Recent Trends
-
Transformer 및 self-attention block은 범용적인 sequence encoder, decoder로서 자연어처리의 다양한 분야에서 사용된다.
-
Transformer에서 제시된 self-attention block을 deep하게 쌓아 self-supervised learning을 하여 transfer leaning을 통해 다양한 NLP tasks에서 사용된다.
-
추천, 신약개발 및 영상처리에까지 사용도가 확장되고 있다.
-
그러나 자연어생성에서는 greedy decoding의 한계점을 돌파하진 못했다.
GPT-1
Open-AI에서 발표한 모델로 현재는 GPT-2, GPT-3까지 나왔으며 자연어 생성분야에 놀라운 성능을 보여주고 있다.
-
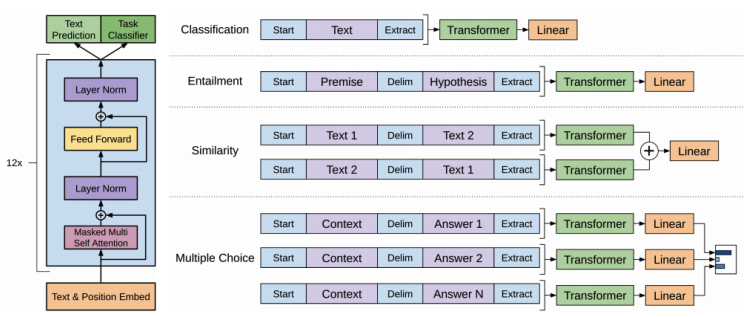
GPT-1은 Transforemr의 decoder block을 총 12개를 쌓은 구조를 가지고 있다.
-
Text Prediction은 첫단어부터 순차적으로 단어를 예측도록 하는 task이다.
-
GPT-1은 다수의 문장에서도 동작할 수 있도록 여러가지 framework를 제안했다.
-
GPT-1의 Text Prediction 별도의 라벨이 필요없는 데이터를 통해 Pre-Training이 진행되며 unsupervised-learning이라고 한다.
-
GPT-1을 target task(downstream task)에 전이학습을 하게 되는데 이 과정은 대용량 데이터로 얻은 지식을 비교적 적은 target task(supervised-learning)로 전이하게 되는 양상으로 이루어진다.
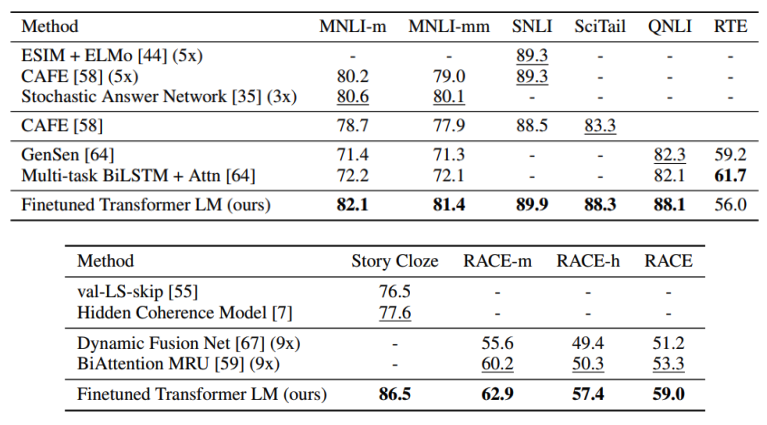
소량의 target data로만 학습한 모델의 결과 보다 pre-trained된 모델을 사용하여 target data로 학습시킨 결과가 훨씬 우수한것을 알 수 있다.
BERT
BERT는 Transformer의 encoder구조를 가지며 GPT처럼 Language Modeling의 방법을 사용해 문장의 내용을 맞추도록 pre training되었다. 하지만 BERT는 아래와 같이 특별한 방법을 사용한다.
Pre-training Tasks in BERT
- Motivation
- 언어모델은 오직 이전의 문맥만으로 다음 단어를 예측해야 되지만 실제로 양쪽의 정보들을 전부 사용해서 예측했을때 훨씬 높은 지식이 학습될 수 있다.
Masked Language Model(MLM)

BERT는 한 문장에서 특정 비율()만큼 [MASK]토큰으로 치환하고 실제 단어로 예측하도록 pre-training을 수행한다.
여기서 는 우리가 적절하게 선택해야하는 파라미터로 논문에서는 15%일때 성능이 가장 좋았다고 하는데 만일 값이 증가한다면 마스크 토큰을 맞추기에 정보가 부족하고 값이 낮다면 계산 효율성의 문제가 발생한다.
