Golang은 뛰어난 동시성 지원을 장점으로 자주 언급된다. 다른 프로그래밍 언어에서는 쓰레드를 활용하여 동시성 프로그래밍을 하지만 Golang에서는 고루틴을 활용하여 동시성 프로그래밍 개발을 하게 된다. 그렇다면 고루틴이 무엇이고 고루틴은 쓰레드와 무엇이 다르며 어떻게 동작하기에 동시성 처리 작업에 장점으로 언급되는 걸까?
고루틴(goroutine)
Go 언어에서는 고루틴을 다음과 같이 소개한다
“lightweight thread managed by the Go runtime”
한 마디로 Go 런타임에서 관리되는 경량 쓰레드라고 소개한다.
여기서 말하는 경량 쓰레드는 OS 레벨의 쓰레드와는 다른 개념이고 Go 언어 런타임에서 관리되는 논리적(혹은 가상적) 쓰레드라고 한다. 고루틴은 OS 쓰레드보다 더 가볍고 비동기적인 동시성 처리를 위해서 만들어진 것으로 Go 프로그램 런타임시에 생성하여 사용하고 소거하는 형식이기 때문에 Go 런타임이 관리하는 경량 쓰레드라고 하는 것이다.
아래는 Go에서 고루틴을 활용해본 예시 코드이다.
고루틴 사용 Example code
package main
import (
"fmt"
"sync"
)
func main() {
wg := sync.WaitGroup{}
wg.Add(1)
counter := 0
// goroutine 생성 및 다음 익명 함수의 작업을 할당
go func() {
defer wg.Done()
for i := 0; i < 1000; i++ {
counter++
}
}()
wg.Wait() // goroutine 작업의 완료까지 대기
fmt.Println("counter :", counter)
}이전에 쓰레드를 자바를 이용해 학습하고 연습해본 경험이 있는데, 간단한 예시이지만 샘플 코드만 보더라도 확실히 Go에서 쓰레드를 활용하는 코딩이 훨씬 간편하다는 것을 알 수 있었다.
고루틴, 쓰레드 차이점
고루틴과 쓰레드의 차이점은 크게 3가지의 차이점으로 분류할 수 있다. 즉 아래 차이점이 고루틴이 경량 쓰레드라고 불리우게 된 이유이자 장점과 같은 요소들로 볼 수 있다.
