Multi Head Attention
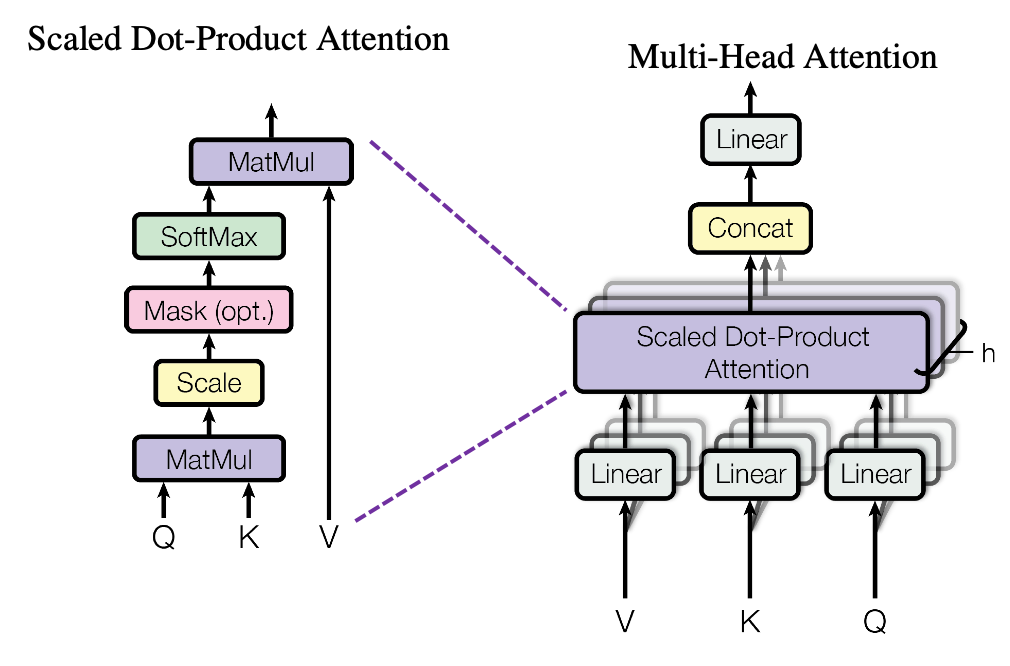
앞서 배운 Attention을 하나의 head라고 표현을 하는데 Transformer에는 이런 head연산을 만큼 수행하여 개의 encoding vector를 concatenation해서 사용한다.
Multi Head의 이유
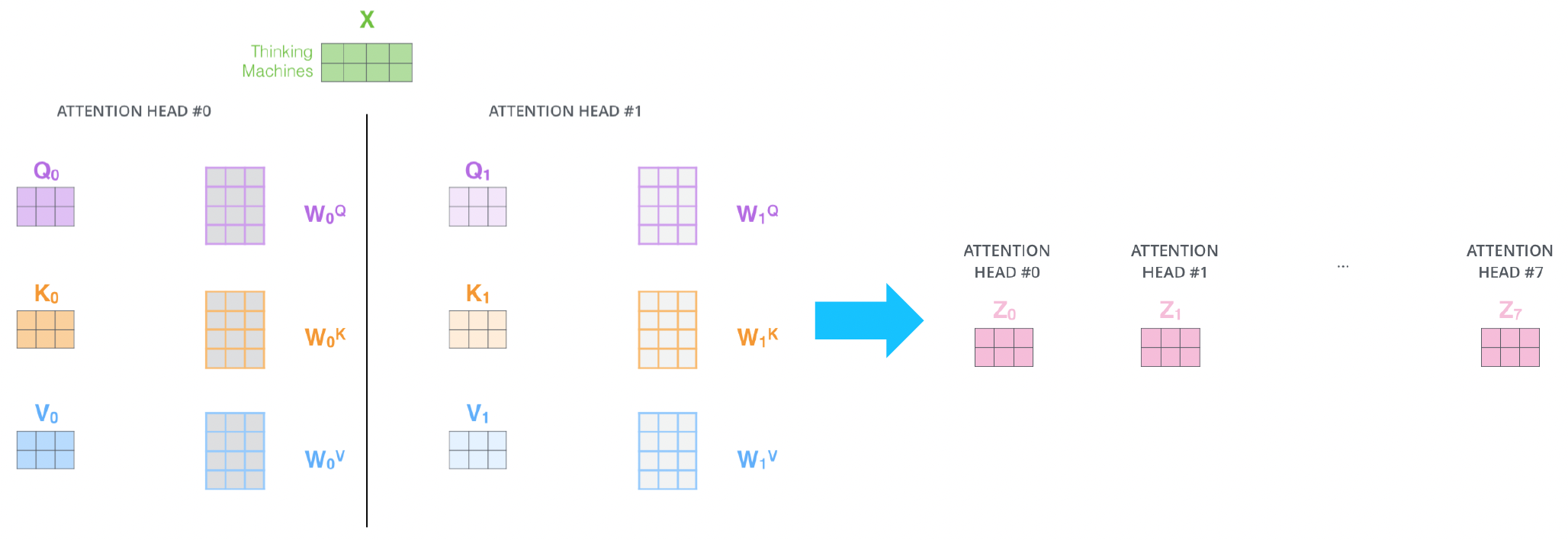
어떤 동일한 sequence가 주어졌을때에도 서로 다른 측면에서 정보를 추출해야할 수 있다. 예를들어 i went to the school. i studied hard. i came back home and took the rest.
