데이터분석
1.제로베이스 데이터 분석 스쿨3기

제로베이스 데이터 분석 스쿨 강의가 시작되었다. 직장과 병행하면서 잘 들을 수 있을 지 모르겠지만 포기하지 말고 끝까지 열심히 해보자 ! 직무 변경하여 이직 성공하고싶다 !
2.CH1)Database 설치(mysql)
#1. MY SQL 설치 > https://dev.mysql.com/downloads/windows/installer/8.0.html 원하는 버전으로 설치받으면 됨. +) connector가 안뜸 my sql홈페이지에 들어가서 connector를 따로 다운받거나 아래
3.CH2)Database 사용
여러사람이 공유하여 사용할 목적으로 체계화해 통합, 관리하는 데이터의 집합체 사용자와 DB사이에서 사용자의 요구에 따라 정보를 생성, 관리해주는 SW 서로간에 관계가 있는 데이터 테이블을 모아둔 저장공간(my sql도 이에해당) 데이터를 정의, 조작 , 제어 하기 위
4.CH3)TABLE 관련 기본 문법
테이블 생성 전 사전작업으로 db생성 먼저(ch1 참고)create database name default character set utf8mb4utf8mb4: 이모티콘 등도 저장이 가능한 버전table은 행(row), 열(column)으로 구성됨생성:create ta
5.CH4)select,insert, update,delete
insert into table name (컬럼1,2..)values(실제값1,2)컬럼순서대로 실제 값은 맞춰줘야함 모든 컬럼을 넣을 경우는 컬럼 생략 가능 (but table 생성시 컬럼순서대로 전체 데이터를 넣어줘야함)select 컬럼(\*전체) from table
