BentoML
BentoML 소개
Serving Infra는 모든 회사에서 사용될 수 있는 Base Component이다. 많은 라이브러리가 등장하고 있으며 각 라이브러리 마다 핵심 문제가 존재한다.
BentoML이 해결하는 문제
Model Serving Infra의 어려움
-
Serving을 위해 다양한 라이브러리, Artifact, Assets 등 사이즈가 큰 파일을 패키징
-
Cloud Service에 지속적인 배포를 위한 많은 작업이 필요
-
BentoML은 CLI로 이 문제의 복잡도를 낮춤(CLI 명령어로 모두 진행이 가능하도록 함)
Online Serving의 Monitoring 및 Error Handling
-
Online Serving으로 API 형태로 생성
-
Error처리, Logging을 추가로 구현해야 함
-
BentoML은 Python Logging Module을 사용해 Access Log, Prediction Log를 기본으로 제공한다.
-
Config를 수정해 Logging도 커스텀할 수 있고 Prometheus같은 Metric 수집 서버에 전송할 수 있음
Online Serving 퍼포먼스 튜닝의 어려움
- BentoML은 Adaptive Micro Batch 방식을 채택해 동시에 많은 요청이 들어와도 높은 처리량을 보여준다.
BentoML 특징
-
쉬운 사용성
-
Online/Offline Serving 지원
-
TF, PyTorch, Keras, XGBoost 등 Major 프레임워크 지원
-
Docker, k8s, AWS, Azure 등 배포 환경 지원 및 가이드 제공
-
Flask 대비 100배의 처리량
-
모델 저장소(Yatai) 웹 대시보드 제공
-
데이터 사이언스와 DevOps 사이의 간격을 이어주며 높은 성능의 Serving이 가능하게 함
BentoML 시작하기