위와 같은 문장이 존재할때 query가 I라 한다면 행동적인 관점에서 went, studied, came back home, took the rest과 같은 정보도 필요하고 다른 장소라는 측면에서는 school, home과 같은 정보가 필요하다. 따라서 각각의 head는 여러 정보들은 상호보완적으로 뽑는 역할을 하게 된다.

는 우리가 조절할 수 있는 파라미터로 봤을때 Self-Attention의 계산량은 기존 RNN보다 더 많은 계산량을 필요로 하게 된다. 하지만 병렬처리가 가능하다는 관점에서 본다면 모든 계산이 한번에 이루어질 수 있고 RNN은 재귀적으로 정보를 가져와야 하기 때문에 그렇지 못하다. 마지막 시간복잡도는 long term depentency관점에서 self-attention은 아무리 멀더라도 하나의 내적으로 정보를 가져올 수 있지만 RNN은 거리만큼의 time step의 이동이 필요하기 때문에 계산효율성에서 좋지 않다고 볼 수 있다.
Block-Based Model
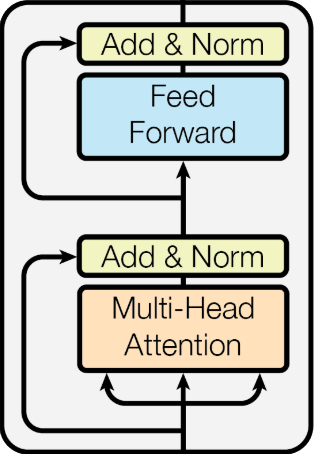
Transformer에서는 Multi Head Attention을 핵심모듈로하여 추가적인 후처리와 함께 하나의 Block으로 처리된다.
Residual connection
residual connection은 CV쪽에서 깊은층의 모델을 구성할때 gradient vanishing문제를 해결하여 학습을 안정화시켜 더 깊게 층을 쌓게 해주는 방법이다.
Multi Head Attention의 입력벡터와 그의 출력벡터를 더해주는 연산을 하게 되는데 이 연산을 가능하게 하기 위해 앞서 Multi Head Attention에서의 는 concatenation으로 증가한 차원을 입력벡터의 차원과 상응하게끔 변환해주는 역할을 한다.
