[Paper] RAFT
논문 : RAFT: Adapting Langugage Model to Domain Specific RAG
Backgound
-
RAG(open book), Fine-Tuning(memorizing)은 현재 흔하게 사용하는 방법론
-
Chain of Thought(CoT)는 정답을 생성하기 위해 필요한 논리적인 단계를 생성하도록 유도하여 추론 능력을 향상시키는 기법
Problem state
-
특정 도메인에서는 많은 LLM들이 사용됨
-
실제로, 새롭게 생겨나는 LLM 서비스들은 특정 도메인에 adapting하는 것이 매우 종요함
-
LLM을 adapting 할 때, RAG를 사용한 in-context learning과 supervised fine-tuning을 고려해야 함.
-
기존에 사용되던 RAG 방법은 학습을 할 수 없다는 단점이 존재함
-
supervised fine-tuning은 학습을 할 수 있지만, 문서를 활용할 수 없다는 단점이 존재함
Contribution
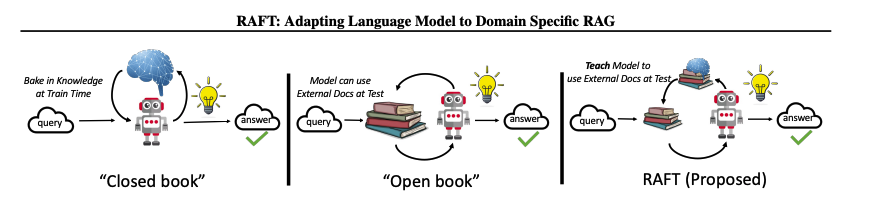
-
SFT(supervised fine-tuning)과 RAG(retrieval augmented generation)을 통합하는 RAFT(Retrieval Augmented Fine Tuning)을 제안
-
RAFT는 fine-tuning을 통해 특정 도메인의 지식을 학습하는 것 뿐만 아니라 정확하지 않은 retrieval에 대해 강건함을 보장하는 것을 목표로 함
-
CoT를 적용한 Answer, 적절한 Documents, 질문과 무관란 distractor Document를 활용하여 학습을 진행하여 모델의 reasoning과 robustness를 보장하도록 함
Method
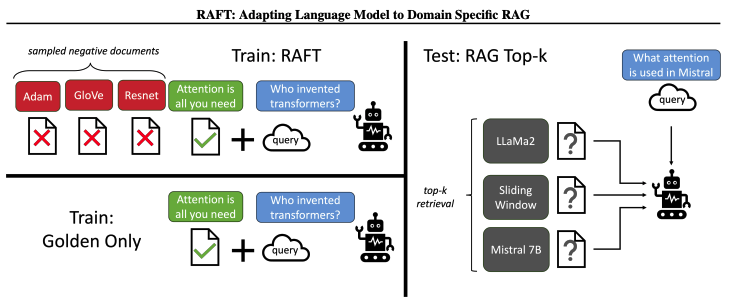
-
question(Q), oracle documents(D), distractor documents(Dk), Chain-of-Hough style answer(A)의 형태로 학습 데이터를 준비함
-
oracle documents(관련성이 있는 문서)는 하나 이상일 수 있음
-
전체의 P만큼은 oracle documents와 distractor documents로 구성하고, 1-P 만큼은 distractor documents로만 데이터셋을 구성함
-
위와 같이 데이터셋을 구성하고 SFT를 진행하여, oracle documents가 없을 경우 memorizing을 활용할 수 있도록 학습함
-