6.CH5) order by
order by asc 오름차순 desc내림차순select \* from table where -- order by column asc/descorder by 정렬기준에 컬럼 여러개 설정 가능앞에 있을수록 정렬기준의 우선순위를 가짐 (1조건이 동일할경우 2정렬기준이 들
7.CH6,7)비교연산자, 논리연산자
where 조건에 사용하는 연산자들\*\*우선순위가 있으니 조건별 괄호로 묶어주는거 잊지말기= , > , < , >= , <= , <> , !=and, or, not , between a and b , in , like
8.CH8) UNION

UNION: 중복값 제거 후 출력UNION ALL: 중복값도 출력\*주의사항: 컬럼의 개수가 맞아야됨 종류는 상관 X▲컬럼 수 다를 시 오류 ▲컬럼의 종류가 다를 시 출력성공 ▲테이블 컬럼수 동일 시 \* 출력성공
9.CH9) JOIN
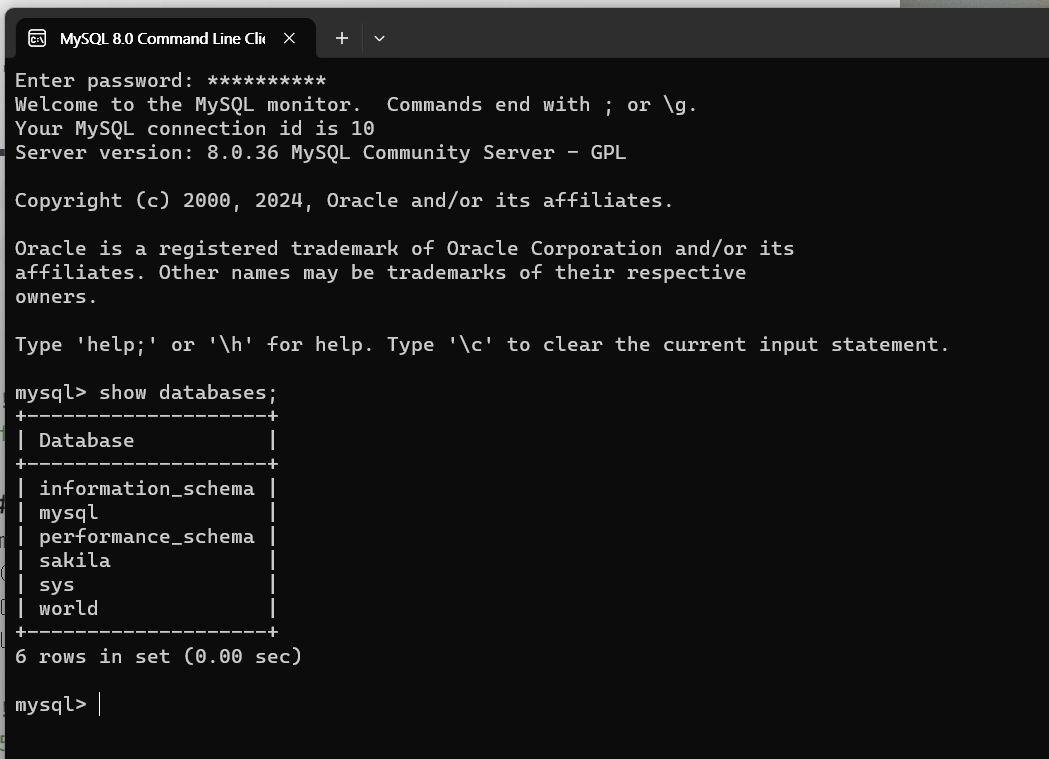
\-INNER JOIN :공통영역만 \-FULL OUTER JOIN: 양쪽 TABLE의 NULL값까지 (공통영역포함) \-LEFT JOIN: 왼쪽테이블의 NULL값포함 (공통영역포함) \-RIGNT JOIN: 오른쪽 테이블의 NULL값포함 (공통영역포함)※MY
10.CH10) CONCAT, DISTINCT, LIMIT
문자열 합치기 select a as alias from tableSNL 에 출연한 연예인의 신상정보(나이, 성별)와 출연정보(시즌-에피소드, 방송날짜), 소속사 정보를방송날짜 최신순으로 정렬하여 다음과 같이 검색하세요. ※ 컬럼 alias에 띄어쓰기가 들어가는경우 '
