포하는 방법이다.
Airflow 구축에 필요한 컴포넌트(Scheduler, Webserver, DB 등) Docker container 형태로 배포한다.

보통 데이터 팀에 데이터 엔지니어가 적제 존재하는 데이터 팀에 적합하다.
장점)
- Managed Service 보다는 복잡하지만 어려운 난이도는 아니다.
- Docker와 Docker compose에 익숙한 사람이라면 금방 익힐 수 있다.
- 하나의 VM만을 사용하기 때문에 단순하다.
단점)
- 각 도커 컨테이너 별로 환경이 다르므로 관리 포인트가 늘어난다.
- 예를 들어 특정 컨테이너가 갑자기 죽을 수 있고 특정 컨테이너에 라이브러리를 설치했다면 나머지 컨테이너에도 하나씩 설치해야 한다.
Kubernetes + Helm
Kubernetes 환경에서 Helm 차트로 Airflow를 배포하는 방법이다. Kubernetes는 여러 개의 VM을 동적으로 운영하는 일종의 분산환경으로 리소스 사용이 매우 유연한게 대표적인 특징이다. 이런 특징 덕분에 특정 시간에 배치 프로세스를 실행시키는 Airflow와 궁합이 매우 잘 맞는다. Airflow DAG 수가 몇 백개로 늘어나도 오토 스케일링으로 모든 프로세스를 잘 처리할 수 있다. 하지만 쿠버네티스 자체에 난이도가 있는 만큼 구축과 운영이 어렵다.

MLOps 관점의 Airflow
Airflow는 데이터엔지니어링에서 많이 사용하지만 MLOps에서도 활용할 수 있다.
아래와 같은 상황 주기적인 실행이 필요한 경우에 활용할 수 있다.
-
Batch Training: 1주일 단위로 모델 학습
-
Batch Serving(Batch Inference): 30분 단위로 인퍼런스
-
인퍼런스 결과를 기반으로 일자별, 주차별 모델 퍼포먼스 Report 생성
-
MySQL에 저장된 메타데이터를 데이터 웨어하우스로 1시간 단위로 옮기기
-
AWS S3, GCS 등 Object Storage
-
Feature Store를 만들기 위해 Batch ETL 실행
추천 글
