논문 링크 : Re2G
Background
-
non-parametric : dense vector index 또는 BM25
-
Retriever-Augemented Generation(RAG) : retrieval을 이용하여 외부 지식을 통해 모델의 성능을 향상시키는 방법
-
Knowledge Graph Induction(KGI) : RAG를 sloc filling task에 적용, RAG는 DPR을 사용하여 Query Encoder를 학습시키는 것에 반해, KGI는 Passage Encoder도 학습시킴
-
REALM, RAG와 같이 non-parametric을 사용하게되면 cost가 sub-linear하게 증가함
-
DPR (Dense Passage Retrieval) : 신경망 구조를 활용한 retrieval
-
BM25 : TF-IDF의 수식을 변형한 수식을 사용하며, sparse retrieval에 활용
Contribution
-
Re-ranking을 도입하여 쿼리와 관련된 passage들을 찾는다.
-
DPR과 BM25 retrieval을 함께 활용하여 Re-ranking을 확장한다.
Method
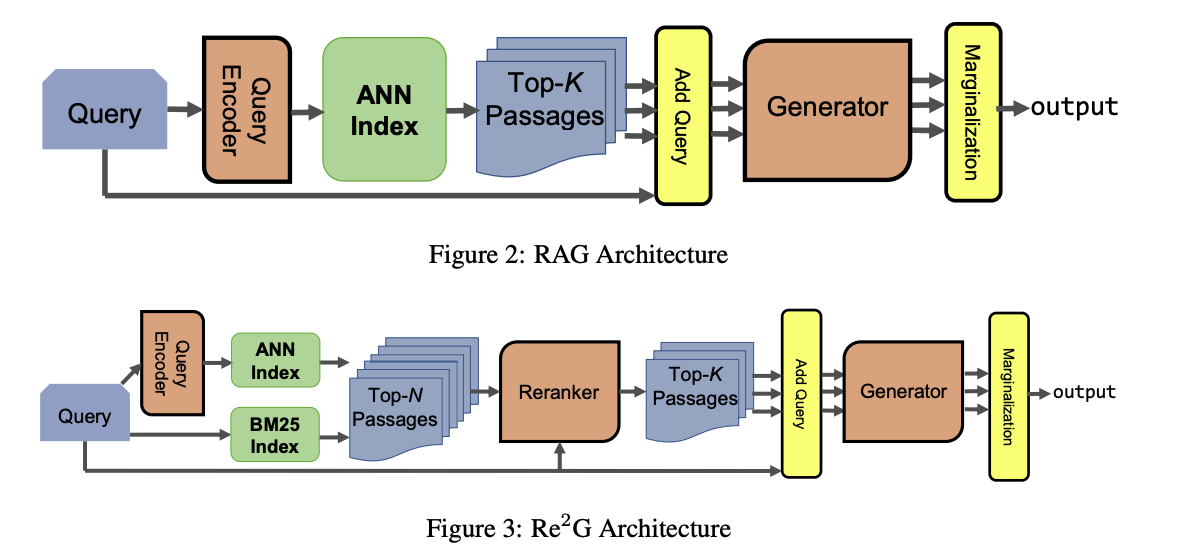
- BM25의 score와 DPR의 score는 비교할 수 없지만, 두 결과를 merge하고 reranker를 활용하여 이를 가능하게 함
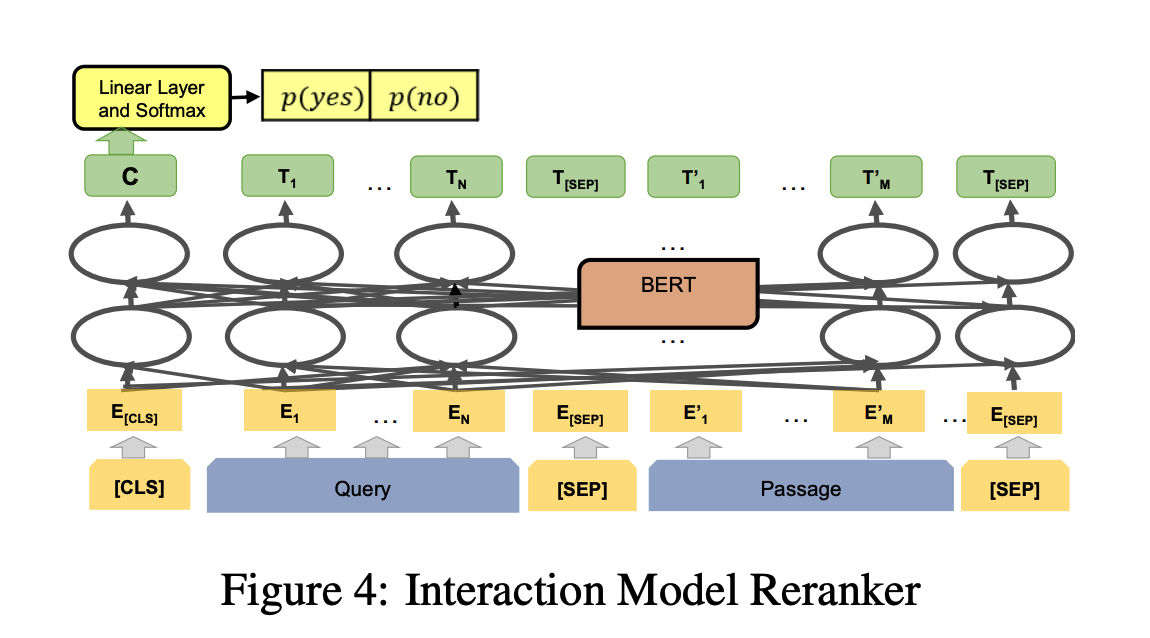
-