11.CH11) AWS RDS
rds 생성완료, 인바운드 편집으로 보안규칙 생성 후 외부접근 #1. rds접근 (window 환경에서 mysql커맨드로 rds접근을 실패해서 workbech로 실습) 추가버튼 눌러서 정보 넣어주면 됨
12.CH12) SQL FILE
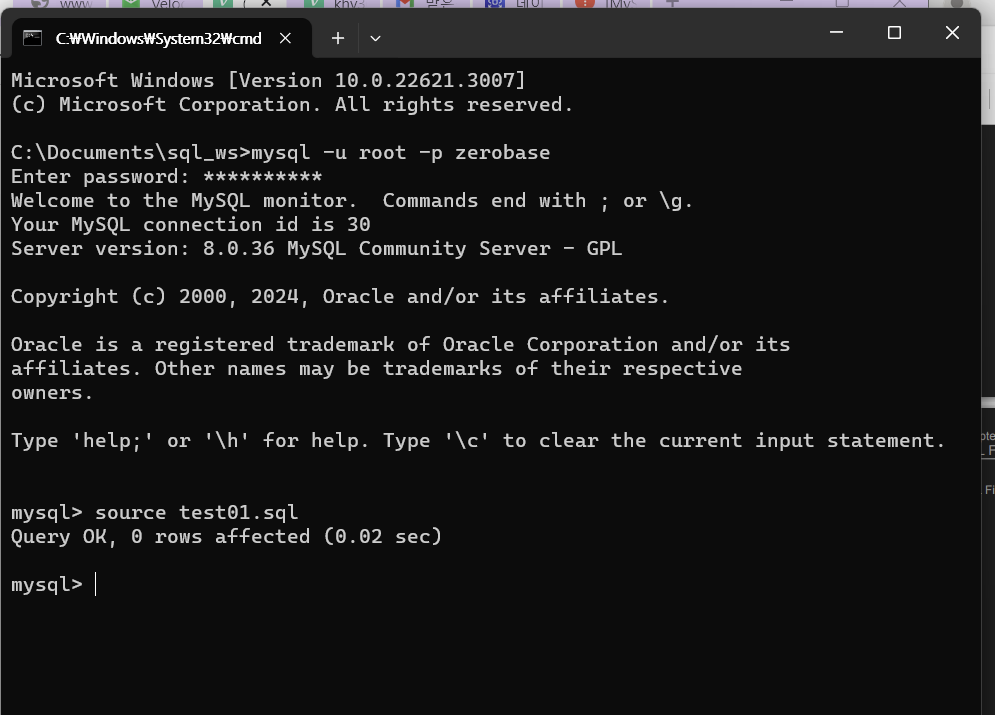
어제 cmd에서 mysql 디비 접속이 안되는 문제가 있어서 work bench에서 작업했는데, window에서 접근하려면 환경변수를 편집해야했다. 내pc->속성 ->고급시스템설정-> 환경변수 ->시스템 path에 mysql 경로 지정 잘등록되었다면 cmd에서 접속
13.Python 실습환경세팅(미니콘다, vscode)
1.웹브라우저 기본을 크롬으로 설정2.미니콘다 다운3.미니콘다 프롬프트 실행4.버전확인, 업데이트 진행5.실습환경 생성한번에 되는법이 없다... 패키지가 없다니까 패키지 받아주자 이러니까 바로 깔렸다! 굿굿실습때 많이쓰는거 깔기 (주피터)주피터 노트북 실행해서 아래 나
14.CH13)Python with Mysql
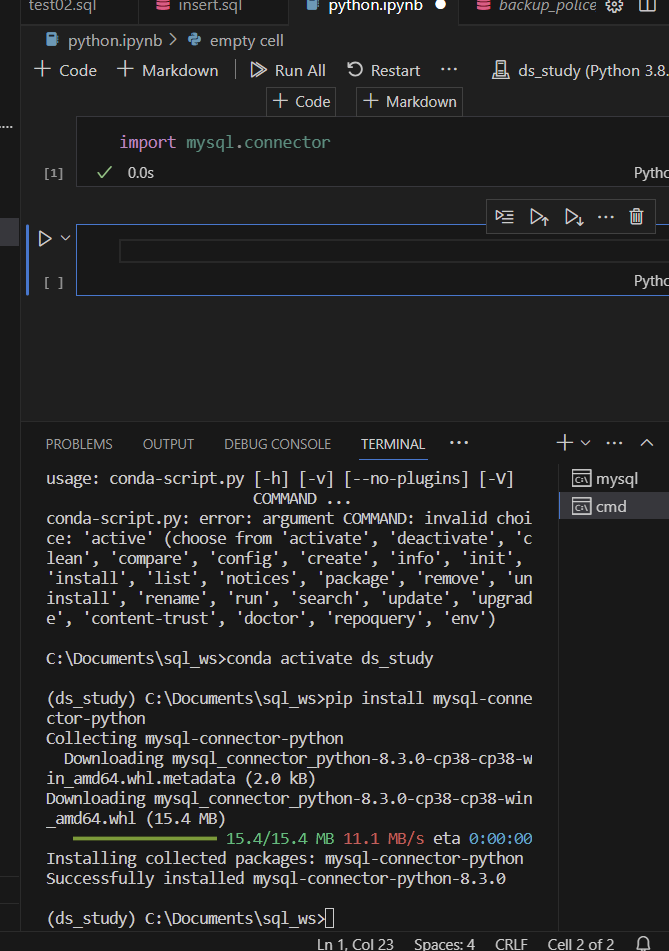
우선 ds study로 접속 실습으 ㄹ위해 이거 설치해줘야됨 import 에 문제 없으면 제대로 설치가 된것 m 눌러주면 이렇게 마크다운 쓸수 있음 터미널에서 생성된 거 확인 가능test04.sql준비왜,,,지역정보가 안들어오지 ,,?