Layer Normalization
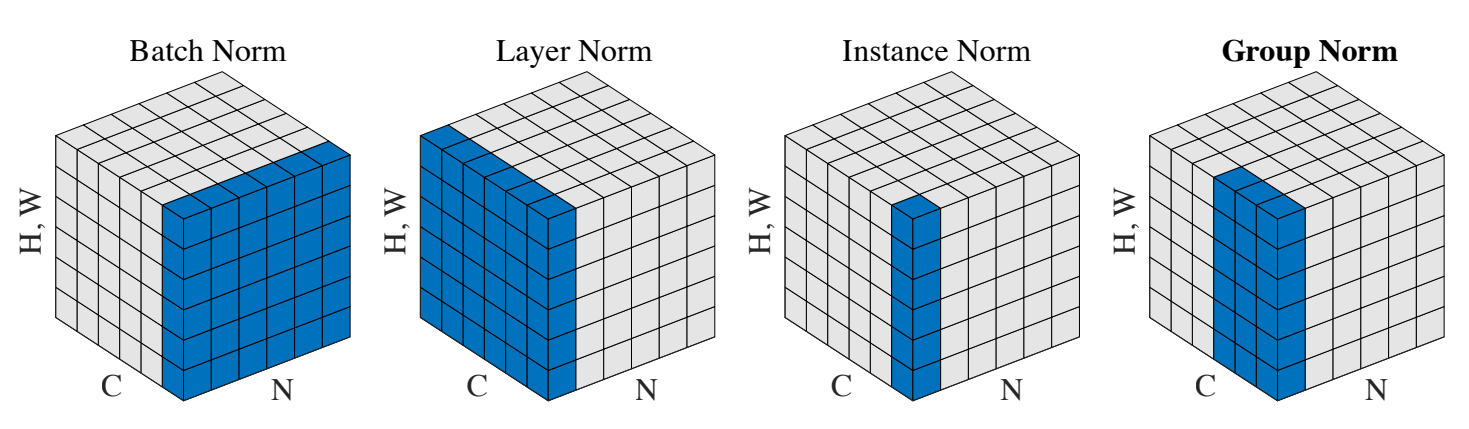
여러가지 Norm의 이유는 주어진 sample들의 대해서 평균을 0 분산을 1로 바꿔준 후 우리가 원하는 평균과 분산을 주입할 수 있게끔 한다.
- Batch Norm
Batch size만큼 데이터를 넣어준다면 특정 노드의 값에 대해서 평균이 0, 분산이 1인 데이터로 변환시켜준다.
예를들어, 3개의 batch가 특정노드에서 3, 5, -2의 값을 갖게 된다면 평균이 2, 표준편차가 이 된다.
위와 같이 변환시켜 표준화 된 값으로 바꿔줄 수 있다. 그 다음으로 Affine transformation의 연산을 수행하게 되는데 의 Affine transformation이라면 평균은 3, 분산은 4를 갖도록 변환시켜줄 수 있다.
- Layer Norm
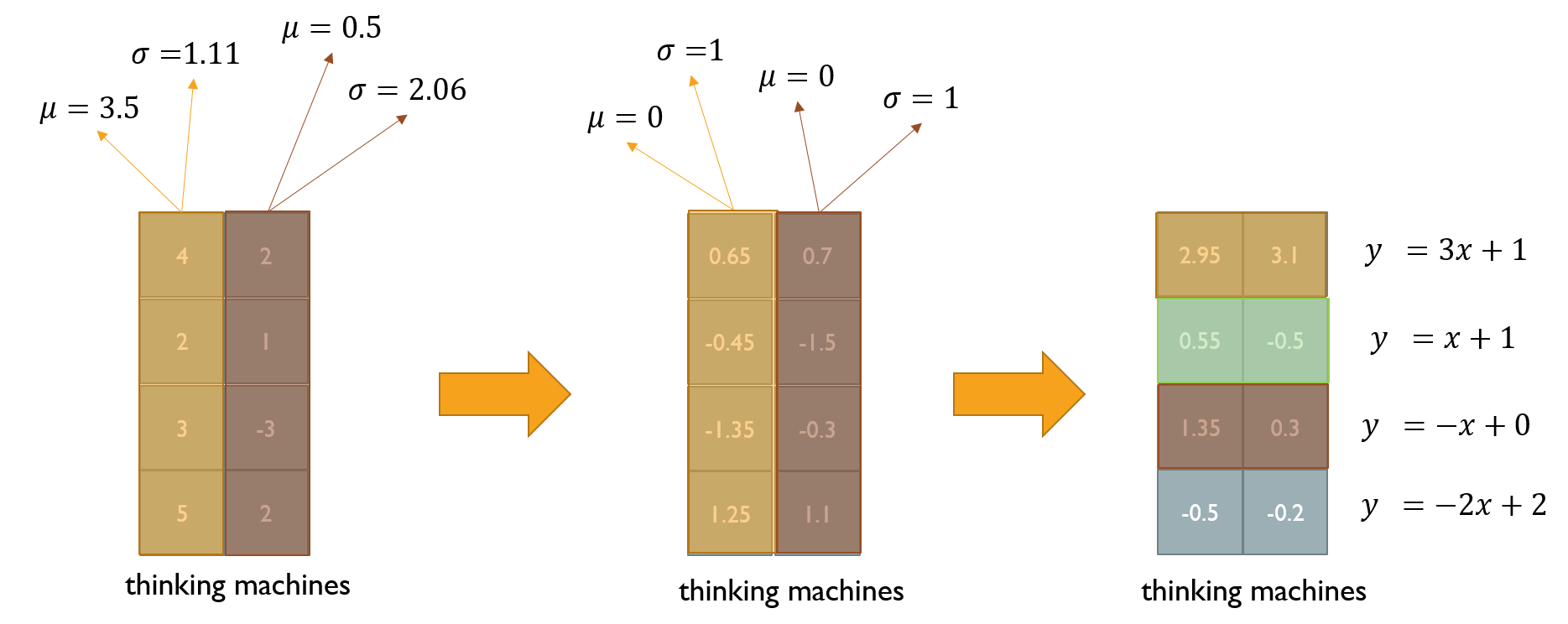
Layer Norm은 Batch와 상관 없이 특정 벡터에서의 평균과 분산을 구해 표준화하는 방법이다.
