1. 특징
- Map Reduce 보다 약 100배 빠른 속도로 같은 같은 작업 수행 가능(인메모리)
- Python, Java, Scala, R 지원
- 단일 머신에서 처리할 수 있는 데이터셋에서는 부적합
- 온라인 트랜잭션 처리에는 부적합, 일괄 처리 작업이나 온라인 분석 처리 작업에 적합
- 매번 디스크에 저장하고 읽어들이는 MR과 달리 메모리에 캐시하고 읽어들일 수 있음
- MR보다 간결함
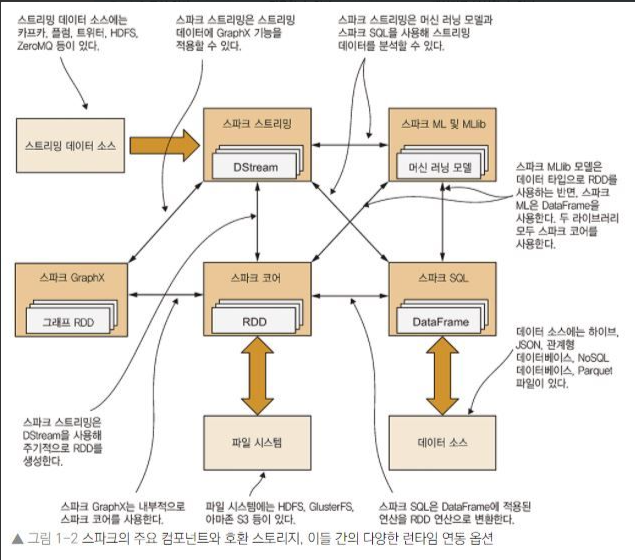
스파크 코어
- HDFS, GlusterFS, AWS S3 등 다양한 파일 시스템 접근 가능
- 공유 변수와 누적변수를 통해 컴퓨팅 노드 간에 정보 공유 가능
- 네트워킹, 보안, 스케쥴링, 데이터 셔플링 등의 기본 기능 구현
- RDD(Resilient Distributed Datasets)
- MR과 다르게 메모리에 저장하고 처리하면 속도가 빠르다는 것에서 나온 데이터셋
- 메모리의 특성상 중간에 오류가 나면 모든 데이터가 사라짐
- 이를 해결한 데이터 구조가 RDD
- 수정이 되지 않는 Read-Only 구조
- 제일 아래에 계속 설명
스파크 SQL
- 스파크와 HiveQL이 지원하는 SQL을 사용해 대규모 분산 정형 데이터를 다룰 수 있는 기능 제공
- JSON, Parquet, RDB 테이블, Hive 테이블 등등 사용 가능
- 쿼리 최적화 프레임워크 Catalys 제공
- BI도구 등 외부 시스템과 스파크 연동 가능한 아파치 Thrift 서버 제공
- 외부 시스템은 기존 JDBC 및 ODBC 프로토콜을 이용해 스파크 SQL 쿼리 실행 가능
스파크 스트리밍
- 실시간 스트리밍 데이터 처리 프레임워크
- HDFS, 아파치 Kafka, 아파치 flume, 트위터, ZeroMQ
- 장애 발생시 연산 결과 자동 복구
- 이산 스트림(Discretized Stream, DStream) 방식
- 다른 스파크 컴포넌트와 함께 단이 프로그램에서 사용해 실시간 처리연산, 머신러닝 작업, SQL연산, 그래프 연산 등을 통합 가능
스파크 MLlib
- 머신 러닝 알고리즘 라이브러리
- 아차피 Mahout의 기능을 대부분 구현
스파크 GraphX
- 정점과 간선으로 구성된 데이터 구조
- 그래프 이론에서 가장 중요한 알고리즘이 구현되어 있음
- 프리겔 제공
RDD
- 특징
- immutable, Read-only
- Datasource -> RDD, RDD -> RDD로만 변경이 가능함.- Lazy-Execution
- action이 실행되기전까지는 실행이 되지 않는다.
- 자원이 배치된 배치될 상황을 미리 고려하여 최적의 코스를 돌 수 있다.
- action이 실행되기전까지는 실행이 되지 않는다.
- Lazy-Execution
- 코드로 구현(개발시 자바를 사용함)
- Spark를 사용할려면 SparkContext 객체를 반드시 생성을 해야 된다.
SparkConf conf = new SparkConf().setAppName(appName).setMaster(local/spark);
JavaSparkContext sc = new JavaSparkContext(conf);- appName : cluster UI에서 보이는 Application Name
- master : spark, mesos, yarn cluster url, local mode
- cluster mode : 자원 관리 프레임워크
- local: local 환경에서 사용할수 있는 mode
- spark : spark standalone
Cloud&Infra