15.CH14)Primary key, Foreign Key
1.primary key•테이블의 각 레코드를 식별• 중복되지 않은 고유값을 포함• NULL 값을 포함할 수 없음• 테이블 당 하나의 기본키를 가짐2.foreign key(외래키)한 테이블을 다른 테이블과 연결해주는 역할이며,참조되는 테이블의 항목은 그 테이블의 기본키
16.CH15)Aggregate Functions(집계함수)
1.count : 총 갯수2.sum: 합계를 계산해주는 함수3.avg: 평균을 계산해주는 함수4.min: 최소값5.max: 최대값6.first: 첫번째 결과값 리턴7.last: 마지막 결과값을 리턴8.group by ,having
17.CH16) Scalar Functions
사전준비 sandwich.csv 파일 준비 1.ucase : 대문자치환2.lcase: 소문자 치환3.mid: 문자열 부분반환 (substr같은애)4.length:문자열 길이 반환5.round: 지정한 자리 숫자 반올림6.now: 현재 날짜 및 시간 반환7.format
18.CH17)SQL Subquery
하나의 SQL 문 안에 포함되어 있는 또 다른 SQL 문• Subquery 는 괄호로 묶어서 사용• 단일 행 혹은 복수 행 비교 연산자와 함께 사용 가능• subquery 에서는 order by 를 사용X1.스카라 서브쿼리 (Scalar Subquery) - SELE
19.Tableau 1) 기본 시각화 방법
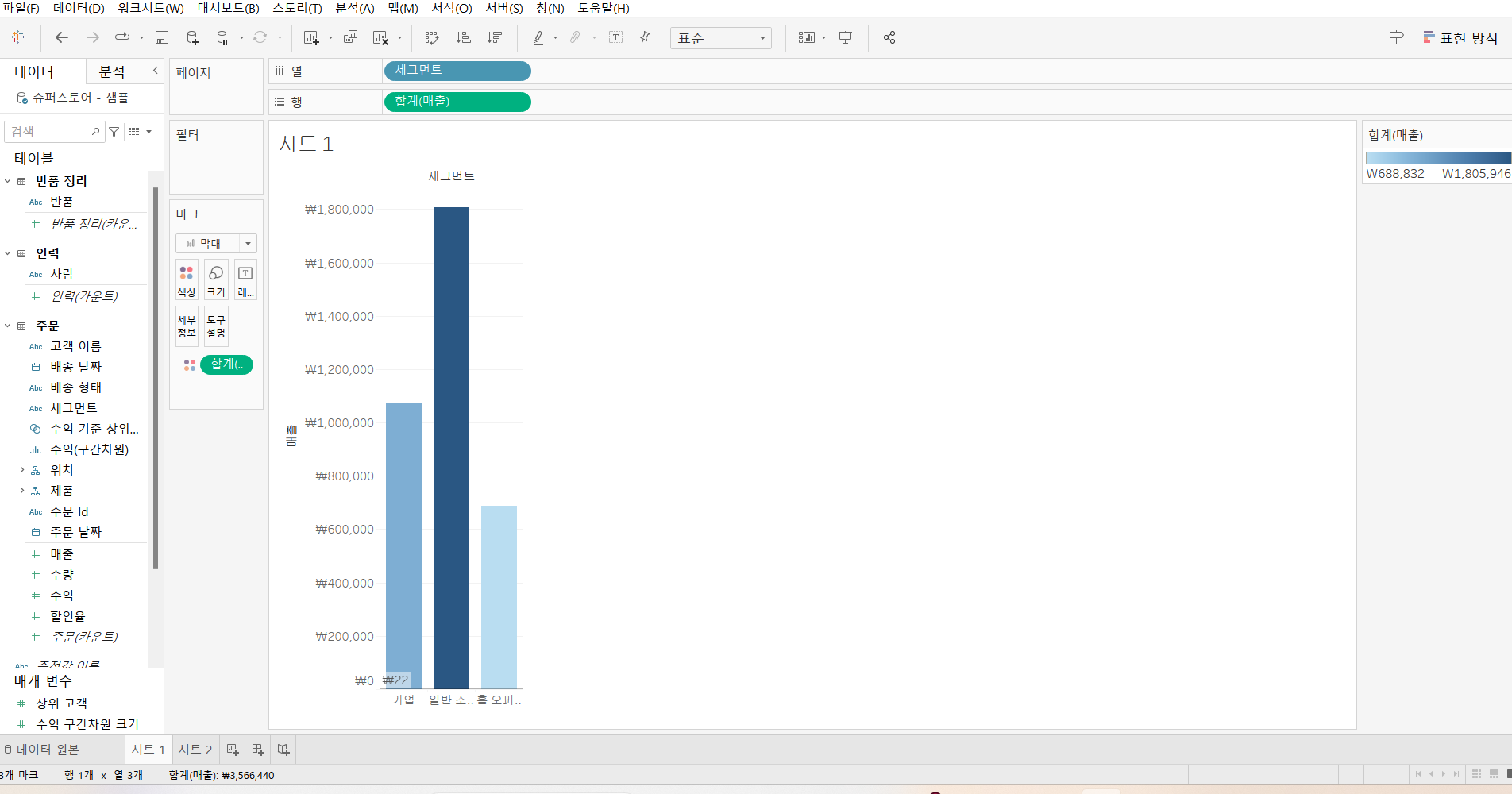
