heap
#기본적으로 min_heap 구조
import heapq
arr = [1, 2, 3, 4]
#배열을 heap으로 변환 ( 빈 배열은 push시 힙으로 구성된다. )
heapq.heapify(arr)
#heap에 데이터 삽입
heapq.heappush(arr,data)
heapq.heappush(arr,-data)
heapq.heappush(arr,(-data, data))
#heap에 데이터 삭제
heapq.heappop(arr)
#heap 데이터 조회
print(arr[0])queue
from collections import deque
arr = [1, 2, 3, 4]
queue = deque(arr)
queue = deque([1, 2, 3, 4])
#원소 삽입
queue.insert(index, data)
#원소 제거
queue.popleft()
queue.append(data)defaultdict
defaultdict는 dict의 값에 기본 default값을 지정할 수 있다.
dic = {}
## key error발생
print(dic['a'])
from collections import defaultdict
dic1 = defaultdict(list)
dic2 = defaultdict(int)
dic3 = defaultdict(set)
print(dic1['a'])
print(dic2['a'])
print(dic3['a'])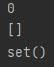
Counter
sequence type의 data의 요소들의 개수를 반환하는 dict 자료구조
from collections import Counter
a = [1, 2, 3, 4 , 5, 4, 2]
print(Counter(a))
string = 'hello'
print(Counter(string))
Ctr = Counter( {'h':1, 'e':1, 'l':2, 'o':1} )
print( list(Ctr.elements() )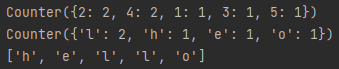
OrederDict
데이터를 입력한 순서대로 반환하는 dict 자료구조
파이썬 3.6 이상부터는 기본적으로 입력한 순서대로 반환하는 기능을 제공하지만
순서까지 고려하여 동등성을 따질때 orederdict를 사용한다.
from collections import OrderedDict
O1 = OrderedDict({'a':1,'b':2,'c':3})
O2 = OrderedDict({'a':1,'c':3,'b':2})
print(O1 == O2)
dic1 = {'a':1,'b':2,'c':3}
dic2 = {'a':1,'c':3,'b':2}
print(dic1 == dic2)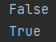
permutations
순열
from itertools import permutations
a = [1,2,3,4]
print(list(permutations(a,2)))
print(list(permutations(range(1,5),2)))
combinations
조합
from itertools import combinations
a = [1,2,3,4]
print(list(combinations(a,2)))
print(list(combinations(range(1,5),2)))
print(list(combinations('abc',2)))
product
중복순열
from itertools import product
print(list(product('ab','cd')))
print(list(product(range(1,4),range(1,4))))
chain
flatten의 기능으로 ( 2차원 -> 1차원 )
from itertools import chain
a = [[1,2],[3,4]]
print(a)
print(list(chain(*a)))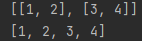
math
import math
# 올림
print(math.ceil(2.5))
#팩토리얼
print(math.factorial(3))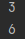
enumerate
어떤 데이터에서 요소들을 반환할 때, 번호를 붙여서 반환
a = ['a','b','c']
for i,v in enumerate(a):
print(i,v)
print(list(enumerate(a)))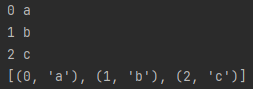
zip
두 개의 데이터들을 병렬적으로 반환
a = ['a','b','c']
b = ['d','e','f']
for i in zip(a,b):
print(i)
print(list(zip(a,b)))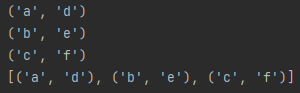
map
list에 똑같은 함수를 적용할때 사용
a = [1,2,3,4]
print(list(map(lambda x:x**2,a)))
print(list(map(lambda x:x**2 if x%2==0 else x,a)))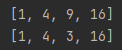
reduce
map과 달리 list에 함수를 적용하고 통합한다.
from functools import reduce
a=[1, 2, 3, 4]
print(reduce( lambda x,y : x+y, a) )
함수에 입력되는 arguments
keyword
def keyword_arg(name,age):
print(f'name is {name}, age is {age}')
keyword_arg('john',30)
default
def keyword_arg(name,age=30,):
print(f'name is {name}, age is {age}')
keyword_arg('john')
keyword_arg('mike',20)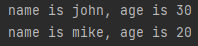
variable length
개수가 정해지지 않은 변수
def keyword_arg(name,age,*args):
print(f'name is {name}, age is {age}')
#기존 파라미터 이후에 나오는 인수를 tuple로 저장
print(args)
print(sum(args))
keyword_arg('mike',20,1,2,3,4,5)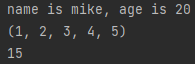
keyword varialbe length
파라미터 이름을 따로 지정하지 않고 사용
def keyword_arg(name,age,*args,**kwargs):
print(f'name is {name}, age is {age}')
print(args)
print(sum(args))
#파라미터를 dict형태로 저장
print(kwargs)
print('weight is {tall}'.format(**kwargs))
print('tall is {weight}'.format(**kwargs))
keyword_arg('mike',20,1,2,3,4,5,tall=170,weight='70')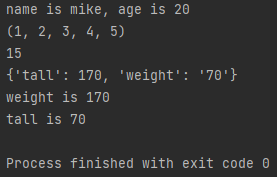

지식 공유