Hadoop
1.Hive
Hadoop기반의 데이터 웨어하우징 프레임워크대량의 데이터를 관리하고 학습하기 위해 개발SQL기술로 HDFS에 저장된 대량의 데이터를 분석SQL의 특성상 복잡한 머신러닝 알고리즘을 구현하는 데는 적합하지 않지만 다양한 분석을 하는데 좋음작성된 SQL쿼리는 MapRedu
2.Hadoop EcoSystem

분산 시스템을 구성하는 다수의 소프트웨어들을 모은 공통 플랫폼Yarn상에서 복수의 분산 애플리케이션이 동작분산 파일 시스템Hadoop에서 처리되는 데이터는 대부분 HDFS에 저장데이터가 분산되어 중복적으로 여러 컴퓨터에 저장리소스 매니저CPU, 메모리등의 계산 리소스를
3.Hadoop 기본
성능, 편리 면에서 좋지만 비용이 많이 사용됨빅데이터 분석에 RDB는 비효율적핵심은 Scale-out!!!값싼 서버를 여러개 이용비싼 서버를 여러개 이용Name node를 제외하고 수평적 확장이 가능Hadoop HDFS에서 빅데이터에 맞게 Data Node 추가 가능H
4.Hive설치

알맞은 HIVE설치 파일 다운압축해제 후 이름 변경Hadoop 실행HDFS명령어를 이용해서 warehouse(metastore)를 생성하고 권한 설정스키마 초기화(현재 derby database 사용)테스트
5.HIVE MetaStore

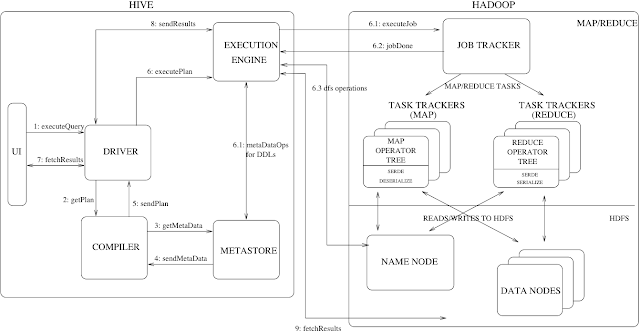
일반적인 SQL문과 유사한 HiveQL을 사용해서 MapReduce를 사용할 수 있게 해줌Client가 쿼리 실행Driver가 Compiler에게 쿼리플랜 요청Compiler가 쿼리를 Mapreduce코드로 변환이때 Metastore를 통해 MetaData를 가져와서
6.Spark
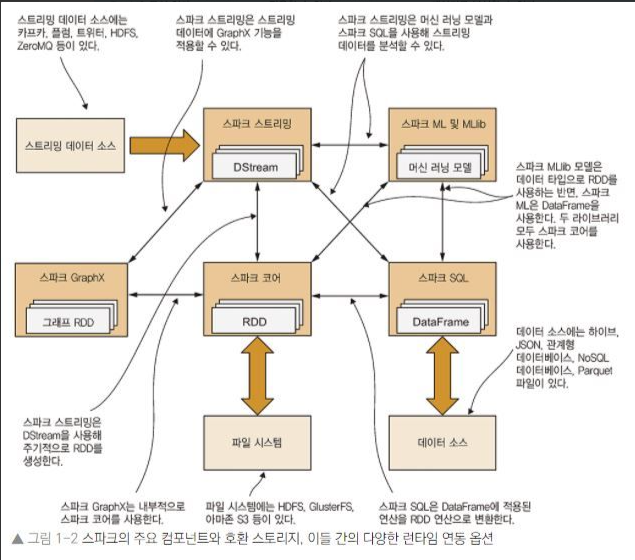
Map Reduce 보다 약 100배 빠른 속도로 같은 같은 작업 수행 가능(인메모리)Python, Java, Scala, R 지원단일 머신에서 처리할 수 있는 데이터셋에서는 부적합온라인 트랜잭션 처리에는 부적합, 일괄 처리 작업이나 온라인 분석 처리 작업에 적합매번