Positional encoding
지금까지 살펴본 Transformer구조는 순서의 정보를 반영하지 못했다는 단점이 존재한다. 이를 해결하기 위해 positional encoding을 사용하게 된다.
예를들어 , I go home의 sequence에서 I의 vector가 의 값을 갖고 있다고 가정하면 첫번째에 등장했다는 것의 차이를 두기 위해 특정 스칼라를 첫번째 차원에 더하는 방법을 사용할 수있다. 특정 값을 1000이라고 한다면 으로 바뀔 것이다. 반대로 I가 세번째에 등장했다면 로 바꿔준다면 같은 단어라 할지라도 sequence의 순서를 고려할 수 있게 된다.
여기서 핵심 아이디어는 각 순서를 특정지을 수 있는 특정한 상수벡터를더해준다는 것이고 이게 positional encoding이다.
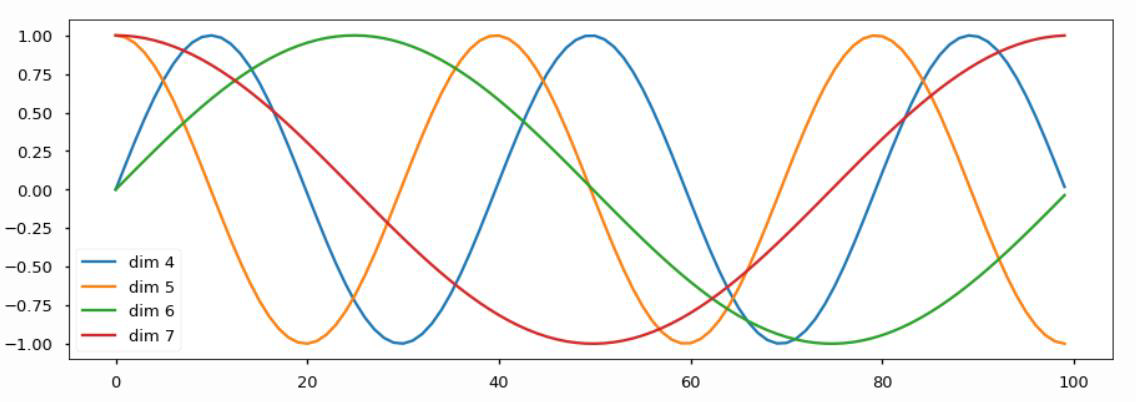
Transformer에서는 이 값으로 과 같은 주기함수를 선택하고 주기를 각각 다른 값을 사용해 순서를 고려하게 된다.