BERT는 15%를 전부 [MASK]토큰으로 치환했을때 부작용이 생길 수 있다고 한다. 실제 target task에서는 [MASK]는 등장을 하지 않는 괴리감이 성능을 올리는데 문제를 일으킬 수 있기 때문에 비율을 아래와 같이 조정한다.
-
15%의 비율의 단어를 선택한다.
-
그 중 80%는 [MASK]토큰으로 치환한다.
-
10%는 랜덤 단어로 치환한다.
-
나머지 10%는 원래의 단어를 유지한다.
-
Next Sentence Prediction(NSP)
BERT도 GPT와 마찬가지로 문장 수준의 task에 대비하기 위한 추가적인 사전학습 방법을 제안했다.

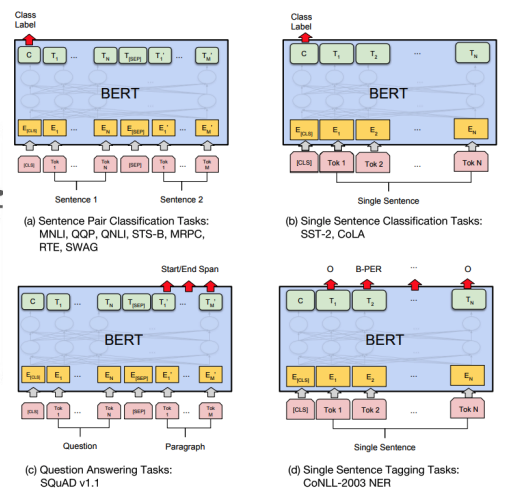
문장 또는 다수의 문장의 예측 task를 담당하는 토큰으로 [CLS]를 사용하고 문장과 문장사이 혹은 문장의 끝을 나타내는 [SEP]토큰을 사용하여 구성한다.
GPT에서의 문장의 맨 마지막에 위치한 Extract토큰이 BERT에서는 문장의 맨 앞에 CLS토큰으로 사용된다.
NSP도 별도의 label이 필요한 task가 아닌 입력 데이터만으로 할 수 있는 task이며 연속되는 두 문장이 연속된 문장인지 아닌지를 분류하는 task이다. binary classification은 [CLS]토큰의 벡터로 분류하게 된다.
BERT summary
-
Model Architecture
-
BERT BASE: L = 12, H = 768, A(head) = 12
-
BERT LARGE: L = 24, H = 1024, A(head) = 16
-
-
Input Representation
-
WordPiece embeddings (30,000 WordPiece)
-
Learned positional embedding
- Transformer의 positional encoding방식이 아니라 이 matrix도 학습하는 파라미터로 선택
-
[CLS] - Classification embedding
-
Packed sentence embedding [SEP]
-
Segment Embedding
- 문장 레벨의 position embedding으로서 사용된다.
- 같은 문장은 같은 값을 갖는다.
-
-
Pre-training Tasks
-
Masked LM
-
Next Sentence Prediction
-
BERT downstream tasks
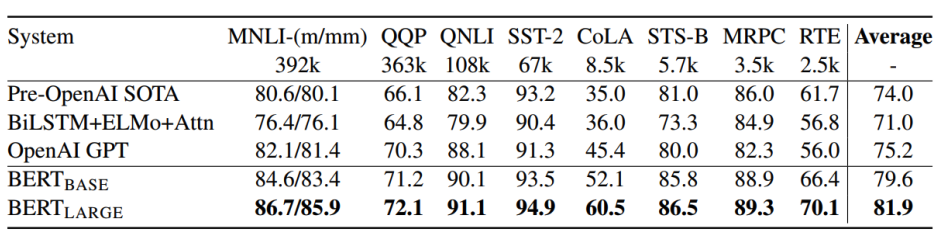
위는 GLUE Benchmark에 대한 결과이다. BERT는 기존의 모델들 보다 높은 성능을 보여준다.
BERT vs. GPT-1
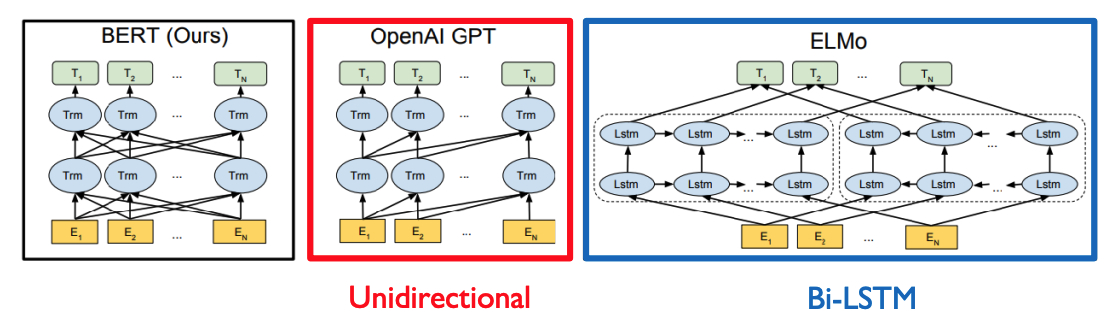
GPT같은 경우 바로 다음 단어를 예측해야하는 task를 수행해야 하기 때문에 그 다음 단어에 접근을 허용하면 안된다. 따라서 GPT 같은 경우 Masked Self-Attention을 사용하게 된다.