BentoML 설치
-
BentoML은 python 3.6 이상 버전을 지원
-
pyenv 등으로 python 3.8로 지정
pip install bentoml
BentoML 사용 Flow
-
모델 학습 코드 생성
-
Prediction Service Class 생성
-
Prediction Service에 모델 저장(Pack)
-
(Local) Serving 후 테스트
-
Docker Image Build(컨테이너화)
-
Serving 배포
기존 Serving을 하기 위해서는 requirements, Docker 등 여러가지 설정이 필요했지만 BentoML에서는 BentoService를 활용해 Prediction Service Class 생성을 할 수 있다. 이 클래스는 예측할때 사용하는 API를 위한 역할을 하게 된다.
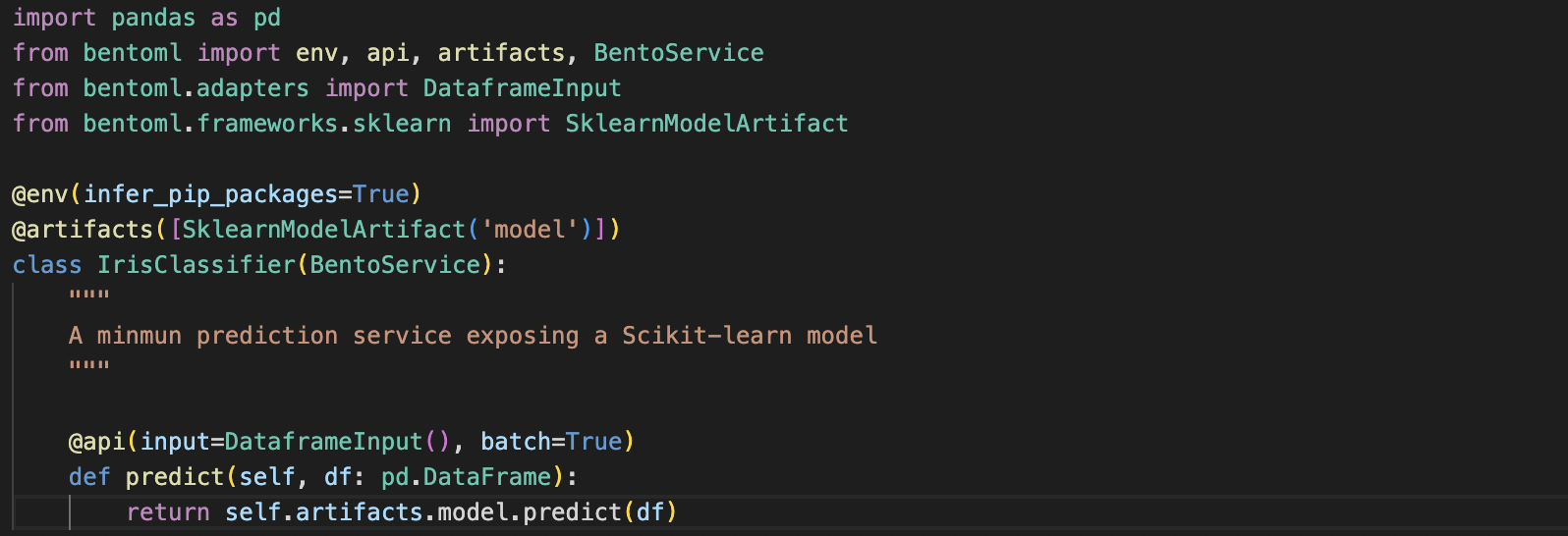
우선 위의 문법은 BentoML의 버전은 0.13.1의 문법이다.
@env는 파이썬 패키지, install script등 서비스에 필요한 의존성을 정의한다.
@artifacts는 서비스에서 사용할 Artifact를 정의할 수 있다.(Sklearn, Pytorch 등)
BentoService를 상속하면 해당 서비스를 Yatai에 저장하게 된다.
@api는 Input과 Output을 원하는 형태(DataFrame, Tensor, Json 등)으로 선택할 수 있으며 Doc String으로 Swagger에 들어갈 내용을 추가할 수 있다. @artifacts에 사용한 이름을 토대로 self.artifacts.model로 접근할 수 있다.
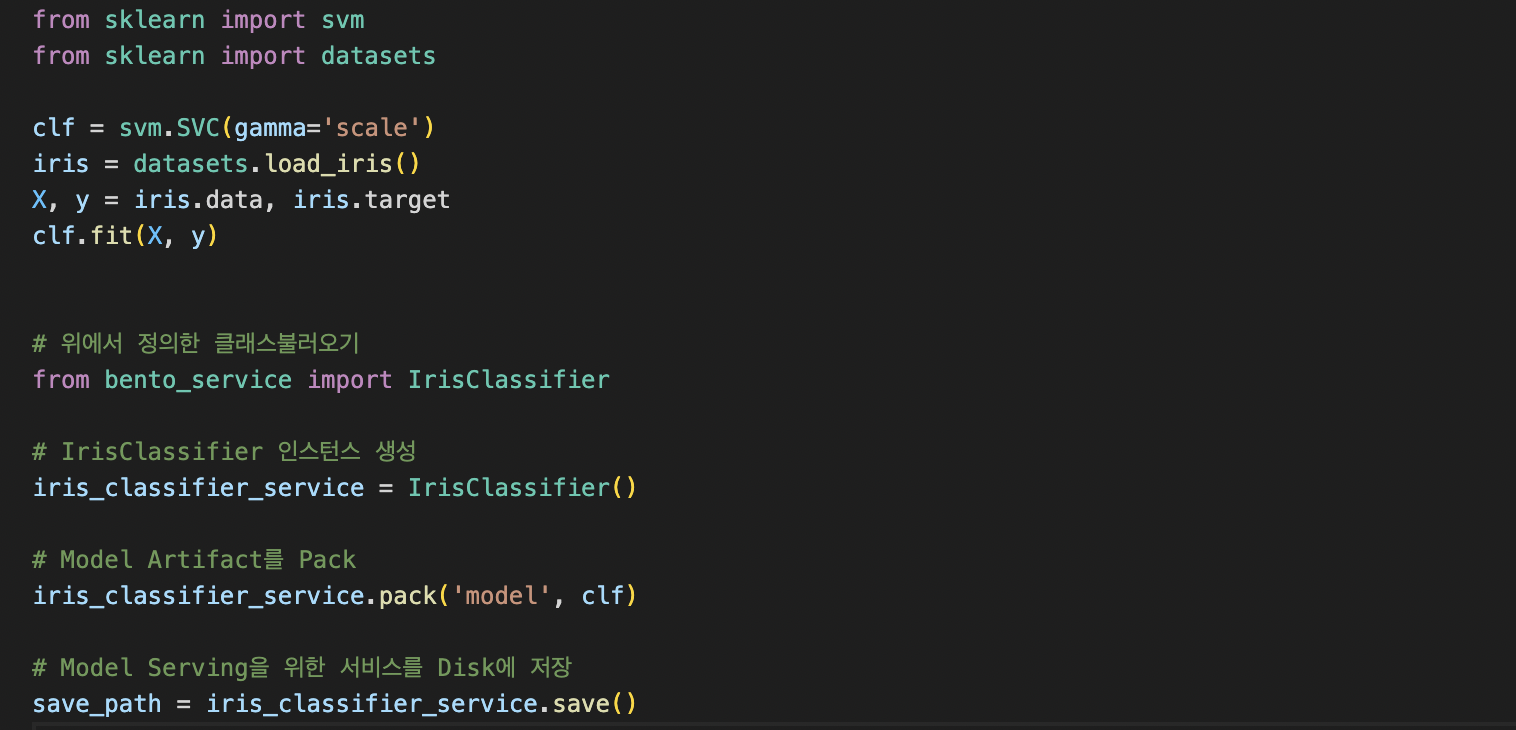