메모리 소비
Go에서 고루틴을 생성할 때 많은 메모리를 필요로 하지 않는다.
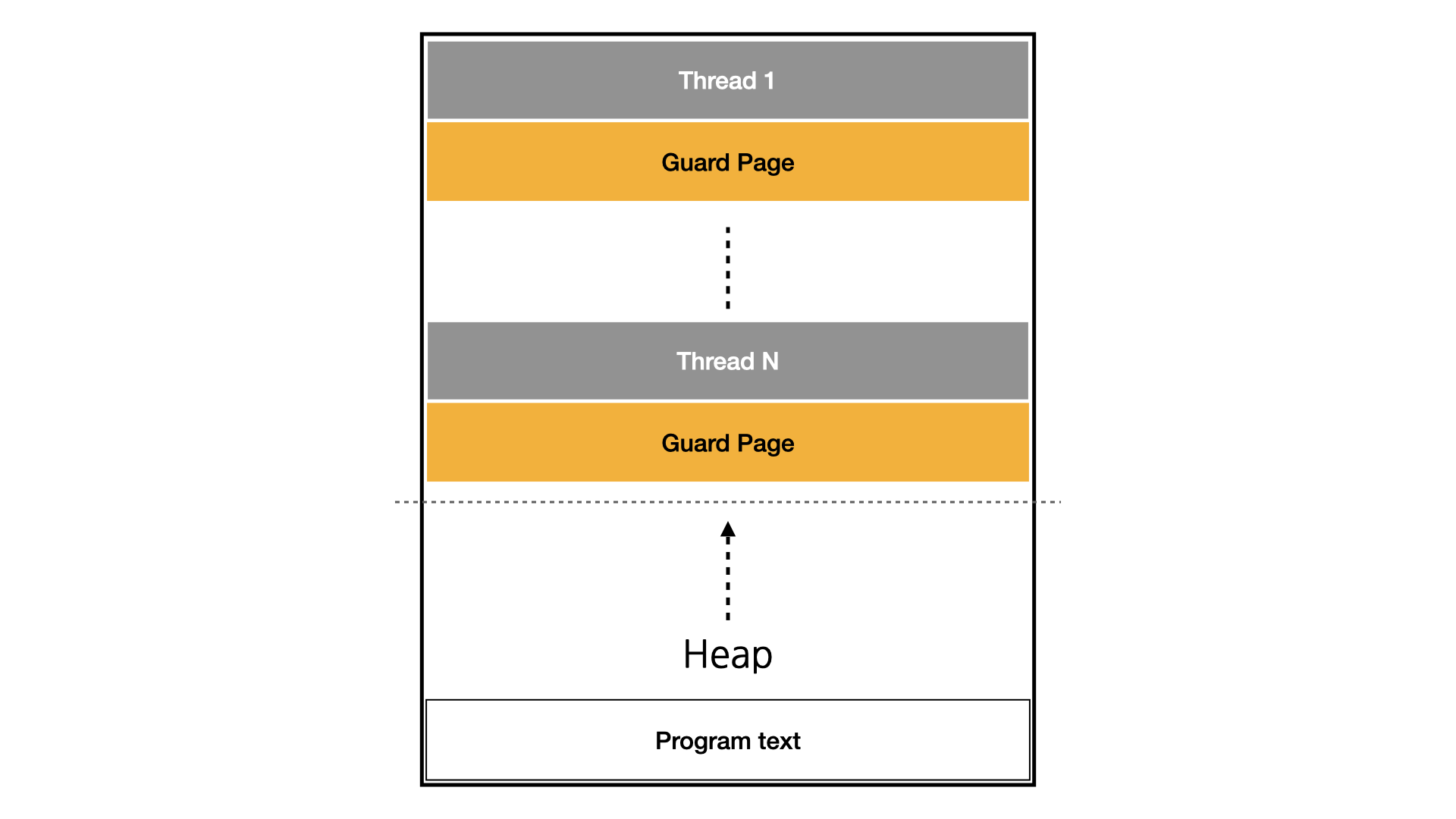
- 고루틴 생성시 약 2KB의 스택 메모리 공간만 필요로 하며, 필요에 따라 힙 메모리 공간을 사용하기도 한다
- 반면에 쓰레드는 쓰레드가 사용할 메모리 공간과 각 메모리 간의 경계 역할을 하는 Guard Page라고 불리는 메모리 영역과 함께 포함하여 약 1Mb의 메모리 공간을 소모하여 생성된다
- 따라서 Golang 기반의 서버에서는 요청 1건 당 1개의 고루틴을 생성 하도록 만들 수 있지만, 요청 1건 당 1개의 쓰레드를 할당하는 다른 언어 기반의 서버는 앞선 방식으로 쓰이게 되면 결국에는 OOM(OutOfMemory) 이슈의 원인이 될 것이다. 이는 쓰레드를 사용하는 언어기반으로 만들어진 서버가 지속적으로 쓰레드 생성 요청을 받게 된다면 마주하게 될 이슈다(예로들어 Java, C++), 그래서 이러한 언어 환경에서는 쓰레드를 미리 만들어 두고 재활용하는 형태인 쓰레드 Pool을 사용하고 해당 쓰레드 비용에 대한 문제를 풀어내려는 노력이 있을 것이다.
생성, 소거 비용
OS 쓰레드는 생성/소거 시 많은 비용이 들어가게 된다. OS로 부터 쓰레드 리소스를 요청을 통해 생성하고 쓰레드 작업 완료 시 해당 리소스를 OS에 다시 반환해야하기 때문이다. 그래서 OS레벨의 쓰레드를 직접 Call하여 쓰레드를 생성/소거하는 언어들은 이 문제를 풀어내기 위해서 쓰레드 Pool을 활용하여 이러한 비용 문제를 해소하려는 노력이 있다. 반면에 Go의 고루틴은 런타임에서 논리적(즉, OS레벨 쓰레드와 달리 하드웨어에 의존적이지 않음)으로 생성되고 소거되기 때문에 상대적으로 해당 작업들에 소모되는 비용이 저렴하다. 따라서 Go언어에서는 이러한 고루틴을 수동 관리 하는 매뉴얼을 제공하지 않는다고 하고, 고루틴은 OS 쓰레드와 상대적으로 앞선 OOM과 같은 문제에 대한 걱정/부담없이 생성하여 사용해도 된다고 표현하곤 한다 (그렇다고 막 사용해선 안됨..).
