데이터분석
1.Colab을 구글드라이브 연동하기
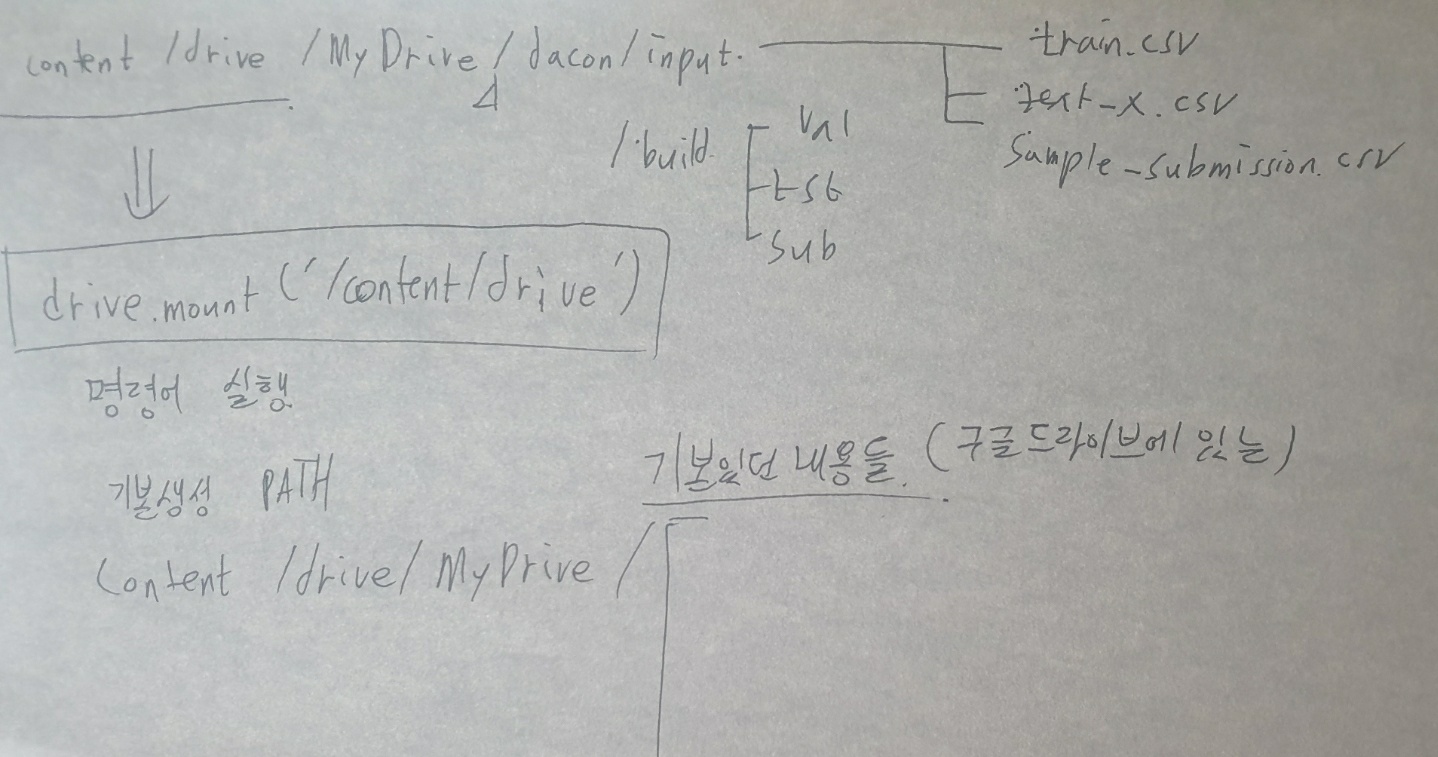
장점 : 일단 확실히 GPU여서 그런지 model을 돌리는데 빠르다. => jupyter로 돌릴땐 그렇게 느리더니...그러한 이유로 현재 팀원의 요청으로 Colab을 사용하게 되고 이를 통한 Path에러가 반복되어 이를 해결하는 글을 나중에도 기억할수 있게 작성하고자
2.Colab과 TPU and GPU

Colab을 내가 돌려보면서 내가 GPU인지 TPU인지 뭐를 통해 돌리는지도 모르고 시도한 것에 대하여 반성하잔 의미에서 글을 썼다. 별건 아니고 일단 CPU GPU TPU에 대한 개념에 대해서 알아보자.중앙 처리 장치 약어 CPU는 전자 회로로, 컴퓨터 프로그램의 명
3.웹으로 파이썬 결과 구현하기(1)
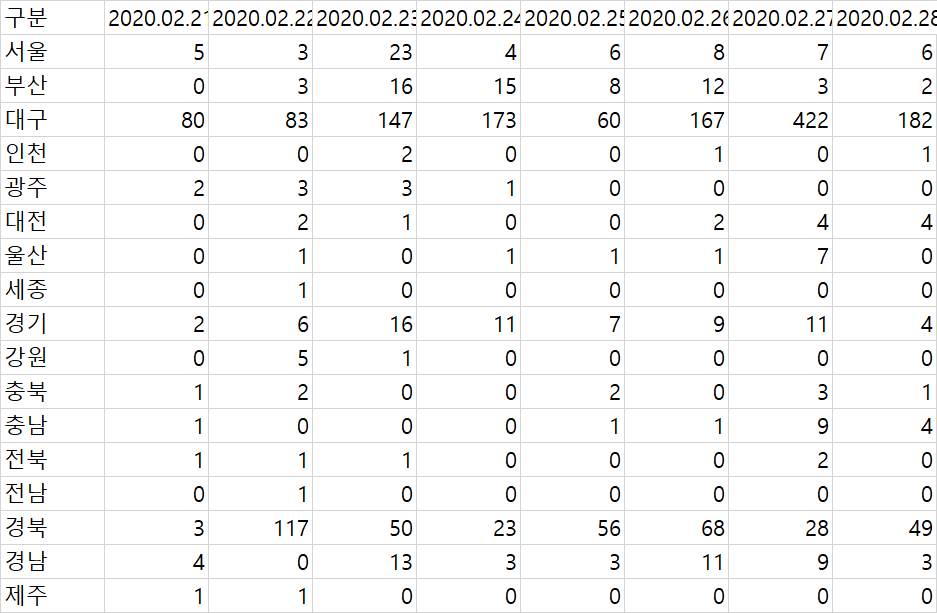
처음에는 csv 파일이 이런 형태로 혼자 csv 파일을 질본에서 얻은 데이터로 만들었었다. 위에 내용도 원래는 9시 16시 각각 나뉘었는데 date_time을 받아오는 형식에서 문제가 생겨서 그냥 2020.02.24 이런식으로 데이터를 처리하게 되었다. 그리고 합계를
4.웹으로 파이썬 결과 구현하기(2)
앞서 본 내용을 토대로 정리를 좀 하고자 한다.=> https://velog.io/@khw970421/%EC%9B%B9%EC%9C%BC%EB%A1%9C-%ED%8C%8C%EC%9D%B4%EC%8D%AC-%EA%B2%B0%EA%B3%BC-%EA%B5%AC%ED%
5.JS로 만드는 AI : TensorFlow.js - 4. 남의 모델을 이용하기 (생활코딩)
Tensorflow.js 사이트를 통해 우리는 다양한 이미 존재하는 모델을 사용 할 수 있다. 그 중 이미지를 검색하는 모델을 사용하고자 하는데 이미지 분류에 들어가서 위의 기본코드를 가져와서 실행에 옮긴다. 해당 코드의 script는 맨위는 tensorflow.js를
6.JS로 만드는 AI : 5.1~5.6
전체 코드 1) tensorflow.js를 사용하기 위해서는 배열을 tensor로 바꾸어 주어야한다. tf.tensor(배열) 2) 해당 모델에 따라 X(모델에 입력할 값의 갯수),Y(모델에 출력할 값의 갯수) 3) model.compile을 통해 실제로 모델을
7.JS로 만드는 AI : 6