reranker는 BERT 모델을 사용하며, query와 passage가 관련이 있는지 없는지를 판단하게 됨
-
총 4가지 페이즈로 나눠서 학습이 진행 됨
- DPR Training : bi-encoder 모델을 사용하며 BM25의 hard negative를 이용하여 학습. 이 과정에서 passage encoder와 query encoder가 업데이트 됨
- Generation Training : 기존 RAG 방식과 동일하게 진행하며 seq-to-seq(BART) 모델을 사용하여 학습. 이 과정에서 query encoder와 generator가 업데이트 됨
- Reranking Training : BERT모델을 사용하며, DPR과 BM25의 추출된 passage들은 merge되고 학습 데이터로 사용됨. 몇몇 데이터셋에서는 positive passage들이 존재할 수 있기 때문에 loss 함수로 summed log-likelihood를 사용함. 이 과정은 고립적으로 이뤄지기 때문에 reranker만 학습되어짐.
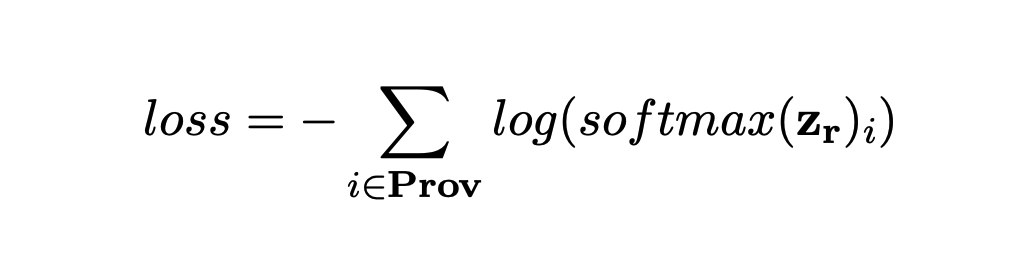
- End-to-End Training : RAG에서는 marginalize로 인해 query encoder로 기울기가 흐를 수 있지만, Re2G에서는 reranker의 score를 이용하기 때문에 generator와 reranker만 학습되는 상황이 벌어짐. 따라서 online knowledge distillation기법을 적용하여 이 문제를 해결함.