Context Switching 비용
하나의 쓰레드가 특정 작업을 처리하기 위해서 Blocking된다면 다른 쓰레드가 그 대신하여 처리하도록 스케줄링되어 있다. 쓰레드가 스케줄링되고 쓰레드가 교체되는 동안에 스케줄러에서는 모든 레지스터들을 save/restore해야 한다. 일반적인 쓰레드 Context Switching 작업 시 16개의 범용 레지스터, PC(Program Counter), SP(Stack Pointer), Segment 레지스터, 16개의 XMM레지스터, FP coprocessor state, 16개의 AVX 레지스터, 모든 MSR들 등을 save/restore 작업을 진행해야 한다. 따라서 이와 같은 작업을 처리하기 때문에 생각보다 Context Switching 시 많은 비용을 소모하게 된다고 말하는 것이다. 하지만, 고루틴은 3개의 레지스터(PC,SP,DX)만 save/restore 작업을 하기 때문에 상대적으로 쓰레드보다 Context Switching 비용을 적게 소모한다.
위 내용을 통해 고루틴이 무엇이고 쓰레드와의 차이점을 보았고, OS 쓰레드와는 달리 고루틴은 Go 언어 자체적으로 구현화된 쓰레드라 볼 수 있으며 종합했을 때 OS 쓰레드에 비해 상대적으로 메모리 비용이 적게 소모되기 때문에 경량 쓰레드라고 부르게된 이유를 알 수 있었다.
동시성 개발 측면에서 충분히 장점 중 하나로 볼 수 있을 것 같고, 추가적으로 Go언어는 런타임에서 스케줄러가 이러한 고루틴들을 스케줄링하고 최적화하는 기법을 통해 시스템 리소스를 효율적으로 활용할 수 있다고 한다. 그래서 Go 런타임 환경에서의 스케줄러에 대하여 알아보려고 한다.
고루틴은 어떻게 실행될까?
Go언어는 프로그램 시작과 끝나는 시점까지 런타임 내내 고루틴들을 관리한다. 또한 고루틴은 M:N 쓰레드 모델(LWP)을 채택하고 있어 기존의 쓰레드/쓰레드Pool를 활용하는 방식보다 더 가볍고 빠른 특성을 지니고 있다 한다. 고루틴 스케줄러를 알아가기 앞서 쓰레드 타입별 특징에 대해서 알아보자.
쓰레드의 종류
User-Level 쓰레드: User-Level의 영역인 사용자 라이브러리를 통해 쓰레드 관리 기능이 제공되고, 여러 User-Level 쓰레드가 1개의 OS 쓰레드 위에서 동작하는 형태(즉, 1:N)- Context Switching 비용이 적기 때문에 속도가 빠르다
- OS 쓰레드 1개만 사용하는 구조이기 때문에 멀티 코어를 활용할 수 없다
- User-Level 중 하나가 syscall으로 인해 block되면 나머지 User-Level 쓰레드들도 멈추게 된다. 이는 Kernel이 프로세스 내부의 쓰레드를 인식하지 못하여 해당 프로세스를 대기 상태로 전환시키기 때문이다
Kernel-Level 쓰레드: Kernel-Level 쓰레드는 운영체제가 지원하는 기능으로 구현되어 즉 Kernel이 쓰레드의 생성, 스케줄링을 담당하게 된다. 1개의 OS 쓰레드에 1개의 User-Level 쓰레드를 할당(즉, 1:1)- Kernel은 프로세스 내의 다른 쓰레드를 중단시키지 않고 계속 실행시킴
- 멀티 프로세싱 환경에서는 커널은 여러개의 쓰레드를 각각 다른 프로세서에 할당할 수 있다
- 멀티 코어를 제대로 활용할 수 있다
- Context Switching 비용이 비싸 속도가 느리다
Combined: Kernel-Level 쓰레드와 User-Level 쓰레드를 혼합하여 사용하는 방식, 위 두 방식의 장점을 혼합한 방식이라 할 수 있음(즉, M:N)- User-Level 쓰레드는 LWP에 의해 다중화(Multiplexing)된다.
- LWP는 Kernel과 프로세스 사이에서 중간자 역할
- Context Switching 속도가 빠르고 멀티 코어 활용도 가능하다
- 구현이 어렵다
Go 언어는 앞서 언급한 것 처럼 Combined(M:N)모델을 활용하고 있다. 즉, 고루틴(User-Level 쓰레드)-OS 쓰레드(Kernel-Level 쓰레드)를 M:N 맵핑하는 형태로 스케줄링된다. Context Switching, 멀티 코어에 대한 장점을 누리고 있고 또한 구현이 어렵다는 단점을 언어적 차원에서 해당 단점을 해소 시키고 있다.
