GPT-2
GPT-2는 모델구조적인 측면에서는 GPT-1과 크게 다르지 않다. 다만 모델사이즈를 키웠고 질적으로 뛰어난 대규모(40GB) 데이터를 사용했다. 마지막으로 GPT-2는 zero shot의 잠재적인 능력도 보여주었다.

GPT-2는 위의 이미지 처럼 놀라울 정도의 퀄리티를 가진 생성능력을 갖고 있다.
기존의 딥러닝 모델의 분류 task와 한 문장에 대한 대답을 생성하는 task는 서로 상이한 구조를 가진 모델로 구분되었다. 왜냐하면 task마다 output의 형태가 다르기 때문이었다. 하지만 이 논문의 핵심은 대부분의 자연처 tasks는 QA형식으로 해결이 가능하다는 점이다. 예를 들어 분류 테스트에서 분류하고자 하는 문장 + "이 문장이 긍정일까 부정일까?"라는 하나의 sequence를 만들고 여기에 Answer를 생성하여 분류를 할 수 있다. 요약도 마찬가지로 요약하고자 하는 문서 + "위 문서를 요약하면 뭘까?"라는 식의 형태로 바꿔 질의응답 형태로 통합할 수 있다는 가능성을 보여준 연구사례이다.
Datasets
- Reddits : 소셜 플랫폼
- 문장을 생성하기에 적합한 구조를 가진 데이터(글을 올리면 댓글을 다는 플랫폼)
- 3개 이상의 추천을 받은 글
- 어떤 질문에 대한 대답으로 link가 있고 그 대답이 추천이 많은 경우 해당 링크의 글을 데이터로 사용
Preprocess
- Byte Pair encoding (BPE) 사용
GPT-2 model
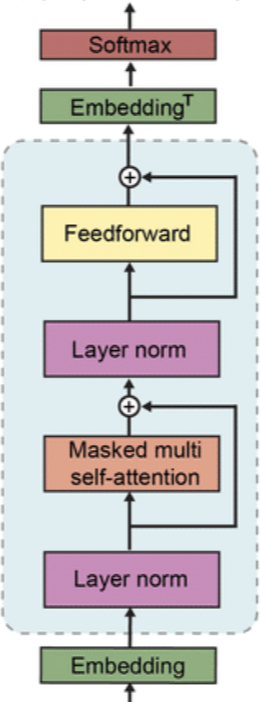
-
기존 transformer의 Layer normalization 위치의 변화를 주었다.
-
residual layer의 깊이 에 따라 로 가중치를 초기화해서 사용했다. 이는 깊은 layer의 하는 역할을 줄여주는 방향으로 구성했다.
GPT-2의 흥미로운 실험 중 하나는 conversation question answering dataset(CoQA)을 사용한 QA task에서 기존의 방식은 라벨링된 데이터를 fine-tuning하여 사용하지만 GPT-2는 fine-tuning을 거치지 않고 바로 정답을 예측했을때 성능은 약 55%의 F-1 score가 나왔으며 zero shot의 가능성을 제시했다.
요약 task에서도 fine-tuning없이 zero shot setting으로 실험을 했다. 대용량 데이터로 학습한 GPT-2의 특성상 (TL;DR: Too long, didn't read)가 붙어 있는 데이터도 상당히 많았을 것이기 때문에 요약하려는 문장 뒤에 TL;DR을 붙임으로 데이터를 사용하지 않고도 요약을 수행할 수 있게 된다.
번역도 마찬가지다. in French, in English, in Korea 등의 특정 구절을 붙여줌으로 번역을 수행할 수 있다.
GPT-3
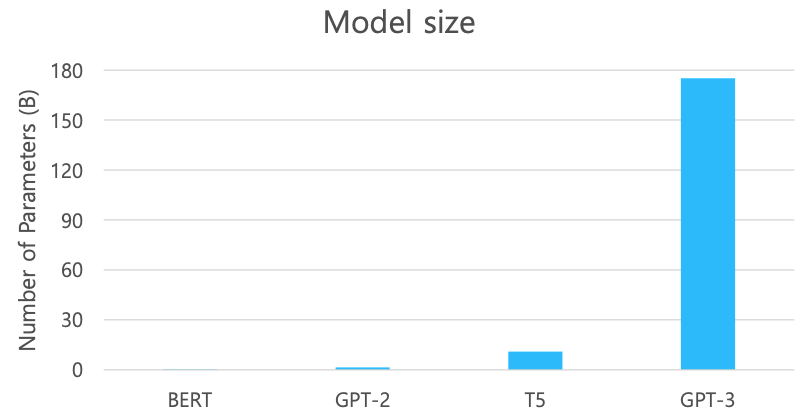
GPT-3도 구조적으로의 차이는 크게 없지만 모델의 사이즈가 비교할수 없을 정도로 커졌으며 데이터 또한 크게 증가했다.
