현재 ChatGPT와 같은 LLM이 각광받는 상황에서 SFT(Supervised Fine Tuning)와 RLHF(Reinforcement Learning Human Feedback) 용어에 대해서도 심심치 않게 볼 수 있다.
기존의 사전학습 된 언어 모델들은 다음 단어를 예측하여 적절한 문장들을 생성해 냈다. 하지만 ChatBot과 같은 역할을 하기 위한 언어 모델들은 사용자의 입력된 값에 적절하고 도움이 되는 응답을 해야 하는 상황으로 바뀌었다.
이런 상황속에서, LLM을 ChatBot 환경에 맞추어 학습할 수 있는 방법론이 SFT와 RLHF이다.
RLHF(Reinforcement Learning Human Feedback)
RLHF는 모델이 생성한 문장들이 실제 사용자들이 선호할 수 있도록 학습하는 방법론이다. 이름에서도 알 수 있듯이, 강화 학습을 기반으로 한 학습 방법이다. 언어 모델에 의해 생성된 문장들을 보상 모델의 입력으로 사용하여 해당 점수를 통해 언어 모델의 파라미터를 조정하는 방식이다.
RLHF를 적용하기 위해서는 위에서 설명한 Supervised Finetune Training, Reward Model Training, RLHF 단계를 거치게 된다.
- SFT(Supervised Fine Tuning)
SFT는 사용자의 입력(프롬프트)에 적절하게 대응할 수 있는 응답을 직접 학습하는 과정이다. SFT는 우리가 흔히 알고 있는 학습방법으로 생각할 수 있으며, 다양한 사용자 입력 데이터와 그에 맞는 적절한 출력값이 나올 수 있도록 학습한다. 여기서 출력 데이터는 실제 사람들이 검수(Human Annotator)한 데이터를 사용한다.
- RMT(Reward Model Training)
SFT로 학습된 모델을 사용하여 인간의 선호도를 학습시키는 과정이다. 프롬프트와 학습된 언어모델을 통해 생성된 결과들을 사람들이 직접 점수를 매기게 된다. 이 점수를 가지고 Reward Model을 학습시키게 되며 이 모델은 프롬프트와 언어 모델의 결과를 보고 사람의 점수를 예측할 수 있는 모델이 된다.
- RLHF(Reinforcement Learning Human Feedback)
언어 모델이 생성한 결과물과 프롬프트와 이에 의해 생성되는 Reward Model의 점수를 통해 언어 모델의 파라미터를 수정하는 단계이며 PPO(Proximal Policy Optimization)라는 강화 학습 알고리즘을 통해 학습한다.
결과
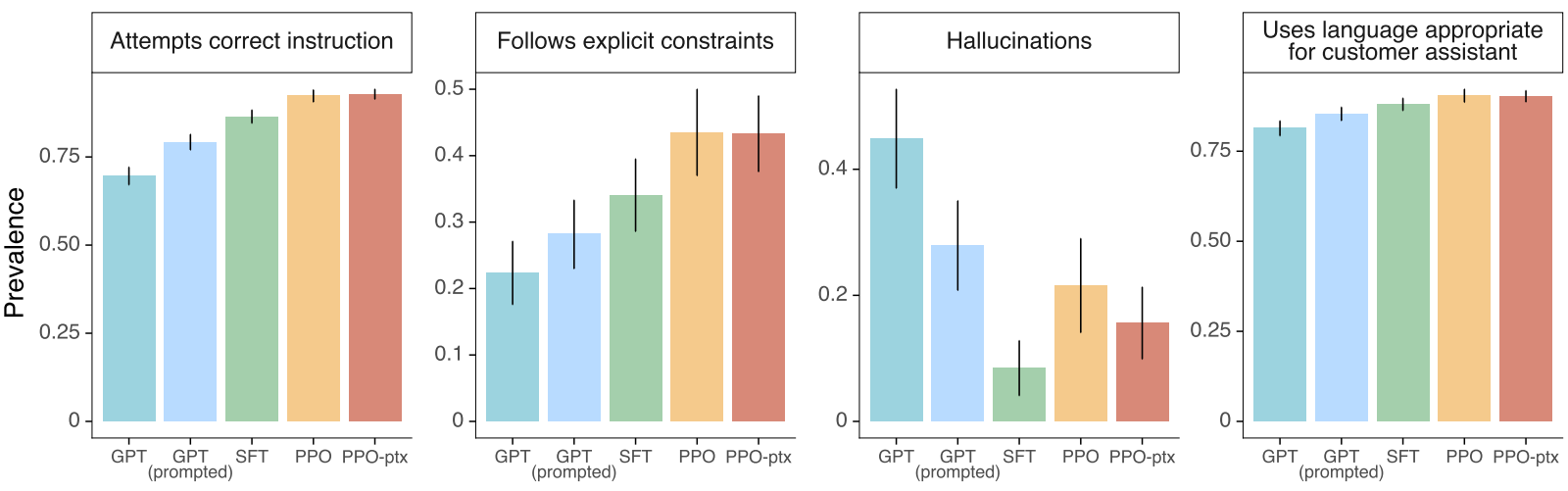
RLHF를 적용한 모델들은 기존 GPT모델에 비해 Hallucination과 사용자 응답에 적절하게 반응하는 것을 볼 수 있다.
