re
정규표현식
문자클래스
-
문자 클래스로 만들어지 정규식은 "[ ]사이의 문자들과 매치"라는 의미
-
문자 클래스를 만드는 메타 문자인 [ ]사이에는 어떤 문자도 들어갈 수 있다.
-
[ ]안의 두 문자 사이에 하이픈 (-)을 사용하면 두 문자 사이의 범위를 나타낸다
- [a-b] : [abc]와 동일하다.
- [0-5] : [012345]와 동일하다.
-
[a-zA-Z] : 알파벳 모두
-
[0-9] : 숫자
-
문자 클래스([ ])안에는 어떤 문자나 메타 문자도 사용할 수 있지만 ^ 메타문자는 주의해야한다. 문자 클래스 안의 ^ 메타 문자는 반대(not)의 의미를 갖는다. 예를 들어 [^0-9]는 숫자가 아닌 문자만 매치된다.
-
자주 사용하는 문자 클래스
| 표기법 | 의미 |
|---|---|
| \d | 숫자와 매치, [0-9]와 동일 |
| \D | 숫자가 아닌 것과 매치, [^0-9]와 동일 |
| \s | whitespace와 매치,[ \t\n\r\f\v]와 동일 |
| \S | whitespace가 아닌 것과 매치,[^ \t\n\r\f\v]와 동일 |
| \w | 문자+숫자+( _ )과 매치,[a-zA-Z0-9_]와 동일 |
| \W | 문자+숫자+( _ )이 아닌 것과 매치, [^a-zA-Z0-9_]와 동일 |
Dot(.)
-
정규 표현식의 dot(.) 메타 문자는 줄바꿈 문자인 \n을 제외한 모든 문자와 매치된다.
-
a.b라는 정규식은 a + 모든문자 + b라는 의미와 같다. ( 숫자도 매치 )
-
a[.]b라는 정규식은 a + . + b라는 의미이므로 혼동하면 안된다.
반복 ( *, +, {m,n} )
< * >
-
반복을 의미하는 메타 문자인 * 은 바로 앞에 있는 문자가 0부터 무한대로 반복될 수 있다는 의미이다.
- ca*t : c + a ( a가 없거나 무한대로 많거나 ) + t라는 의미이다.- ct, cat, caat, caaaaaat ... 과 매치된다.
< + >
-
반복을 의미하는 메타 문자인 + 은 바로 앞에 있는 문자가 1이상의 반복을 의미한다.
- ca+t : c + a ( a가 한개 이상 ) + t 라는 의미이다.- cat, caat, caaaat ...과 매치된다.
{m,n}
-
반복 회수를 제한하고 싶을때 사용하는 방법이다.
-
{m,n} 정규식은 반복 회수가 m부터 n까지 매치할 수 있다.
- ca{2,5}t : caat , caaat, caaaat, caaaaat까지 매치된다.
-
m이나 n을 생략하여 사용할 수 있다.
- {,3} : 횟수가 0부터 3이하
- {3,} : 횟수가 3이상
-
{m}과 같이 사용하면 반드시 m번 반복한다는 의미이다.
- ca{2}t : caat와 매치된다.
-
?은 반복은 아니지만 비슷한 개념으로 사용한다. ? 메타문자가 의미하는 것은 {0,1}이다.
- ab?c : a + b(있어도 되고 없어도 된다) + c라는 의미이다.
python에서 정규 표현식 모듈사용법
- compile
import re
p = re.compile('ab*')
lst = ['a','ab','abb','abbb']
for word in lst:
print(p.match(word).group())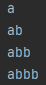
- 문자열 검색
- match() : 문자열의 처음부터 정규식과 매치되는지 조사
import re
p = re.compile('[a-z]+')
print(p.match('python').group())
print(p.match('3python'))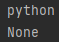
- search() : 문자열 전체를 검색하여 정규식과 매치되는지 조사
import re
p = re.compile('[a-z]+')
print(p.search('python').group())
print(p.search('3python'))
- findall() : 정규식과 매치되는 모든 문자열을 list로 반환
import re
p = re.compile('[a-z]+')
print(p.findall('python is so good'))
compile options
| 옵션(약자) | 설명 |
|---|---|
| DOTALL(S) | Dot(.)는 줄바꿈을 제외한 모든 문자를 매치하는데, 줄바꿈 문자 포함 매치되게 한다 |
| IGNORECASE(I) | 대소문자에 관계없이 매치할 수 있도록 한다. |
| MULTILINE(M) | 여러줄과 매치할 수 있도록 한다.( ^, $ 메타문자와 관계가 있는 옵션이다.) |
- DOTALL(S)
import re
p = re.compile('a.b',re.DOTALL)
p1= re.compile('a.b')
print(p.match('a\nb'))
print(p1.match('a\nb'))
- IGNORECASE(I)
import re
p = re.compile('[a-z]',re.I)
print(p.match('a'))
print(p.match('B'))
- MULTILINE(M)
import re
p = re.compile('^python\s\w+',re.M)
p1 = re.compile('^python\s\w+')
data = """python zero
python one
python two
python three"""
print(p.findall(data))
print(p1.findall(data))
MULTILINE 옵션은 ^, $ 메타 문자를 각 줄마다 적용해주는 것이다.