테스트 시, RAG 파이프라인에서 검색 된 top-k 문서를 모델에 제공함
-
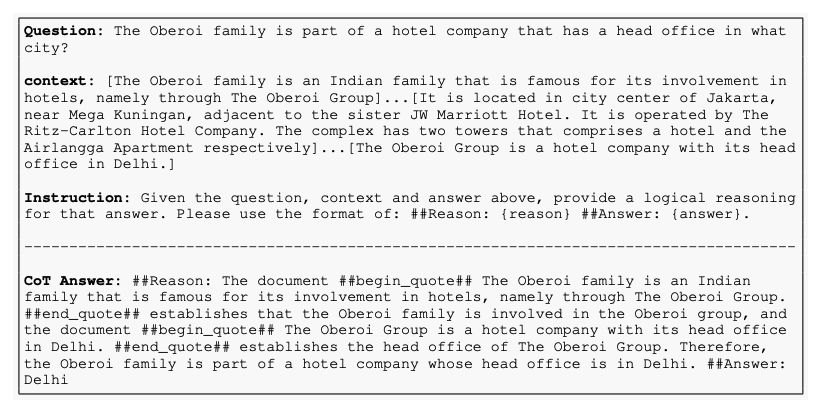
모델의 성능을 올릴 수 있었던 주요 요소는, CoT Style로 제공되는 Answer에 있음
-
모델은 LlaMA-2 7B를 사용하여 학습을 진행함
Result
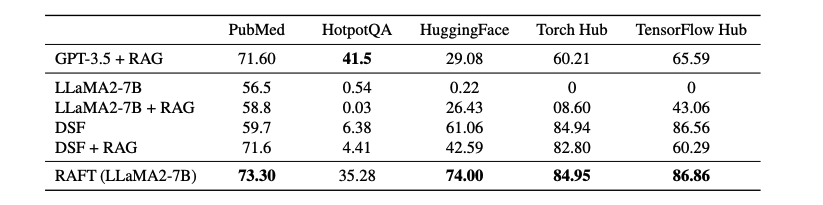
-
대부분 특정 도메인 데이터셋에 대한 성능이 높았으며, GPT-3.5랑 비교해도 손색 없을 성능이 나옴
-
전체적으로, LLaMA-7B 모델은 RAG 유무와 관계 없이 성능이 떨어지는 것을 확인
-
DSF(domain specific fine-tuning)을 진행하면 상당한 성능 향상을 보임, 여기에 RAG를 적용해도 모든 데이터셋에서 성능 향상을 보이지는 않음. 이 이유는 유용한 정보 추출에 대한 학습과 in context 처리가 부족하여 생기는 현상
-
RAFT는 모든 데이터셋에서 성능이 우수한 것을 확인할 수 있음.

-
CoT기법의 효능 검증을 통해 모델 성능에 중요한 영향을 끼치는 것을 확인.
-
본 논문에서는, GPT-4-1107을 통해 CoT prompt를 제작함

- DSF는 질문에 잘못된 응답을 하고 있음. 이 이유는 단순히 QA 쌍으로 학습을 진행하면 제공되는 문서에서 적절한 정보를 추출하는 능력을 손상시킬 수 있음을 보여줌.
-
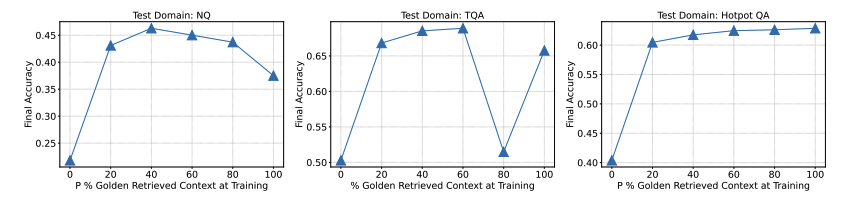
항상 oracle document가 포함되어야 하는지에 대한 연구도 진행됨
-
데이터셋 마다 P의 비율은 달라지는 것을 확인할 수 있음
-
학습/테스트에서 oracle documents와 4개의 distractor documents 포맷을 유지함.
-
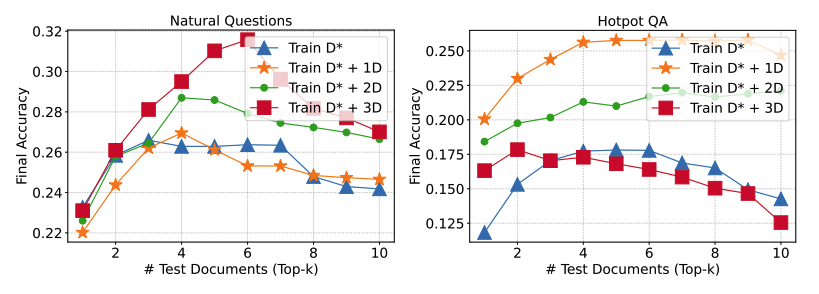
oracle document만 사용하는 것은 성능이 좋지 않을 것을 확인하고 distractor document 개수에 따른 성능도 실험
-
distractor document의 개수에 대한 효용성을 검증하고, 특정 데이터셋 별로 적절한 distractor document의 개수가 다름을 확인.
-
해당 논문은, 4개의 distractor document와 하나의 oracle document로 설정하여 실험
Conclusion
-
RAG와 SFT를 합하여 두 가지의 이점을 모두 활용함
-
distractor document를 사용하여 document를 활용하지 않고 memorizing하도록 학습을 유도함
-
CoT기법을 활용하여 성능 향상을 이룸
