논문 링크 : Adaptive-RAG
Background
-
RAG : 모델 자체로의 성능과 한계를 해결하기 위해, 외부 지식을 사용하여 더 좋은 결과물을 생성하기 위한 하나의 기법이다.
-
parametric : 학습을 통한 LLM 모델들의 가중치를 의미. 모델들의 output들은 parametric memory에 의해서 생성된다.
-
non-parametric : RAG에서 모델의 가중치가 아닌 외부 repository를 의미한다.
Problem statement
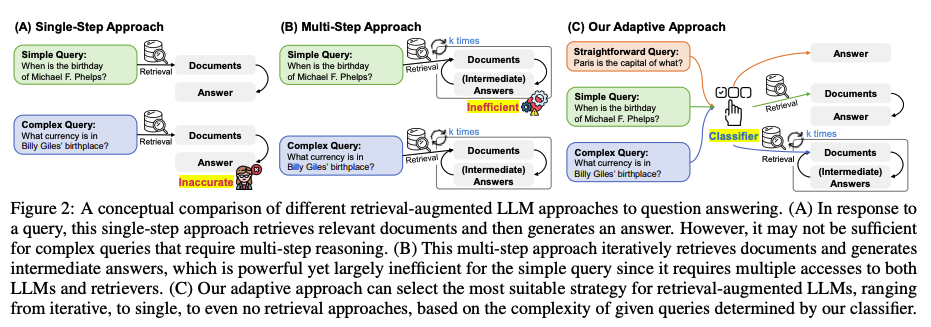
-
복잡한 쿼리를 대처하기 위한 multi-reasoning QA의 연구가 지속되고 있다.
-
관련된 Multi-step approach 연구는 반복적으로 LLM과 Retrievers에 접근해야 하며, 그 비용이 매우 비싸다.
-
비용을 줄이기 위해 single-step Approach, non-retrieval 전략을 사용해서 복잡한 쿼리를 처리하는 것을 충분하지 않은 결과물을 도출한다.
-
위와 같은 상황에 따라 쿼리의 복잡도에 따라 동적으로 대처할 수 있는 adaptive QA system이 필요했으며, 문제를 해결하기 위해 몇몇 연구들이 있지만, 복잡한 쿼리에 대처를 못하거나 매우 복잡하다는 문제점이 있다.
Contribution
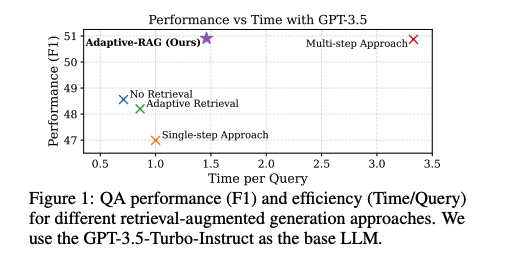
-
입력되는 쿼리의 복잡도에 맞게 가장 적합한 전략을 선택할 수 있도록 한다.
-
해당 논문의 가장 중요한 부분은 새로운 classifier를 이용하여 쿼리의 복잡도를 사전에 정의하는 과정이다.
-
이 과정을 통해 복잡한 쿼리는 multi-step, 간단한 쿼리를 single-step이나 non-retrieval의 approch들로 구분하고 처리하여 효율성과 정확도를 향상시켰다.
Method
Query Complexity Assessment
-
복잡도를 분류하기 위해, 3가지 복잡도를 분류하도록 학습된 작은 언어모델을 사용한다.
-
class label은 A, B, C로 학습되고 각각 non-retrieval, single-step, multi-step의 approach가 필요하다는 것을 의미한다.
Training Strategy
-
분류기를 학습할 수 있는 적절한 데이터셋이 존재하지 않기 때문에 자동으로 데이터셋을 구성하도록 했다.
- 3가지의 접근법의 결과를 기반으로 쿼리 복잡도에 라벨을 지정한다. 예를 들어, non-retrieval으로 적절한 답을 생성할 경우 'A'를 분류하며 non-retrieval 방식은 실패하고 single, multi step으로 적절한 정답을 생성했다면, 더 간단한 모델인 'B'로 라벨링 한다.
- 단, 3가지 접근법으로 적절한 답을 생성하지 못한 경우 라벨링 되지 못하는 문제가 있다.
- 3가지의 접근법의 결과를 기반으로 쿼리 복잡도에 라벨을 지정한다. 예를 들어, non-retrieval으로 적절한 답을 생성할 경우 'A'를 분류하며 non-retrieval 방식은 실패하고 single, multi step으로 적절한 정답을 생성했다면, 더 간단한 모델인 'B'로 라벨링 한다.
-
벤치마크 데이터셋은 이미 그들의 연구에 맞는 편향이 있을 수 있기 때문에, 첫번째 라벨링 단계 후에 라벨이 지정되지 않은 쿼리의 경우 single-step 데이터 셋은 'B', multi-step 데이터 셋은 'c'로 할당한다.
Result
setups
-
효용성을 검증하기 위한 F1, EM, Acc와 효율성을 검증하기 위한 Step(retrieval and generate), Time(average time for answering)을 측정한다.