Language Models are Few-Shot Learners

-
Prompt: the prefix given to the model
-
Zero-shot: Predict the answer given only a natural language description of the task
-
One-shot: See a single example of the task in addition to the task description
-
Few-shot: See a few eamples of the task
ALBERT
ALBERT는 A Lite BERT for Self-supervied Learning of Language Representations라는 이름 자체로 경량화된 BERT모델을 의미한다. 앞서 소개한 모델들은 대규모의 메모리를 요구하는 형태로 발전해왔다. 이를 위해서는 많은 메모리, 대용량 데이터, 긴 학습시간을 요구한다. 하지만 ALBERT는 성능의 큰 하락없이 모델사이즈를 줄이고 학습시간을 짧게 만든 모델이다. 추가적으로 새로운 문장의 레벨의 pre-train task를 제안하였다.
Factorized Embedding Parameterization
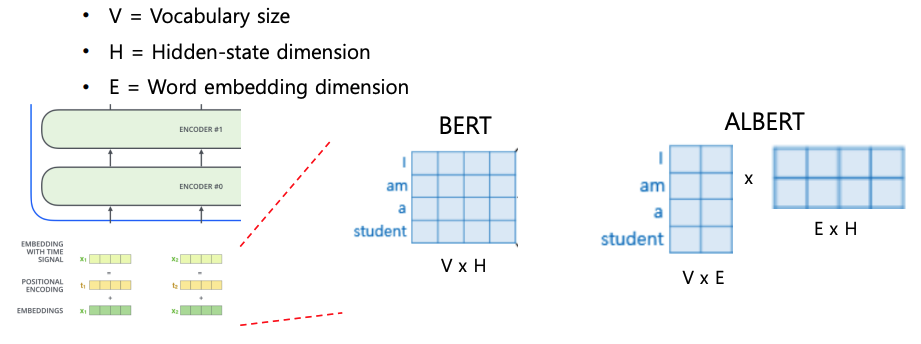
self-attention block은 residual connection의 계산을 해야하기 때문에 차원의 유지가 필요하다. 차원이 너무 작으면 정보를 담기에 부족하고 반대로 너무 크다면 모델 사이즈가 커지며 그에 따른 큰 연산량을 요구하게 된다. ALBERT에서는 이 문제를 해결하기 위한 방법으로 Factorized Embedding parametrization을 제시하는데 기존의 word embedding을 를 같는 차원으로 구성했다면 훨씬 작은 차원의 로 구성하고 차원을 유지시켜 주기 위한 를 갖는 하나의 layer를 추가하는 방법을 사용한다. 위의 그림에서는 큰 차이가 없어 보이지만 V=500, H=100이라면 기존읜 50,000개의 파라미터가 필요했다면 V=500, E=15, H=100로 이 방법을 적용한다면 9000개의 파라미터로 줄어드는 효과를 볼 수 있다.
Cross-layer Paramter Sharing
self-attention의 학습가능한 파라미터는 이 존재한다. 이렇게 구성된 파라미터가 head 수()만큼 존재하고 이렇게 구성된 하나의 블럭이 서로 공유되지 않은 상태로 여러개로 쌓여있는 구조이다.
ALBERT는 이 파마리터들을 서로 공유할때의 성능에 대한 실험도 진행하였으며 Shared-FFN은 Feed-forward network를 의미하고, Shared-attention은 를 의미한다.
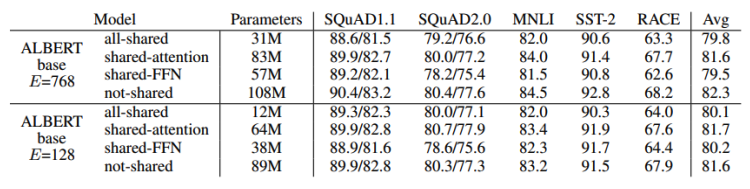
결과를 보다시피 파라미터들을 공유하여도 미미한 성능하락을 보였으며 ALBERT는 이런 특징으로 경량화할 수 있었다.