+) 위 내용은 이 링크의 글을 통해 학습하게 되었고 간략히 언급하고 넘어가겠습니다. 자세한 내용에 대해서는 위 링크 참조를 부탁드립니다.
Go 스케줄러
Go 언어 런타임에 Golang 스케줄러가 포함되어 있다. golang 스케줄러는 고루틴의 스케줄링 작업을 수행하고 다수의 고루틴들이 소수의 쓰레드 위에서 동작하게 되며, Go의 스케줄러는 G-M-P 모델로 표현되어 스케줄링이 처리되는 구조이다. 여기서 G-M-P 모델이란 무엇일까?
G-M-P 모델(구조체)
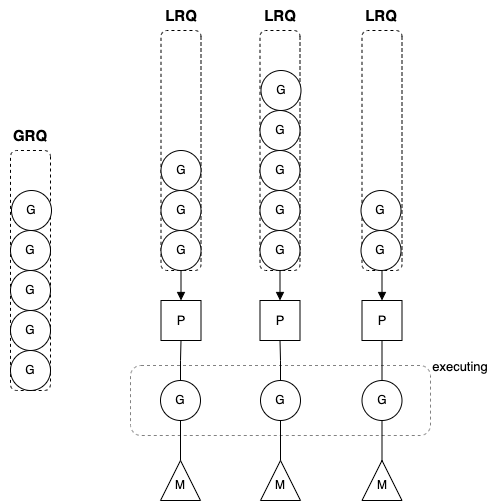
-
G(Goroutine): Goroutine는 말그대로 고루틴 의미하며, 고루틴을 구성하는 논리적 구조체의 구현체를 말한다- Go 런타임이 고루틴을 관리하기 위해서 사용
- 컨텍스트 스위칭을 위해 스택 포인터, 고루틴의 상태 정보 등을 가지고 있다
G는LRQ에서 대기하고 있다- goroutine, 고루틴 구조체 구조 링크
-
M(Machine): Machine는 OS 쓰레드를 의미하며, 실제 OS 쓰레드가 아닌 논리적 구현체로 표준 POSIX 쓰레드를 따른다고 한다.M은P로 부터G를 할당받아 실행한다- 고루틴과 OS 쓰레드를 연결하므로 쓰레드 핸들 정보, 실행중인 고루틴,
P의 포인터를 가지고 있다 - machine, OS 쓰레드 논리 구조체 구조 링크
-
P(Processor): Processor는 프로세서를 의미하며, 실제 물리적 프로세서를 말하는게 아니라 논리적인 프로세서로 정확히는 스케줄링과 관련된 Context 정보를 가지고 있다- 런타임 시 Go 환경변수인 최대 GOMAXPROCS 설정 값만큼의 개수로 프로세서를 가질 수 있다
