Basics of Recurrent Nueral Networks
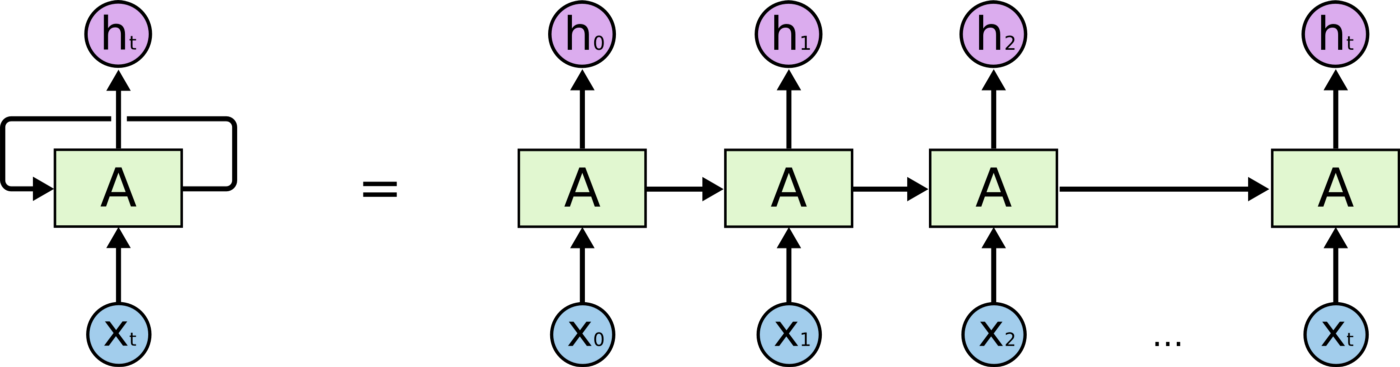 왼쪽 : rolled diagram / 오른쪽 : unrolled diagram
왼쪽 : rolled diagram / 오른쪽 : unrolled diagram
RNN은 기본적으로 Sequence데이터가 주어진 상황에서 각 time별 인풋인 와 이전 time에서 계산한 을 입력으로 받아 현재 time step에서의 를 출력하는 구조이다.
위의 그림에서 예상할 수 있듯이 RNN이 재귀적으로 호출되는 구조를 가진다.
hidden state인 를 계산하기 위해서는 아래와 같은 파라미터가 필요하다.
-
: 이전 time step의 hidden state
-
: 현재 time step의 입력
-
: RNN function
- : 최종 결과값을 예측해야할 때 를 이용한 아웃풋
- 예를들어, 각 step마다 아웃풋이 필요한 경우(품사 태깅)는 매번 값이 필요하고, 문장 분류와 같은 경우 마지막 step에서만 값이 필요하다.
Types of RNNs
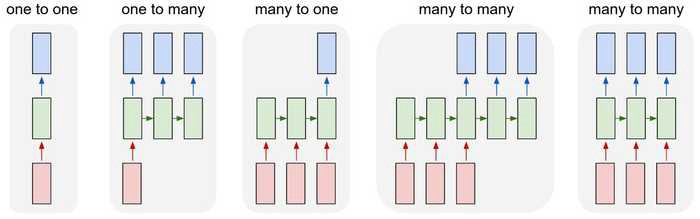
One to one
- 입력과 출력 데이터의 time step이 하나인 경우 일반적인 모델의 구조이며 sequence 데이터가 아니다.
One to many
-
입력이 하나의 time step으로 이루어지고 출력은 여러 time step으로 이루어지는 경우를 말한다.
-
예를들어, image captioning과 같이 입력으로 사진 하나가 주어지고 사진에 따른 설명을 순차적(time)으로 출력하는 경우
-
이와 같은 경우 처음 time step을 제외한 나머지 step의 입력은 같은 차원이지만 0을 가진 형태로 주어진다.
many to one
- 감정분석과 같이 입력이 step마다 주어지고 마지막 step에서만 출력이 이루어지는 경우이다.
many to many (1)
- 기계번역과 같이 입력값을 전부 읽은 후 입력의 마지막 step 이후로 출력이 이루어진다.
many to many (2)
- 입력이 주어질때마다 각 time마다 출력이 이루어지는 경우이며 POS 태깅, video classification on frame level과 같은 task에 사용된다.
Character-level Language Model
RNN을 이용한 Language model (many to many task)
-
Example of training sequence "hello"
- Vocab : [h, e, l, o]
- training sequence: "hello"
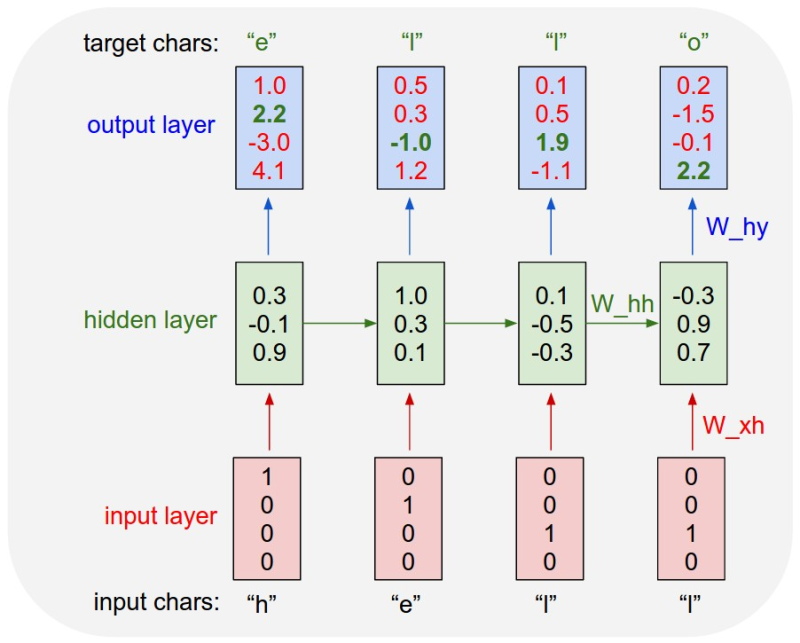
위의 예시는 하나의 단어지만 긴 문장 또는 문단 단위의 데이터도 학습할 수 있다. 이런 경우에는 공백이나 쉼표, 줄바꿈도 하나의 특수문자로써 학습시켜 의미있는 출력을 기대할 수 있다.
주식예측에도 사용할 수 있는데 이전 까지의 데이터를 통해 다음날의 주식값을 예측한다고 했을때 예측한 값도 다시 하나의 데이터로 사용하면 먼 미래도 예측이 가능하다.
Vanishing/Exploding
RNN의 구조상 time step이 길어질수록 의 거듭제곱의 형태로 진행되게 된다. 이 형태는 공비수열과 같은 형태로 공비가 1보다 작을 경우는 0에 가까워지고 1보다 크게 되면 발산하게 된다.
example
h3에서부터 h1까지의 역전파를 생각해 본다면 h3를 h1에 대한 편미분으로 생각할 수 있는데 결국 어떠한 tanh의 기울기에 의 값인 3이 계속 곱해지는 형태가 된다. 이 상태에서 exploding현상이 발생할 수 있다.
만약 가 0.1과 같은 값이라면 vanishing현상이 일어날 수 있다.
이런한 문제로 vanila RNN은 잘 사용되지 않으며 다음시간에 배울 LSTM, GRU가 좋은 성능을 나타내고 어떻게 문제를 해결했는지 알아보자.