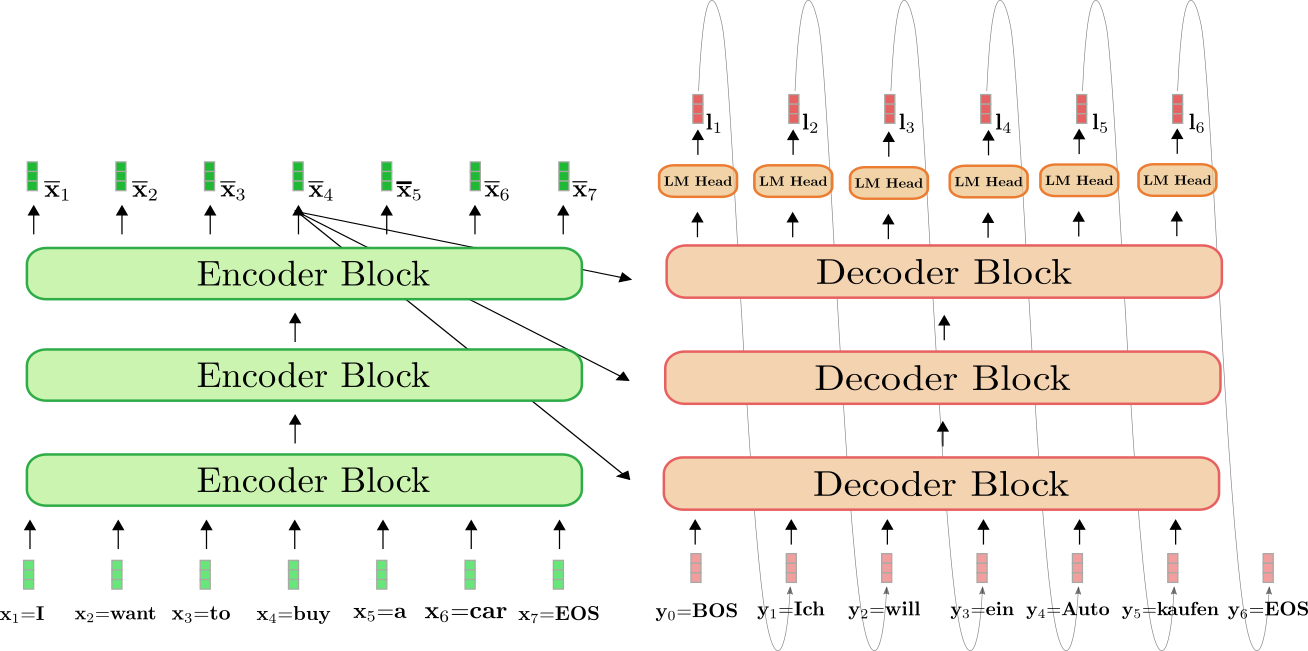
지금까지의 내용을 다시한번 요약하자면 input sequence에 대한 embedding vectors에 positional encoding을 적용하여 sequence 순서를 적용하고 를 통해 Q,K,V를 구한다. 이 Q,K,V는 self-Attention을 거쳐 Attention vector를 얻게 되며 여러가지 관점에서 해석하기 위해 위의 과정을 헤드 수 만큼 진행이 되어 concatenation을 하면 최종적으로 만큼의 차원이 증가한다. 우리는 residual connection을 적용하기 위해 로 선형변환시켜 input과 같은 차원으로 변환 후 residual connection과 normalization을 적용한다. 그 후 일련의 fully connected layer를 통과하는 것이 encoder한 Block의 작업이다.
Transformer는 독립적인 Block을 번 쌓아서 구성하게 된다. 보통 6, 12, 24를 적용하여 encoding vector가 조금 더 정밀해지는 효과를 기대할 수 있다.
Decoder
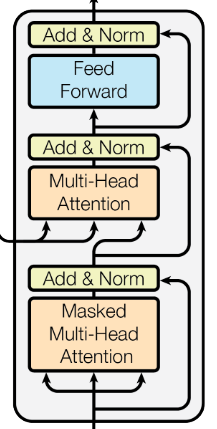
Decoder Block안에 Mased Multi Head Attention을 제외하면 이 전에 설명한 encoder와 같다. 단, Multi Head Attention의 는 decoder, 는 encoder에서 온다는것만 주의하면 된다. 이 부분은 decoder sequence들이 encoder sequence들의 정보를 사용하기 위한 계산이라고 직관적으로 이해할 수 있다. residual connection으로 기존 decoder input의 정보와 합쳐줌으로 적절하게 representation할 수 있다.
Masked Self Attention
decoder의 inference의 상황을 보면 <sos> 토큰이 주어지면 다음 time step을 예측하고 <sos>와 I가 주어졌을 때 go를 예측해야 한다. 다시 말하자면 해당 time step의 이전의 정보들만 사용해 다음 단어를 예측해야 한다. 기존의 self Attention은 이를 고려하지 않고 모든 sequence 전체에 대한 계산을 하기 때문에 inference과정과 괴리가 발생할 수 있다.