백슬래시 문제
\section이라는 문자열을 찾기 위한 정규식을 만들때 "\section"은 \s(공백)으로 해석된다.
이 문제를 해결하기 위해 \section으로 표현을 해주어야 하는데, 파이썬에서는 리터럴 규칙에 따라 \이 \로 변경되어 결과적으로 \\ 4개를 써주어야 \section을 의미하게 된다.
이 복잡함을 해결하기 위해 파이썬 정규식에 Raw String 규칙이 생겨나게 되었다.
import re
p = re.compile('\section')
p1 = re.compile('\\section')
p2 = re.compile('\\\\section')
r_p = re.compile(r'\\section')
print(p.findall('\section'))
print(p1.findall('\section'))
print(p2.findall('\section'))
print(r_p.findall('\section'))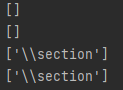
grouping
- 어떤 문자열이 계속해서 반복되는지 조사하는 정규식을 작성할 경우 사용한다.
import re
p = re.compile('(abc)+')
print(p.search('abcabc'))
- grouping된 일부분만 뽑아내고 싶을 경우
import re
p = re.compile('(abc)+(cd)')
m=p.search('abcabccd')
print(m.group(0))
print(m.group(1))
print(m.group(2))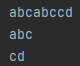
인덱스 0 : 매치된 전체 문자열
- grouping된 문자열에 이름 붙이기
import re
#(?P<그룹명>..)
p = re.compile('(?P<name>\w+)\s\d+')
m=p.search('mike 1234')
print(m.group(0))
print(m.group(1))
print(m.group('name'))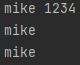
- 전방탐색
예를들어 (.+:) 정규식과 일치하는 문자열로 http:를 반환해주었을 때, :를 제외하고 싶은경우에 사용한다.
-
긍정형 전방탐색 (?=...) : ...에 해당되는 정규식과 매치되어야하며 조건이 통과되어도 문자열이 소비되지 않는다.
-
부정형 전방탐색 (?!...) : ...에 해당되는 정규식과 매치되지 않아야 하며 조건이 통과되어도 문자열이 소비되지 않는다.
import re
p = re.compile('.+:')
m=p.search('http://asd')
print(m.group())
p1 = re.compile('.+(?=:)')
m=p1.search('http://asd')
print(m.group())
p2 = re.compile('.+[.](?!exe).*')
m=p2.search('asd.bat')
m2=p2.search('asd.exe')
print(m.group())
print(m2.group())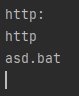
sub
sub 메서드를 사용하면 정규식과 매치되는 부분을 다른 문자로 바꿀 수 있다.
import re
# re.sub(바꾸기전 단어, 바꿀단어, 문자열)
print(re.sub('a','g','asdasd'))
print(re.sub('\d+','num','asd123asd'))
p = re.compile('red|blue')
print(p.sub('color','red phone, blue eyes'))
#한번만 바꾸고 싶은 경우
print(p.sub('color','red phone, blue eyes',count=1))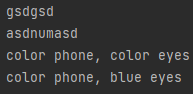
split
split 메서드를 사용하면 정규식과 매치되는 부분으로 나눠 리스트로 반환 해준다.
- string을 정규식을 포함하지 않고 나누기
import re
a = 'mike,michael,john'
print(re.split(',',a))
- string을 정규식을 포함하여 나누기
import re
a = 'mike,michael,john'
print(re.split('(,)',a))