Model Artifact를 주입하여 BentoML Bundle이 나온것으로 볼 수 있다. BentoML Bundle은 Prediction Service를 실행할 때 필요한 모든 코드, 구성이 포함된 폴더, 모델 제공을 위한 바이너리이다.
해당 파일을 실행하게 되면 BentoService bundle이 저장된 장소가 출력이 된다. 해당 디렉토리의 구조는 아래와 같다.
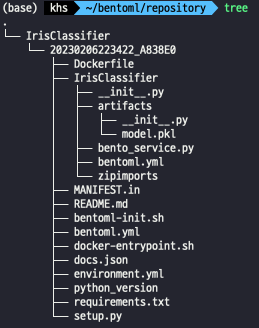
-
__init__.py : log정보와 cli를 만드는 작업을 한다.
-
bentoml.yml : 모델의 meta정보가 저장되고 있다.
-
Dockerfile도 자동으로 생성되며 설정을 가지고 설치한다.
bentoml list로 생성한 저장된 서비스를 확인할 수 있다.
bentoml serve IrisClassifier:latest를 사용하면 웹서버를 실행할 수 있다. default로 localhost:5000번으로 접근 할 수 있다.
bentoml yatai-service-start로 야타이를 실행시키면 3000번 포트에 실행된다.

bentoml containerize IrisClassifier:latest -t iris-classifier 명령어를 통해 Container Image를 빌드할 수 있다.
docker images로 이미지가 만들어진 것을 확인할 수 있다.
이와 같은 편리한 명령어로 FastAPI를 사용하지 않고 웹서버, 이미지 빌드 등을 할 수 있다.
BentoML Component
BentoService
bentoml.BentoService는 예측 서비스를 만들기 위한 베이스 클래스로 몇가지 데코레이터를 사용할 수 있다.

@bentoml.artifacts : 여러 머신러닝 모델을 포함할 수 있다.
@bentoml.api : Input/Output 정의

Service Environment
파이썬 관련 환경, Docker등을 설정할 수 있다.