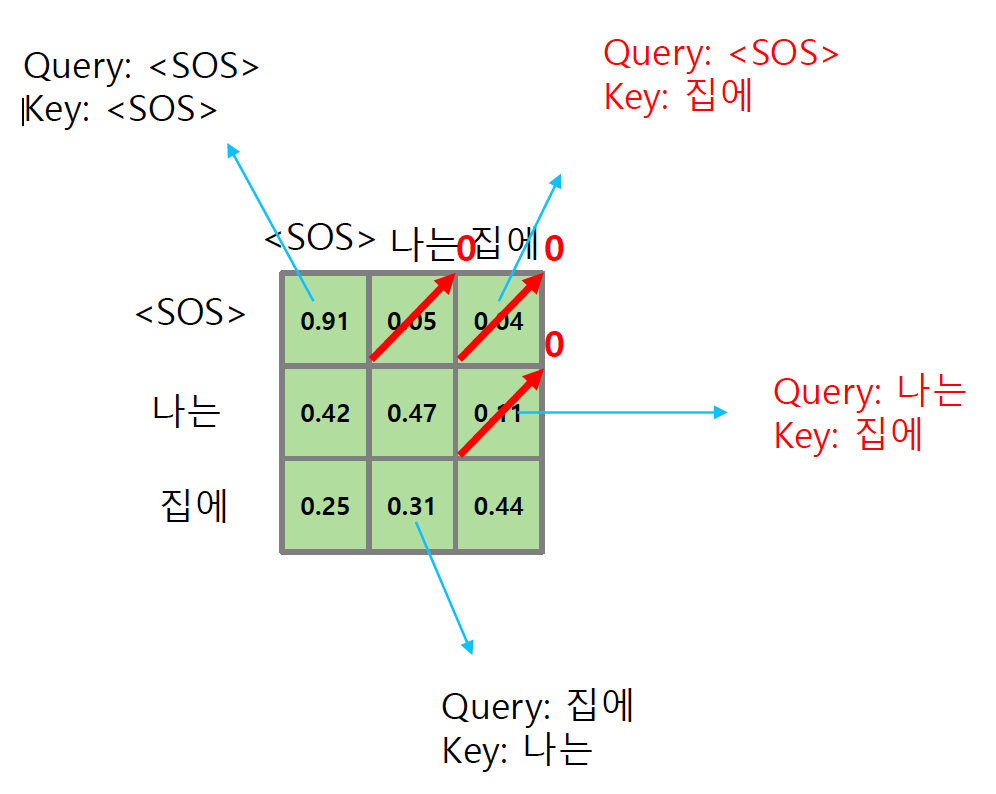
Masked self Attention은 이 문제를 해결하기 위해 의 출력값에서 현재 이전의 정보들을 제외한 값들을 0으로 바꿔준다. 또한 나머지 값의 합이 1이 되도록 정규화해주기 위해 row의 총합으로 각 요소를 나누어 준다.
결과
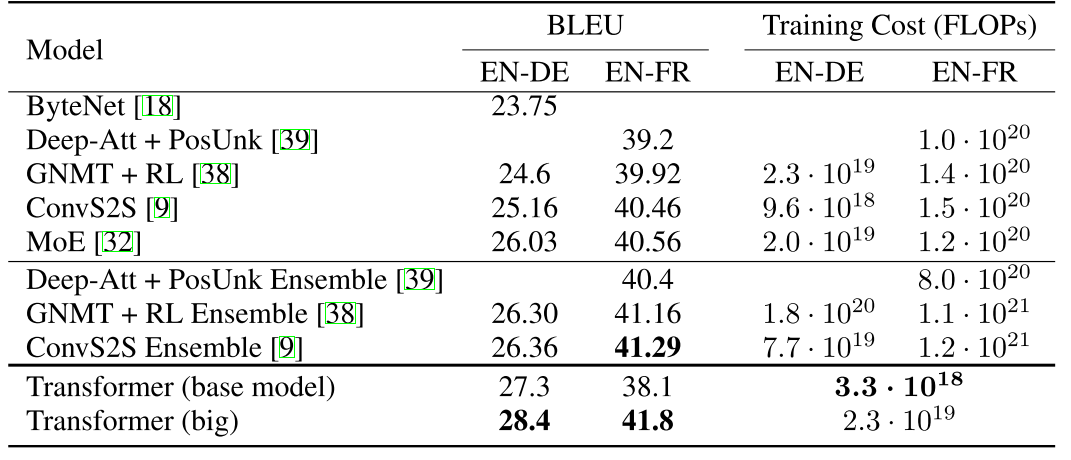
Transformer는 기계번역 분야에서 뛰어난 성능을 나타냈다.