- DPR Training : bi-encoder 모델을 사용하며 BM25의 hard negative를 이용하여 학습. 이 과정에서 passage encoder와 query encoder가 업데이트 됨
knowledge distillation
Reranker를 tearcher model로 사용하고, query encoder를 student model로 사용하여 각각 score들을 아래의 loss 함수에 적용하여 학습.
기존의 knowledge distillation은 tearch model은 freeze하고 student model만 학습하지만, 해당 논문에서 online이 붙은 이유는 tearch model도 같이 학습되어지기 때문이다.
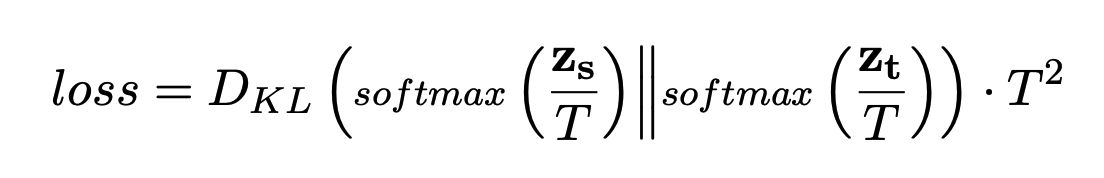
Result
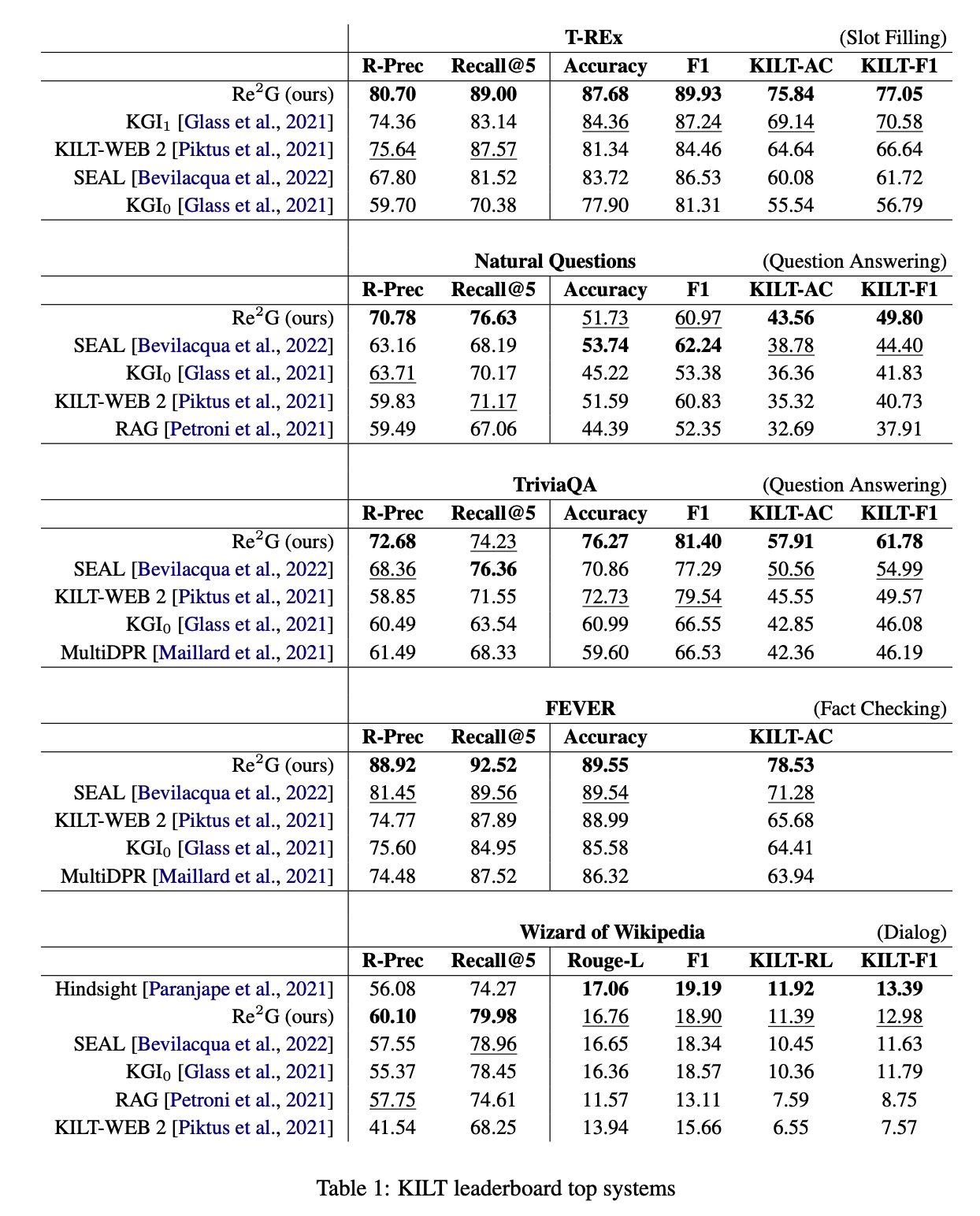
- 총 4가지 task에 대해 테스트를 진행하였으며, 제출 당시 모두 SOTA를 달성했음
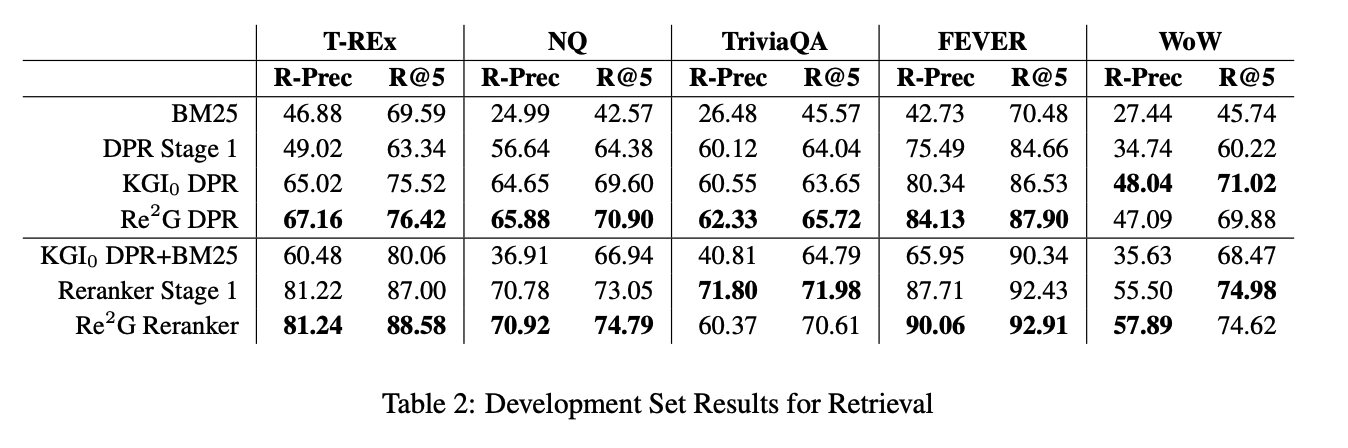
-
4가지 학습 페이즈에 따라 대부분의 데이터셋에서 성능이 상승하는 것을 확인할 수 있음.
-
reranker의 경우 end-to-end training까지 진행하면 성능이 더 좋아지는 것을 확인할 수 있음.