BERT는 Masked된 단어를 예측하는 형태이기 때문에 Self-Attention을 사용하게 된다.
-
Training-data size
- GPT-1 : BookCorpus(800M words)
- BERT : BoockCorpus + Wikipedia(2,500M words)
-
Training special tokens during training
- BERT : [SEP], [CLS], segment embedding
-
Batch size
- GPT-1 : 32,000 words
- BERT : 128,000 words
-
Task-specific fine-tuning
- GPT-1 : 여러 downstream task에 lr를 (5e-5)로 고정
- BERT : task별로 optimize 수행
Machine Reading Comprehension(MRC), Qestion Answering
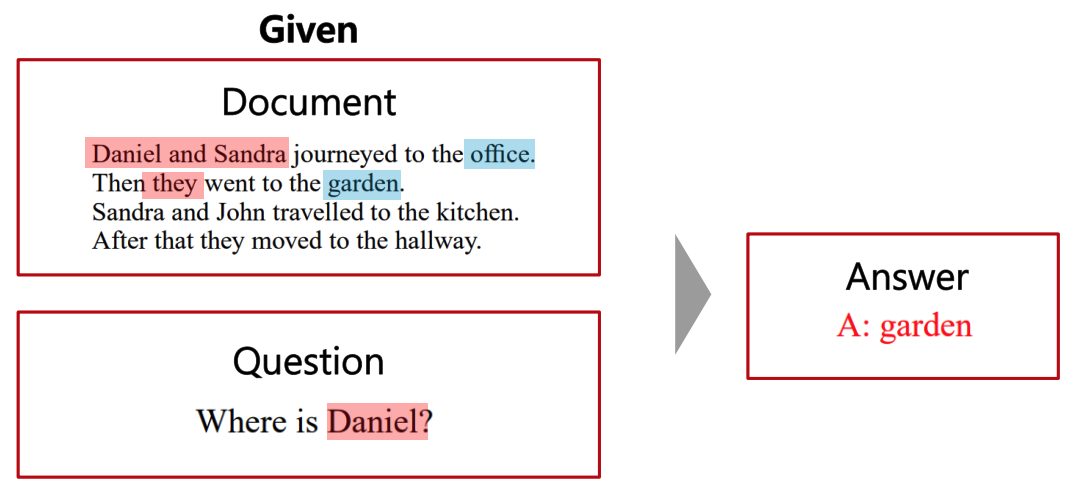
자연어처리 대표적인 Task로 MRC를 소개한다.
MRC는 QA의 일종으로 보지만 질문만 주고 답을 예측하는 task가 아니라 독해에 기반한 QA라는 점에서 차이점이 있다.
위의 단순한 예시뿐만 아니라 스탠포드에서 만든 벤치마크 데이터셋인 SQuAD 존재한다. SQuAD는 1.1과 2.0버전이 존재한다. SQuAD의 공식 홈페이지의 리더보를 살펴보면 BERT가 포함된 모델이 상위권에 위치한 것을 확인할 수 있다.
실제 학습은 BERT의 입력으로 지문과 질문을 [SEP]토큰으로 하나의 sequence로 만들어 사용한다. 그럼 지문의 각 토큰마다 인코딩 벡터를 얻을 수 있다. 이 벡터를 통해 정답이 있을만한 위치를 예측하게 된다.
예를들어 지문의 토큰이 100개라면 100개의 스칼라값을 얻을 수 있으며 이 100개의 값에 softmax를 취해 ground truth의 시작 토큰과 매치가 되는 위치의 확률이 가장 커지도록 학습하게 된다.
그 다음 끝나는 시점도 예측해야 하기 때문에 똑같은 방식으로 end point를 찾도록 학습하게 된다.
SQuAD 2.0은 질문의 대한 답을 찾을 수 없는 데이터 셋도 추가된 버전이다. 따라서 먼저 질문에 대한 답이 있는지 없는지 판단하고 있다면 1.1버전에서와 같이 학습하게 된다. 이 경우 CLS토큰을 활용해 질문에 대한 답이 지문에 있는지 binary classification을 하게 된다.