태블로 데스크탑 버전 설치 후 기본 샘플 데이터 확인 데이터 원본, 워크시트 확인워크시트 -> 마크, 작업표시줄, 데이터 , 분석 등등 확인 가능회색선 위 => 차원: 날짜 이름 지리적 데이터등 나눌 수 있는것 회색선 아래=>측정값: 측정할 수 있는 정량적 수치값 ㄴ연
20.Tableau 2
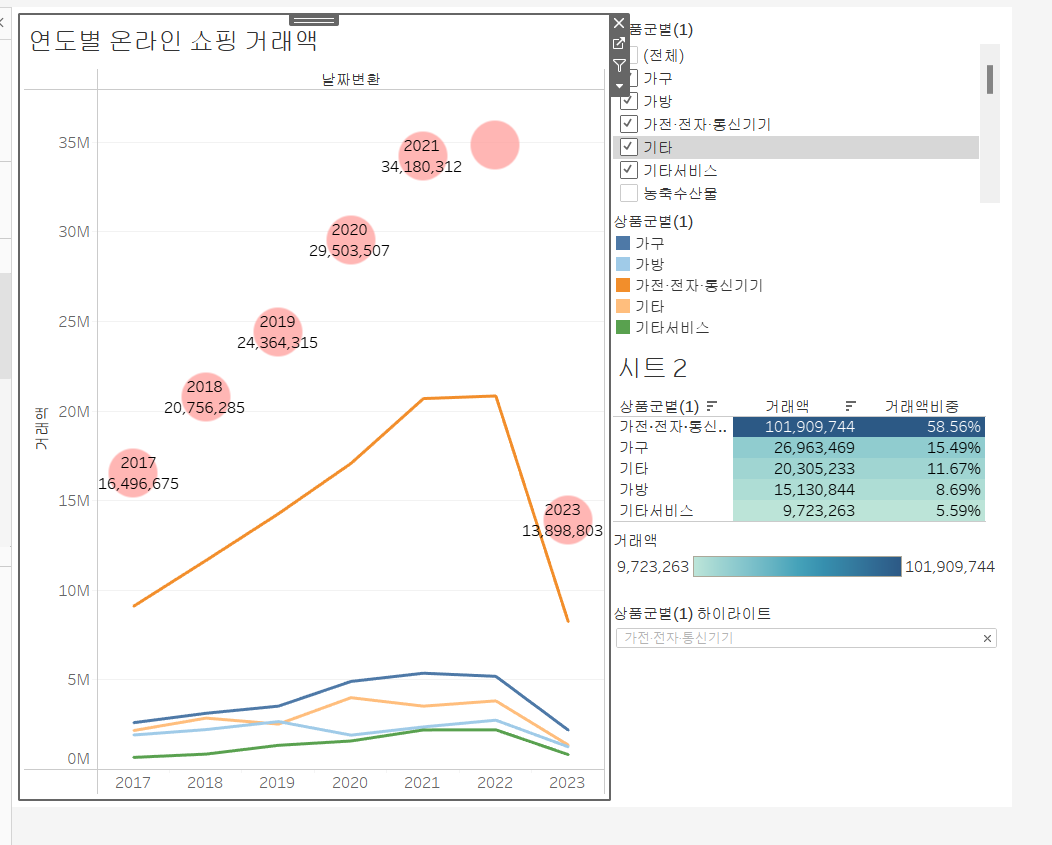
\-대시보드 >동작>동작필터위 : 선택을 할곳 / 아래 : 영향을 받는 곳 비슷한 계열의 시트들끼리 그룹화 하는 느낌
21.Looker studio 1
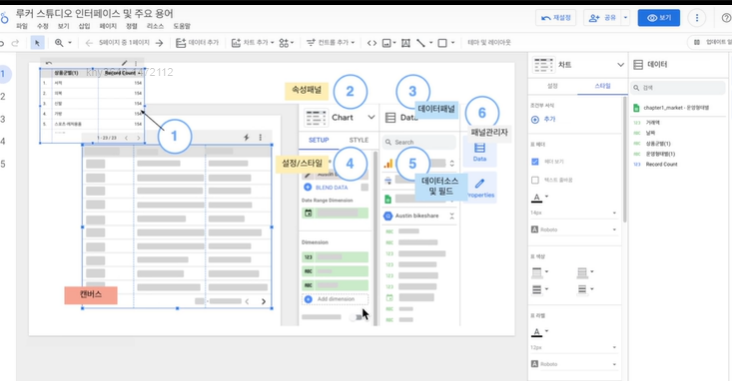
###측정 기준과 측정 항목 ###조건부 서식
