SIMD(Single Instruction Multiple Data)는 여러 데이터 포인트에서 동시에 동일한 작업을 수행할 수 있는 컴퓨터, 즉 병렬 처리를 할 수 있는 CPU 아키텍처를 나타냅니다.
2008년 인텔은 AVX(Advanced Vector Extensions)라는 고성능 ISA(Instruction Set Architecture)를 발표하며, 기존의 SSE(Streaming SIMD Extensions)에 많은 기능들을 지원함과 동시에 더 빠른 속도로 데이터를 처리할 수 있는 기술을 선보였습니다. 또한, AVX는 256비트의 연산이 지원되고 3개의 피연산자가 지원되며 SSE는 128비트와 2개의 피연산자를 사용할 수 있다는 점에서 차이점이 존재합니다.
PyTorch나 TensorFlow와 같이 벡터(데이터 덩어리)연산을 하는 라이브러리는 실제로 API의 역할만 할 뿐 C++가 실제로 AVX 명령어셋을 이용해 벡터 연산(어셈블리어 코드 호출)을 실행합니다.
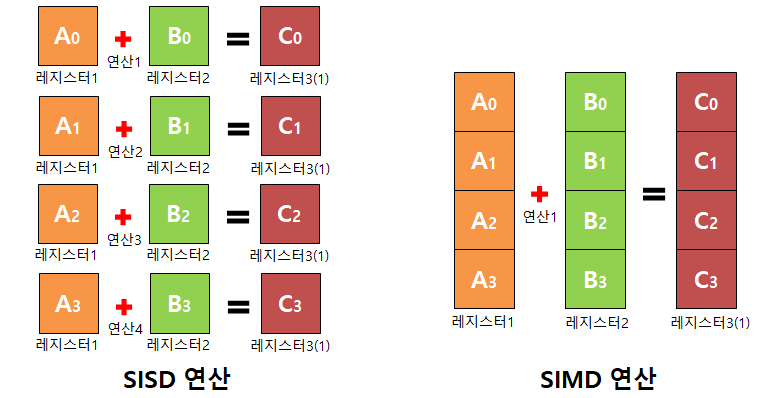
<출처 : 파수 기술블로그>
위의 이미지처럼 4번의 연산(SISD)을 하는 대신에 한번의 연산으로 결과를 얻을 수 있는 방식이 SIMD 입니다.
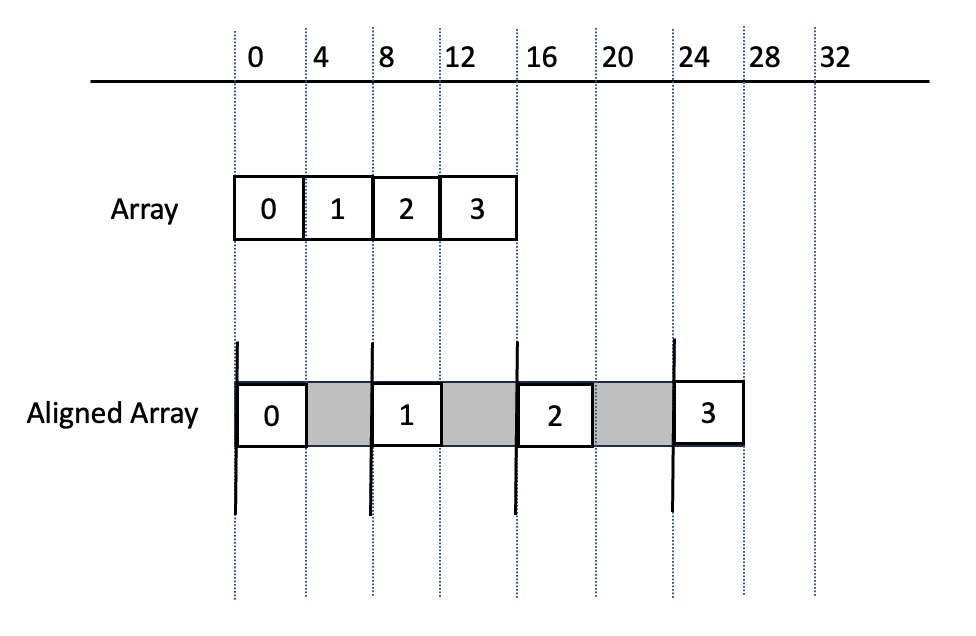
SIMD는 보통 align으로 정렬되어 있는 경우가 있습니다. 이는 메모리 시작지점을 align한 숫자의 배수로 맞추는 것을 의미합니다. 이렇게 정렬하지 않는다면 비정상적인 메모리 접근으로 인식하여 OS가 프로그램을 종료시킬 수도 있습니다.
CPU는 정확한 주소에서 SSE의 경우 16바이트, AVX의 경우 32바이트를 가져와 16 또는 32 바이트 레지스터에 1:1대응 시키게 됩니다.
SIMD의 경우 더 많은 내용과 공부가 필요한 부분이라 오늘은 기본적인 내용만 살펴보도록 하겠습니다.