P는 컨텍스트 정보를 담고 있으며, 1개의P당 1개의LRQ를 가지고 있다. 그래서G를M에 할당하는 역할을 수행- processor, Context 논리 구조체 구조 링크
-
LRQ(LocalRunQueue):P에 종속되어 있는 Run Queue, 이LRQ에 실행 가능한 고루틴들이 적재된다P는LRQ로 부터 고루틴을 하나씩 Pop하고M에 할당하여 고루틴을 실행시킨다P마다 하나의LRQ를 가지고 있기 때문에 레이스 컨디션을 줄일 수 있는 효과가 있다고 한다LRQ가M이 가지고 있지 않은 이유는M의 개수가 증가할수록LRQ의 수도 비례적으로 증가하여 오버헤드가 커지는 구조이기 때문이다
-
GRQ(GlobalRunQueue):LRQ에 할당되지 못한 고루틴을 관리하는 Run Queue,LRQ적재되지 못한 고루틴들이 이GRQ에 들어가 관리된다고 보면 된다- 실행 상태의 고루틴은 한번에 최대 10ms까지 실행된다고 하는데, 10ms 동안 실행된 고루틴은 대기 상태로 변하고
GRQ로 적재된다 - 고루틴이 생성되는 시점에 모든 LRQ가 가득찬 경우에도
GRQ에 고루틴이 적재된다
- 실행 상태의 고루틴은 한번에 최대 10ms까지 실행된다고 하는데, 10ms 동안 실행된 고루틴은 대기 상태로 변하고
스케줄러 작동 원리
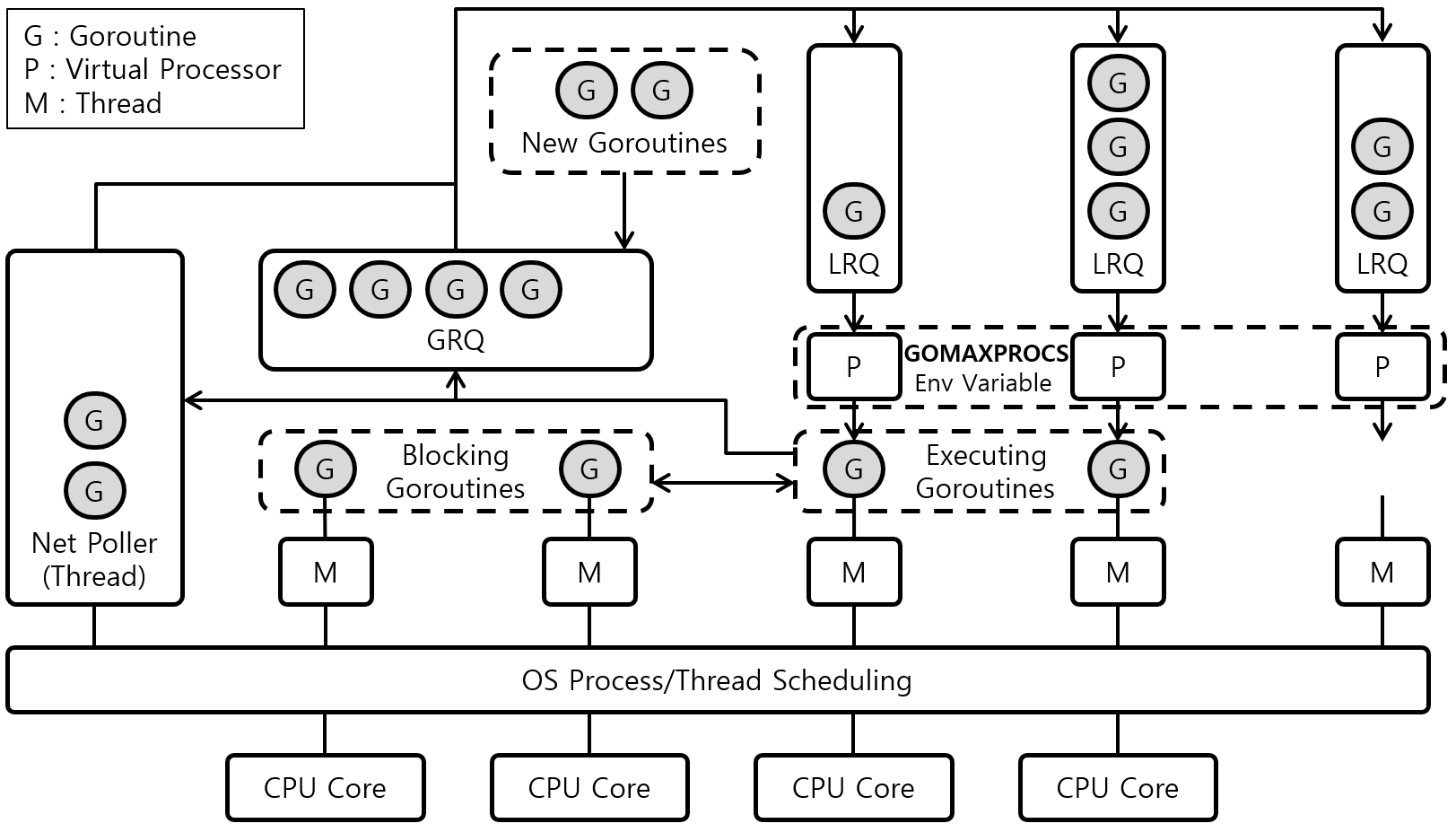
+) 이 블로그 글을 참고했습니다.
