Beautiful soup를 이용한 코로나 확진자 사이트에서 웹 크롤링하기
from urllib.request import urlopen
url = "http://ncov.mohw.go.kr/"
page = urlopen(url)
html_bytes = page.read()
html = html_bytes.decode("utf-8")
from bs4 import BeautifulSoup
soup = BeautifulSoup(html,"html.parser")
inner,outer = soup.find_all("span","data")
inner.get_text() #'613'
outer.get_text() #'22'soup를 이용하여 span태그에서 class가 data인 것을 모두 가져오니 2개가 되고 이를 국내인 inner와 해외인 outer로 나누어 처리하고 이를
get_text()를 이용해 text부분만 가져오는 역할을 진행하여 613, 22로 진행한다.
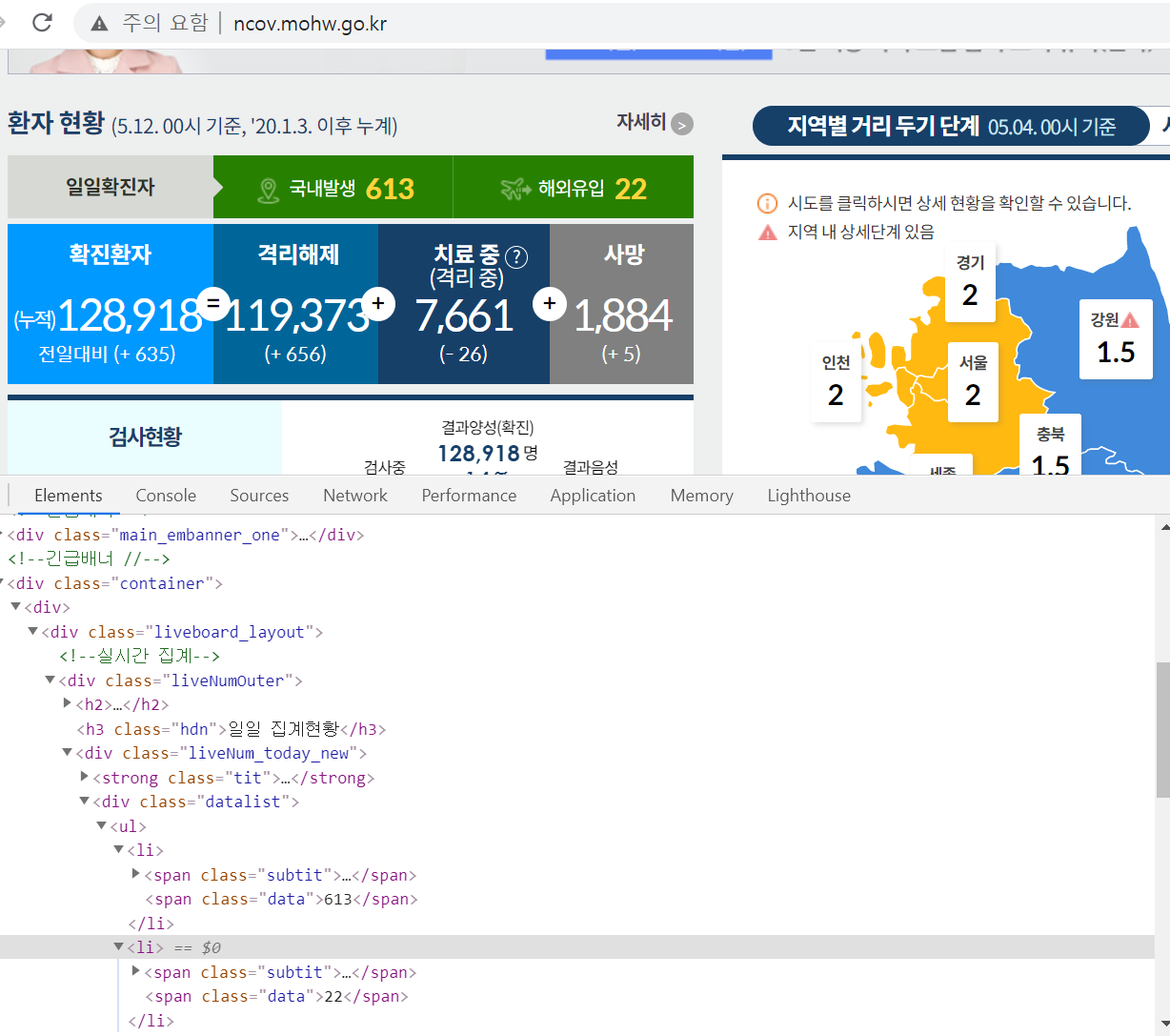
위와 같은 사이트에서 613과 22를 가져왔다. (크롤링)
오류 발생할 때

from bs4 import BeautifulSoup as bs 명령에 대해서 오류가 발생할 때도 있다.