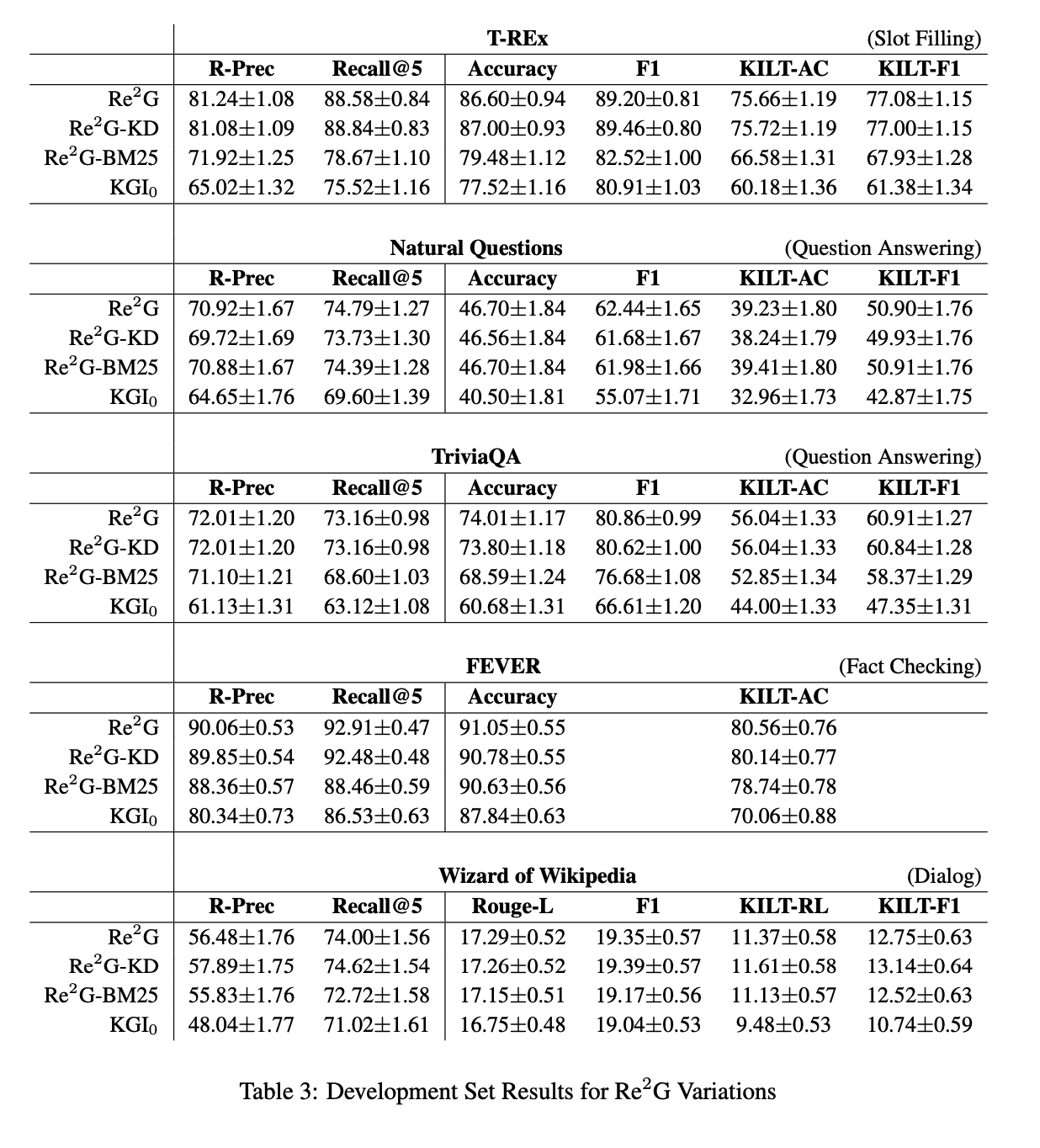
-
Re2G-KD : OKD(online knowledge distillation)제외
-
Re2G-BM25 : BM25 제외
-
KGI0 : bm25, OKD, reranker가 없음
-
전체적으로 Re2G의 성능이 높은 것을 확인할 수 있음.
Conclusion
-
Re-Ranking 과정을 추가하여 높은 성능을 이뤄냄
-
sparse와 dense retrieval을 같이 사용하므로 서로 상호보완적인 효과를 이끌어 냄
-
새로운 OKD 방법을 적용하여 성능 향상을 이뤄냄