아시다시피 하나의 쓰레드는 하나의 작업을 실행할 수 있다. 각각의 작업들이 수행되는 간략한 과정을 설명하자면 하나의 M이 하나의 고루틴(작업)을 실행하고, 이미 실행중이던 고루틴이 작업을 마치거나 syscall을 했을 경우 Go 스케줄러는LRQ에서 대기중인 고루틴을 꺼내 다음 작업을 실행하고 새로 추가되는 작업(이미 돌아가고 있는 작업 혹은 새로운 고루틴)을 LRQ에 추가한다. 또한 스케줄러는 성능 향상을 위해서 아래와 같은 상황에서 스케줄링을 통해 최적화하는 작업이 있다.
syscall
로직을 실행하던 도중에 syscall(주로 I/O 작업 같은 행위 등)이 발생하게 되면 blocking이 발생되는데, 이 현상이 해당 작업을 처리하던 쓰레드에 영향을 주어 다음 작업을 처리할 수 없기 때문에 성능 저하의 원인이 될 수 있다. Go에서는 스케줄러가 작업을 멈추지 않고 계속 진행할 수 있도록 syscall이 발생한 고루틴을 다른 쓰레드로 넘기고 P의 LRQ에 적재되어 있던 다음 고루틴이 정상적으로 처리될 수 있도록 보장한다. 이후 syscall 처리가 끝난 고루틴은 잠시 넘겨주었던 P로 다시 적재되거나 GRQ에 적재된다.
다수의 고루틴은 소수의 쓰레드 위에서 동작한다. 즉 다중화(Multiplexing)되어 돌아간다고 앞서 언급 했었는데, 바로 위에서 설명한 과정의 Go 스케줄러의 스케줄링 덕분에 가능해진 것이다. 따라서 M에 바로 P(Context)가 붙어서 고루틴 간에 Context Switching이 발생하게 되는 구조로 여기서 P(Context)의 개수는 Go의 GOMAXPROCS라는 환경변수 값을 통해 조정이 가능하다.
Work Stealing(작업 가로채기)
M, P(Context)가 모든 작업을 마치게 되면 먼저 GRQ에 쌓여있는 고루틴을 가져오려 시도하고 이마저도 없으면 다른 P의 LRQ에서 절반의 고루틴(작업)을 가져온다(Steal). 작업의 불균형으로 인한 병목현상을 이러한 Work Stealing 기법을 통해 리소스를 더 효율적으로 사용하게 된다.
고루틴의 Context Switching 시점
앞선 내용에서 syscall과 같은 현상이 발생하게 되면 Context Switching이 이루어지는 것을 알 수 있었지만, 정확히 고루틴은 어떤 시점에서 Context Switching 작업이 발생하게 될까?
- unbuffered channel에 접근할 때(write or read)
- 시스템 I/O가 발생했을 때
- 메모리가 할당될 때
time.Sleep()Function 같은 해당 문맥에서 sleep 처리하는 로직이 실행될 때runtime.Gosched()Function 같은 로직이 실행될 때
마무리
다루지 못한 부족한 내용도 있고 고루틴과 고루틴의 스케줄링 기법에 관하여 확실하게 이해가 된 것은 아니지만 전체적인 흐름을 파악할 수 있었다. Go 언어가 동시성 개발에 대한 장점 요소들을 모두 다루진 못했지만 그 장점 중 한가지인 고루틴에 대하여 학습하면서 왜 고루틴을 사용하면 좋은지에 대한 이유를 알 수 있었고, Go 스케줄러를 학습하면서 운영체제와 연관된 내용이 포함되어 있어 같이 공부할 수 있던 계기였다.
참고
- https://d2.naver.com/helloworld/0814313
- https://ssup2.github.io/theory_analysis/Golang_Goroutine_Scheduling/
- https://velog.io/@kineo2k/고루틴은-어떻게-스케줄링되는가
- https://medium.com/curg/%EA%B3%A0%EB%A3%A8%ED%8B%B4-go-%EC%96%B8%EC%96%B4%EC%9D%98-%EB%8F%99%EC%8B%9C%EC%84%B1-%EB%AA%A8%EB%8D%B8-1045986cc001
- https://mainfunction.tistory.com/entry/GoGolang-고루틴goroutine-Deep-Dive
- https://tech.ssut.me/goroutine-vs-threads/
- https://sungjunyoung.github.io/posts/how-goroutine-works/
- http://golang.site/go/article/21-Go-%EB%A3%A8%ED%8B%B4-goroutine
- https://wooody92.github.io/os/%EB%A9%80%ED%8B%B0-%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4%EC%99%80-%EB%A9%80%ED%8B%B0-%EC%8A%A4%EB%A0%88%EB%93%9C/
- https://applefarm.tistory.com/105?category=926699
- https://kspsd.tistory.com/50
- https://www.crocus.co.kr/1255