BeautifulSoup를 설치해 주었음에도 발생하는 오류이다.
- 오류
modulenotfounderror: no module named 'bs4'
- 해결방법
intellj Run->Edit Configuration을 누른다.
해당 Interpreter를 잘 설정해야한다.
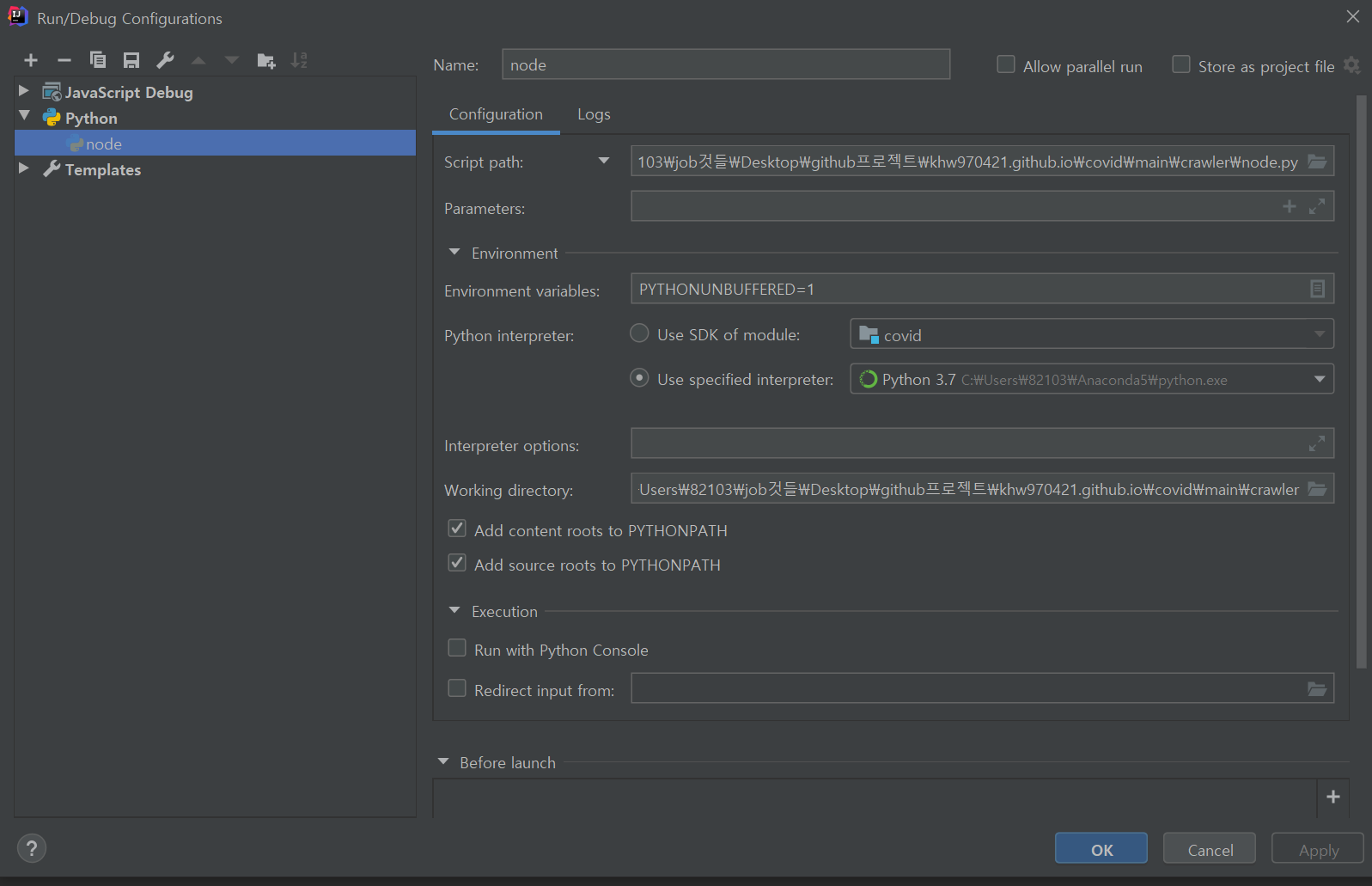
use specified interpreter를 눌러 해당되는 Python을 설정하고 처리해줘야 정상적으로 동작한다.