Sentence Order Prediction

기존 BERT의 사전학습법은 MLM과 NSP가 있었다. BERT이후의 후속 연구에서 NSP task는 실효성이 떨어진다는 지적이 있었다. ALBERT에서도 실효성이 떨어지는 NSP task를 조금 더 유의미한 task로 바꾸게 되었다. 이 방법은 언제나 연속된 두 문장을 선택하게 되고 문장의 순서가 제대로 되었는지 역방향인지를 구분하는 binary classification으로 변형을 하였고 sentence order prediction라고 부른다.
기존의 BERT의 NSP는 negative sampling을 할 때 서로 다른 문서에서 문장을 뽑아 데이터를 구성하였는데 이렇게 되면 두 문장관의 연관성이 현저히 낮아질 수 있어서 모델 자체가 문장을 이해하는데 도움을 주기 어렵다. 왜냐하면 서로 다른 문서에서 뽑았기 때문에 문장 자체가 너무 달라 고차원으로 접근하기 보다 단순히 겹치는 단어가 적어 다음 문장이 아니라고 예측하거나 겹치는 단어가 너무 많아 다음 문장으로 예측할 수 있기 때문이다. 쉽게 말해 문제가 너무 쉬워 도움이 되지 않는다는 이야기이다.
SOP에서는 여전히 인접 문장을 사용해 단어의 overlap관점에서 negative sampling의 차이가 없기 때문에 조금 더 고차원적인 접근이 가능하다고 한다.
ELECTRA
- Efficiently Learning an Encoder that Classifies Token Replacements Accurately
BERT의 MLM GPT의 전통적인 AR방식 보다 한발 더 나아가 GAN의 아이디어에서 착안하여 Generator와 Discriminator를 두가지 모델을 사용한다.
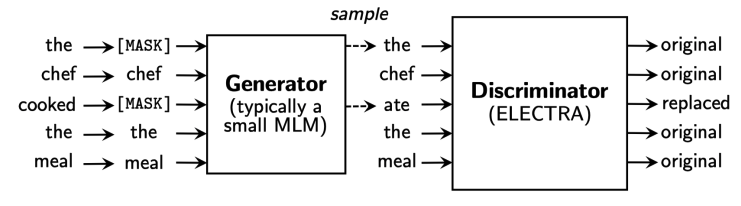
Generator는 BERT모델로 생각할 수 있고 Discriminator는 [MASK] 토큰을 복원한 sequence를 입력으로 받게 되며 이 모델에서는 각 토큰 별로 binary classification을 수행하게 된다.
Discriminator도 마찬가지로 self-attention block으로 이루어져 있다.
우와 같은 방법으로 학습시켜 최종적으로 Discriminator network를 pre-trained model로 사용하게 된다.
Light-weight Models
기존의 모델들은 block을 많이 쌓으면서 성능을 향상시켰다. 반대로 실제 현업에 적용하기엔 무리가 있었는데 성능을 유지하면서도 모델을 경량화하는 방향의 연구가 활발히 지속되었다.
DistillBERT
Huggingface가 발표한 연구이다. 기본적으로 teacher model과 student model모델이 존재한다. 경량화 된 student model이 teacher model을 경향을 배우도록 학습이 진행된다.
기존 MLM 학습뿐만 아니라 추가적으로 teacher model의 softmax output을 student model ground truth로 사용하여 teacher model을 모방하도록 학습이 진행된다.
TinyBERT
DistillBERT와 마찬가지로 teacher model, student model이 존재하고 DistillBERT의 학습방식 뿐만 아니라 embedding layer와 self-attention block의 파라미터들 hidden vector까지 모방할 수 있도록 학습이 진행된다.
중간 결과물의 hidden vector를 사용해 MSE loss로 학습하게 된다. 하지만 teacher와 student간의 벡터의 차원이 다를 수 있기 때문에 teacher벡터를 작은 차원으로 변환할 수 있는 layer를 하나 두어 이것도 학습하도록 구조화하였다.
TinyBERT의 핵심은 최종결과물 뿐만 아니라 중간결과물도 Teacher모델을 모방하도록 학습하는것이다.
Fusing Knowledge Graph into Language Model
문장 1 : 꽃을 심기 위해 땅을 팠다.
문장 2 : 집을 짓기 위해 땅을 팠다.
두 문장에는 어떤 도구로 땅을 팠는지에 대한 정보는 없다. 사람이라면 꽃을 심기 위해서라면 모종삽, 집을 짓기 위해서라면 중장비 등을 떠올릴 수 있지만 BERT는 주어진 문장에서 정보를 추출하는 것은 잘할 수 있지만 외부지식이 필요로하는 경우는 취약하다.
이런 부분을 외부지식이나 관계 등을 Knowledge Graph로써 정의하고 BERT와 적절히 결합하여 사용할 수 있을지에 대한 연구이다.