-
다른 모델들과 공평한 비교하기 위해 같은 모델들을 사용하며, 외부 데이터는 데이터셋의 타입(single, multi)에 따라 다른 소스를 사용했다.
main
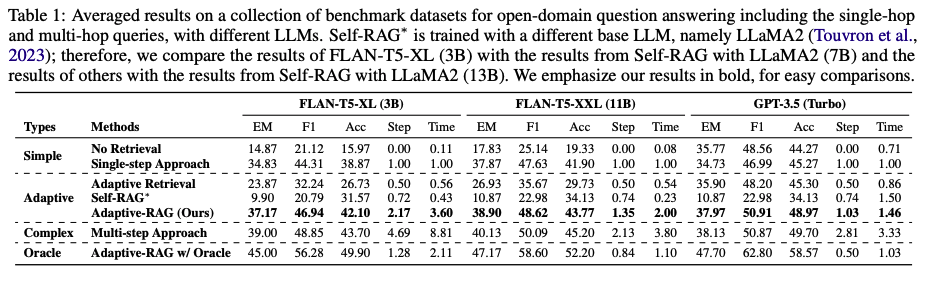
- 가설대로, single-step approach에 비해 multi-step approach가 훨씬 비용이 많이 드는 것을 확인할 수 있다.
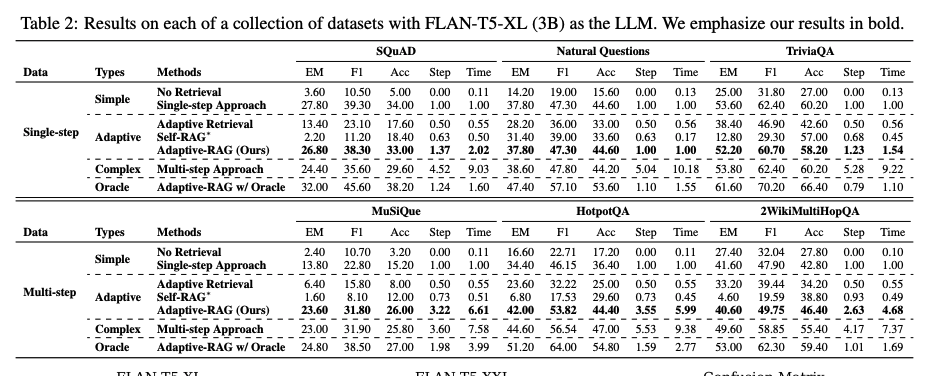
-
위의 결과는, 데이터셋에 따라 방식들의 효율성과 효용성을 볼 수 있다.
-
실제 세상에서는 간단한 쿼리만 존재하거나 복잡한 쿼리만 존재하는 것이 아니기 때문에 Adaptive한 방식이 필요하고 위에서 알 수 있듯이 Adaptive-RAG 방식을 두드러진 성능을 보여준다.
-
oracle classifier를 사용한 Adaptive-RAG와도 비교하며, 더욱 향상된 classifier도 검증 되었다.
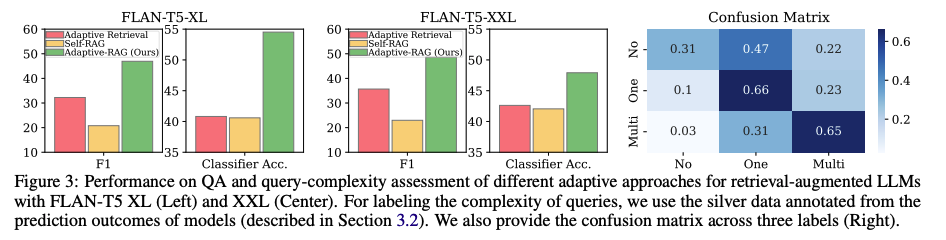
-
다른 adaptive retrieval 보다 복잡도 분류를 더욱 정확하게 분류할 수 있음을 보여준다.
-
현재 다른 모델들 보다 성능은 좋지만 향후에 오분류를 정제해야 하는 과제가 남아 있다.
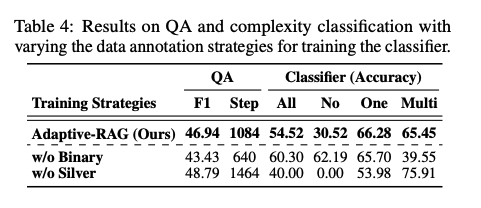
-
모델의 예측 결과로 실버 데이터를 생성하는 것과 데이터셋의 편향을 활용하는 방식을 비교한다.
-
retrieval가 필요한지 고려하지 못하거나, 쿼리의 복잡도를 잘못 예측하는 문제로 인해 정확도는 높아도 일반화 성능은 저하가 되는 것을 확인할 수 있다.
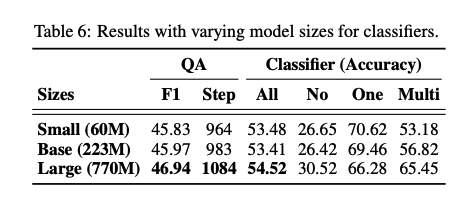
-
분류 모델의 크기에 따른 성능 차이는 크게 없는 것으로 확인했다.
-
결과적으로, 적은 리소스를 사용해도 큰 문제가 없음을 나타낸다.

-
간단한 질문에도 Adaptive Retrieve는 외부 문서를 사용하기 때문에 처리 시간이 길어지며, 관련 없는 정보가 포함되는 경우도 있다.
-
반면, 복잡한 질문에는 Adaptive-RAG는 외부 문서를 사용하지만 Adaptive retrieve는 사용하지 않는 경우를 볼 수 있다.
Conclusion
- 쿼리의 복잡도를 기반으로 동적으로 적절한 전략으로 분류하여 효용성과 효율성을 제시한 연구이다.