22.이커머스 데이터를 통한 사업현황 파악
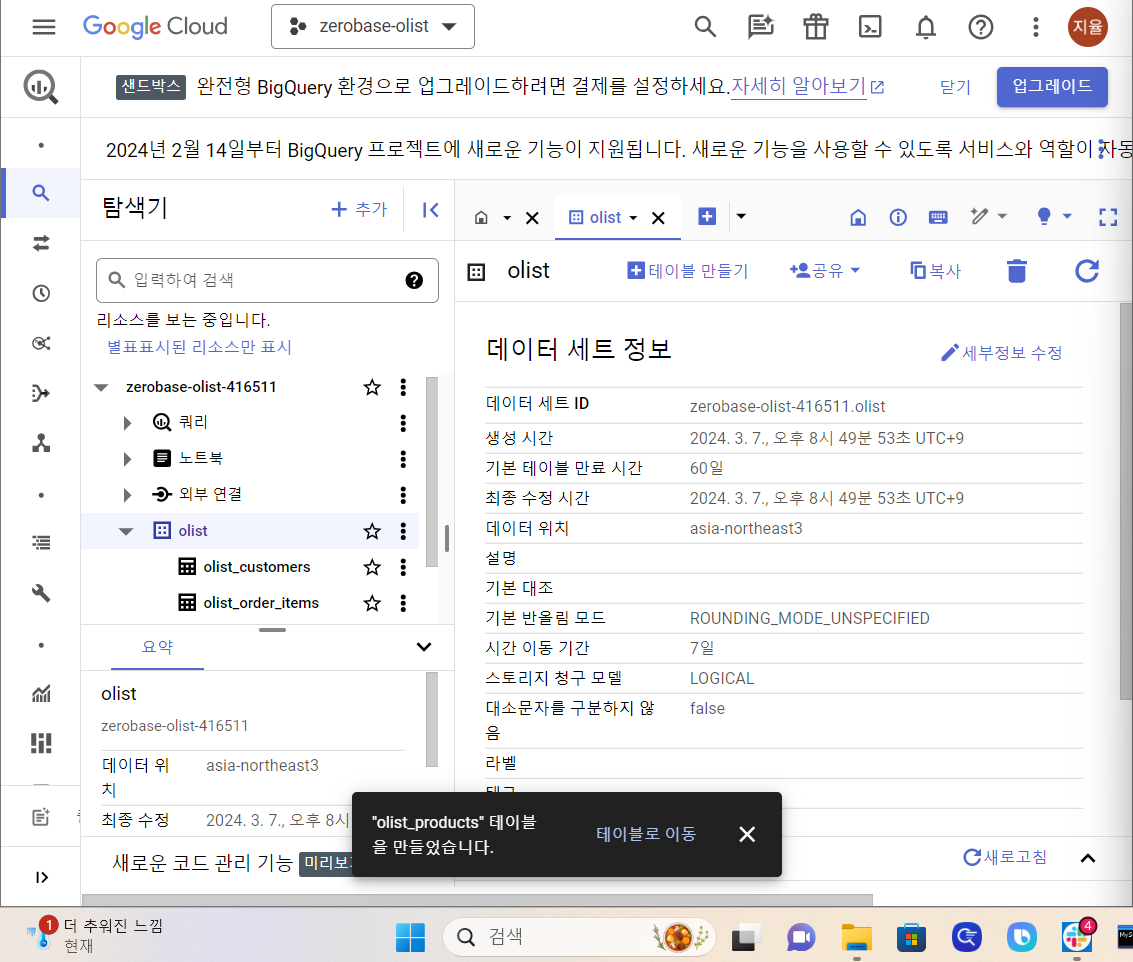
https://console.cloud.google.com/bigquery?sq=664481595609:c4c2ea2a817f4f1ab506b832e2c7a801https://console.cloud.google.com/bigquery?sq=66448
23.Chap3. 고객 행동 분석을 통한 서비스 헬스체크
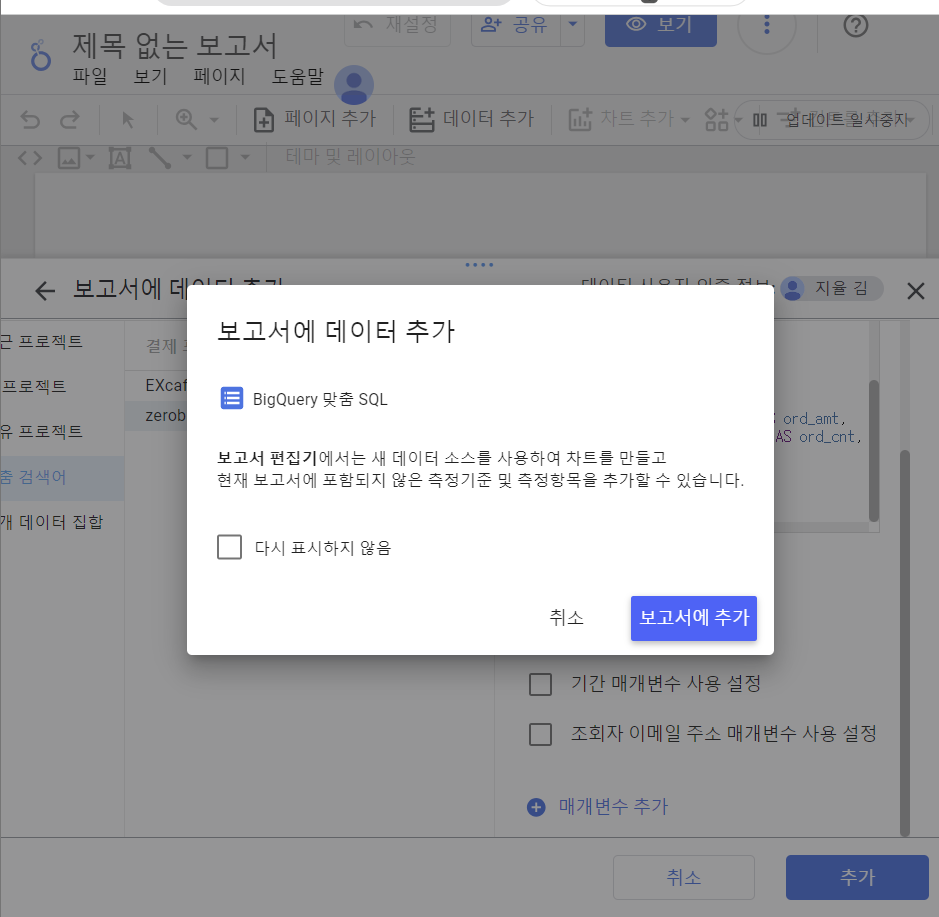
###looker에서 빅쿼리 쿼리문으로 데이터 가져오기 ##고객 행동 지표 ###AARRR 프레임워크 ###유입 ###활성화 ###유지 HR데이터를 통한 채용 기획