MSE : 평균 제곱 오차 (log.loss)원인과 결과 데이터를 통한 모델을 예측했을때 실제 예측값과 결과간의 차이를 제곱하여 평균 낸 것 RMSE : 평균 제곱근 오차 (Math.sqrt(log.loss))위의 내용에서 제곱근을 추가한 것 ● log의 결과값의 경우
8.JS로 만드는 AI : TensorFlow.js - 7. 모델의 정체 (가중치, bias 구하기)
y = ax + b에서 주로 a는 가중치 b는 bias라고 한다.기본적으로 model을 통해 가져온 값은 tensor의 형태이므로 tensor에서 값을 가져오는 법을 배워야한다.model.getWeight()를 통해 mod변수로 가져온다.해당 내용의 0배열은 wei
9.JS로 만드는 AI : TensorFlow.js - 10.1. 여러개의 독립 변수(보스턴 집값)
관련 데이터는 열이 13개인 수많은 행을 가진 데이터의 독립변수와 집 값이라는 종속변수를 갖는다.cause_of를 통해 받아온 배열 데이터를 사용하기 위해 shape에서는 13열이므로 13으로 처리하고 units은 결과는 1개이므로 1로 한다.기존과 비슷한 방식으로 모
10.numpy 배열 기본사용
ex): 전체의 1번째 배열1: 1번째 배열의 전체 결국 같은 의미ex)ndarrayn,: => n행 추출ndarray:,m => m열 추출
11.python 웹 크롤링 (beautiful soup 라이브러리 + Intellj 오류 시 대처)
Beautiful soup를 이용한 코로나 확진자 사이트에서 웹 크롤링하기 >soup를 이용하여 span태그에서 class가 data인 것을 모두 가져오니 2개가 되고 이를 국내인 inner와 해외인 outer로 나누어 처리하고 이를 get_text()를 이용해 te
12.데이터 시각화 (D3.js)
d3.selectd3.selectAllselection.attrselection.dataselection.enterselection.appendselection.insertselection.removeselection.raiseselection.lowerselectio
13.데이터 시각화 (개념위주)
수많은 데이터를 유의미한 정보를 통해 시각화 하는 것ex) 대시보드 , 스크롤링 시각화(스크롤 하면서 시각적으로 변하는 것을 볼 수 있다. )데이터 형태를 부여하여 데이터를 한눈에 파악하며패턴/비교/포인트 파악이 가능하다데이터 ( 풍부하고 유용한 DATA )독자 ( 독