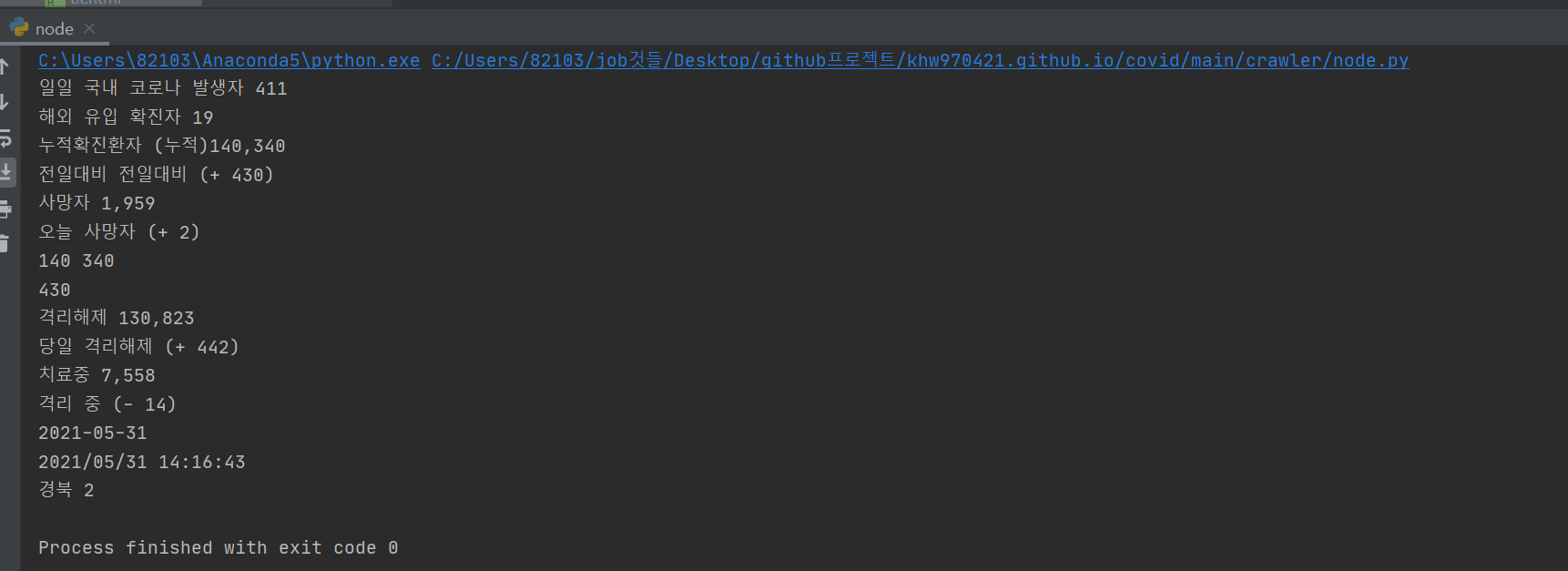
정리
python 환경 문제가 발생할 시
Edit Configuration부분 중요

나의 하루를 가능한 기억하고 즐기고 후회하지말자