Hive
Hadoop기반의 데이터 웨어하우징 프레임워크
- 대량의 데이터를 관리하고 학습하기 위해 개발
- SQL기술로 HDFS에 저장된 대량의 데이터를 분석
- SQL의 특성상 복잡한 머신러닝 알고리즘을 구현하는 데는 적합하지 않지만 다양한 분석을 하는데 좋음
- HDFS에 데이터를 저장 -> MapReduce연산으로 원하는 데이터를 얻음
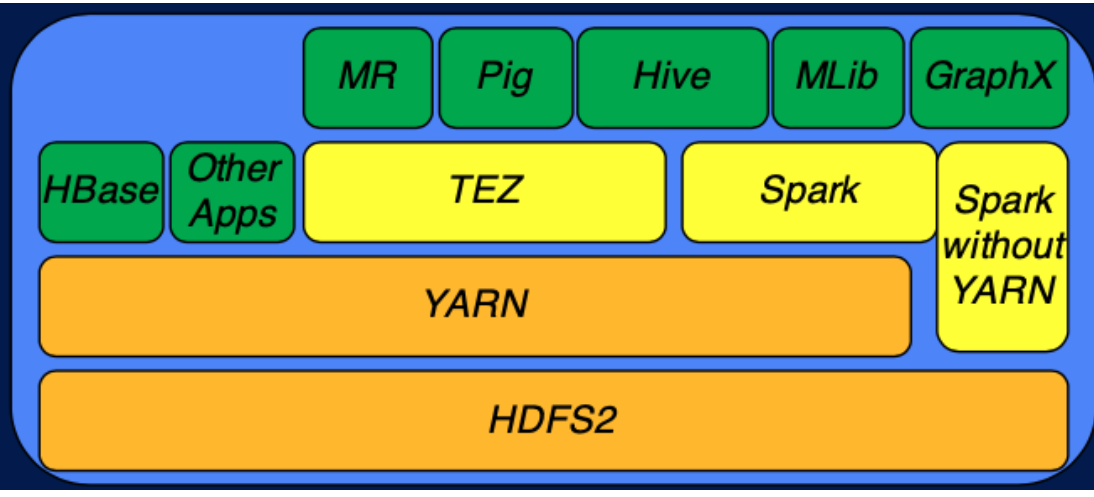
- MapReduce는 처리가 느리고, 사용하기 불편함- 이때 Pig와 Hive가 나옴
- Pig : 절차적언어
- Hive : SQL같은 선언적 언어
- Pig와 Hive 둘 다 데이터 조회 인터페이스 기술이기에 데이터 분석 작업의 속도를 높이지는 않음
- 이를 위해 HBase가 나옴
- Key, Value 데이터에 대한 빠른 입출력이 가능
- Hadoop기반 시스템에서 실시간으로 데이터 처리가 가능한 환경 제공
- 이를 위해 HBase가 나옴
- 이때 Pig와 Hive가 나옴
Hive 작동 방식
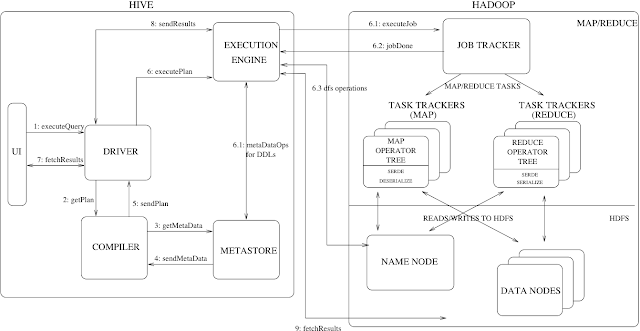
- 작성된 SQL쿼리는 MapReduce job으로 변환되어 하둡 클러스터에서 구동
- 내부적으로는 MapReduce프레임워크를 사용하는 것 - HDFS에 저장된 데이터에 구조를 입혀 데이터를 테이블로 구조화
- 해당 메타데이터(테이블 스키마)는 MetaStore에 저장됨
Metastore
- Hive에서 생성한 테이블 스키마를 저장하는 곳
- 실제 서비스용으로 MySQL과 같은 데이터베이스를 사용할 수 있다
Hive 실행엔진
- Hive를 이용해 쿼리 실행 시에 컴파일된 SQL을 실행엔진을 통해 수행
- MR, TEZ, Spark 중 하나를 설정해서 사용
Hive 실행 내부절차
Hive 설치
- 운영 중인 클러스터에 설치된 것과 동일한 버전의 hadoop이 local workstation에 설치되어 있으면 된다.
- Hive 설치
- workstation에서 .tar 파일을 품
% tar xzf apache-hive-x.y.x-bin.tar.gz- 사용자 경로에 hive를 넣으면 실행하기 편함
% export HIVE_HOME=~/sv/apache-hive-x.y.x.bin
% export PATH=$PATH:$HIVE_HOME/bin- hive 실행(hive shell 구동)
% hiveHive Shell
- HiveQL 명령어로 Hive와 상호작용하는 Hive의 기본도구
명령어
-f : 지정한 파일에 대해서만 hive명령어 실행
-e : sql문을 명령행에 직접입력
...
...
...Hive 설정
- conf/hive-site.xml에서 환경 설정(MetaStore의 환경 설정도 존재)
- conf/hive-default.xml이라는 hive의 기본값이 기록되어 있음

Cloud&Infra