-
@bentoml.env(infer_pip_packages=True) : import를 기반으로 필요한 라이브러리 추론
-
requirements_txt_file을 명시할 수도 있음

-
pip_packages=[]를 사용해 버전을 명시할 수 있음
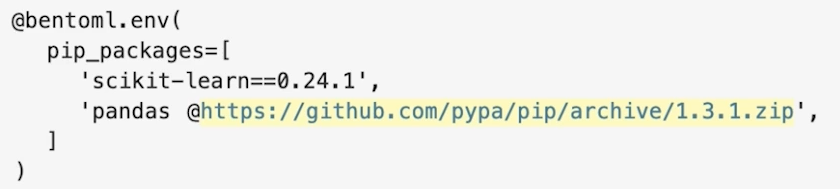
- docker_base_image를 사용해 Base Image를 지정할 수 있음

- setup_sh를 지정해 Docker Build과정을 커스텀 할 수 있음

Model Artifact
-
@bentoml.artifacts : 사용자가 만든 모델을 저장해 pretrain model을 읽어 Serialization, Deserialization
-
여러 모델을 같이 저장할 수 있음
-
A모델의 예측 결과를 B모델의 Input으로 사용할 경우
-
보통 하나의 서비스 당 하나의 모델을 권장
- 위와 같이 많은 라이브러리들을 지원하고 있다.
Model Artifact Metadata
-
해당 모델의 Metadata(Metric, 사용한 데이터셋, 생성한 사람, Static 정보 등)
-
Pack에서 metadata 인자에 넘겨주면 메타데이터로 저장할 수 있다.
-
메타데이터는 Immutable하다.
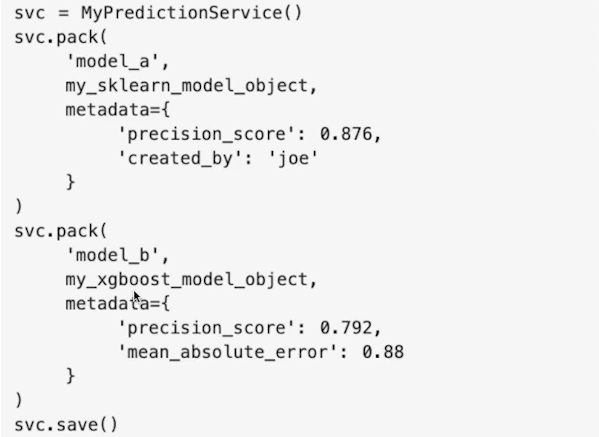
- 메타데이터에 접근하고 싶은 경우
bentoml get model:version을 사용하거나 bentoml serve한 후는 /metadata로 접근할 수 있다.
Model Management & Yatai
-
BentoService의 save함수는 Bento Bundle을 저장하는 것으로
bentoml list로 저장된 Bundle을 확인할 수 있으며bentoml get bento-service로 특정 모델 정보만 가져올 수 있다. -
YataiService는 모델 저장 및 배포를 처리하는 컴포넌트로
bentoml yatai-service-start로 실행할 수 있다.
API Function and Adapters
-
BentoService API는 클라이언트가 예측 서비스에 접근하기 위한 End Point를 생성한다.
-
Adapter는 Input/Output을 추상화하여 중간 부분을 연결하는 Layer이다. 예를들어 csv 파일 형식으로 예측 요청할 경우 DataframeInput을 사용하고 있었으면 내부적으로 pandas.DataFrame객체로 변환하고 API 함수에 전달한다.
Model Serving
BentoService가 벤또로 저장되면 여러 방법으로 배포할 수 있다.
-
Online Serving : 클라이언트가 REST API End point로 근 실시간 예측 요청
-
Offline Batch Serving : 예측을 계산한 후 Storage에 저장
-
Edge Serving : 모바일, IoT에 배포
Retrieving BentoServices
학습한 모델을 저장한 후 Artifact bundle을 찾을 수 있다.
WEB UI
@bentoml.web_static_content를 사용하면 웹 프론트엔드에 추가할 수 있다.