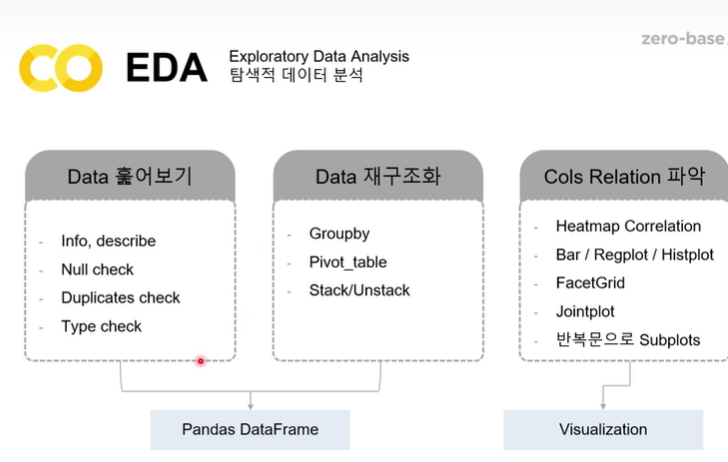
https://colab.research.google.com/drive/1oMdS5GR7oaMYIQlLW-HudMCScYwOIoTb?usp=drive_linkhttps://colab.research.google.com/drive/18MNtz9cU8jg
25.Spark/Pyspark
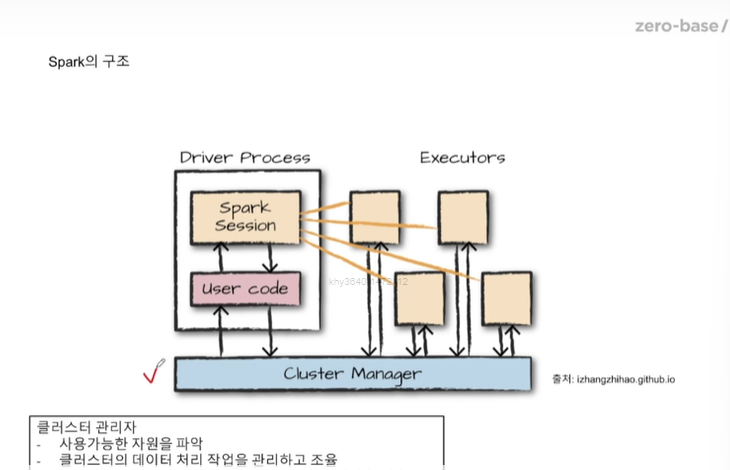
분산클러스터란?: 시스템의 전반적인 성능을 향상시키기 위해 계산 부하량을 여러 노드에서 분담하여 병렬처리하도록 구성하는 방식 spark spark의 병렬성은 파티션과 익스큐터의 갯수로 결정됨 \-> 쿼리를 날리거나 하는 것을 말함 pyspark (python+spark