C:\Documents\sql_ws>conda activate ds_study
(ds_study) C:\Documents\sql_ws>우선 ds study로 접속
(ds_study) C:\Documents\sql_ws>pip install mysql-connector-python 실습으 ㄹ위해 이거 설치해줘야됨
import 에 문제 없으면 제대로 설치가 된것
m 눌러주면 이렇게 마크다운 쓸수 있음
###1. create local connection
local= mysql.connector.connect(
host ="localhost" ,
user ="root",
password ="Supervis0r"
)###aws rds 연결
remote = mysql.connector.connect(
host ="엔드포인트" ,
port='3306',
user ="admin",
password =""
)##close database
local.close()
remote.close()##예제1
#Local Mysql 의 zerobase에 연결
local= mysql.connector.connect(
host ="localhost" ,
user ="root",
password ="Supervis0r",
database="zerobase"
)##예제2 aws rds의 zerobase에 연결
###aws rds 연결
remote = mysql.connector.connect(
host ="엔드포인트" ,
port='3306',
user ="admin",
password ="Supervis0r",
database="zerobase"
)##Execute 해보기
remote = mysql.connector.connect(
host ="엔드포인트" ,
port='3306',
user ="admin",
password ="Supervis0r",
database="zerobase"
)
cur =remote.cursor()
cur.execute("CREATE TABLE sql_file (id int, filename varchar(16))")
remote.close()터미널에서 생성된 거 확인 가능
mysql> show tables;
+--------------------+
| Tables_in_zerobase |
+--------------------+
| celeb |
| crime_status |
| police_station |
| snl_show |
| sql_file |
| test |
| test1 |
| test2 |
+--------------------+
8 rows in set (0.01 sec)
mysql> desc sql_file
-> ;
+----------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+-------------+------+-----+---------+-------+
| id | int | YES | | NULL | |
| filename | varchar(16) | YES | | NULL | |
+----------+-------------+------+-----+---------+-------+
2 rows in set (0.01 sec)
##삭제 해보기
remote = mysql.connector.connect(
host ="database-1.c7kgisgcqpwc.ap-northeast-2.rds.amazonaws.com" ,
port='3306',
user ="admin",
password ="Supervis0r",
database="zerobase"
)
cur =remote.cursor()
cur.execute("drop TABLE sql_file ")
remote.close()mysql> show tables;
+--------------------+
| Tables_in_zerobase |
+--------------------+
| celeb |
| crime_status |
| police_station |
| snl_show |
| test |
| test1 |
| test2 |
+--------------------+
7 rows in set (0.01 sec)
mysql> desc sql_file
-> ;
ERROR 1146 (42S02): Table 'zerobase.sql_file' doesn't exist##execute sql file
#test03.sql 미리 생성해두기
#CREATE TABLE sql_file
#(
# id int,
# filename varchar(16)
#);
remote = mysql.connector.connect(
host ="database-1.c7kgisgcqpwc.ap-northeast-2.rds.amazonaws.com" ,
port='3306',
user ="admin",
password ="Supervis0r",
database="zerobase"
)
cur =remote.cursor()
sql =open("test03.sql").read()
cur.execute(sql)
remote.close()test04.sql준비
INSERT INTO sql_file VALUES(1, "test01.sql");
INSERT INTO sql_file VALUES(2, "test02.sql");
INSERT INTO sql_file VALUES(3, "test03.sql");
INSERT INTO sql_file VALUES(4, "test04.sql");
##sql file 안에 쿼리가 여러개 존재하는 경우
remote = mysql.connector.connect(
host ="database-1.c7kgisgcqpwc.ap-northeast-2.rds.amazonaws.com" ,
port='3306',
user ="admin",
password ="Supervis0r",
database="zerobase"
)
cur =remote.cursor()
sql =open("test04.sql").read()
#쿼리가 여러개일땐 아래처럼 multi를 써줘야 함 실행결과 보기위해 for문 돌림
#cur.execute(sql, multi=True)
for result_iterator in cur.execute(sql, multi=True):
if result_iterator.with_rows:
print(result_iterator.fetchall())
else:
print(result_iterator.statement)
remote.commit()
remote.close()결과
INSERT INTO sql_file VALUES(1, "test01.sql")
INSERT INTO sql_file VALUES(2, "test02.sql")
INSERT INTO sql_file VALUES(3, "test03.sql")
INSERT INTO sql_file VALUES(4, "test04.sql")
mysql> select * from sql_file
-> ;
+------+------------+
| id | filename |
+------+------------+
| 1 | test01.sql |
| 2 | test02.sql |
| 3 | test03.sql |
| 4 | test04.sql |
+------+------------+
4 rows in set (0.03 sec)
##Fetch All 쿼리를 실행할때 데이터가 있는경우 보기위해 변수에 담아주는거
remote = mysql.connector.connect(
host ="database-1.c7kgisgcqpwc.ap-northeast-2.rds.amazonaws.com" ,
port='3306',
user ="admin",
password ="Supervis0r",
database="zerobase"
)
#읽어올 데이터 양이 많은 경우 buffered=True
cur =remote.cursor(buffered=True)
cur.execute("select * from sql_file")
result = cur.fetchall()
#fechtall() 만 하면 다같이 찍히고 for문쓰면 row마다 찍힘
for result_iterator in result:
print(result_iterator)
remote.commit()
remote.close()(1, 'test01.sql')
(2, 'test02.sql')
(3, 'test03.sql')
(4, 'test04.sql')#검색 결과를 PANDAS로 읽기
import pandas as pd
df=pd.DataFrame(result)
df.head()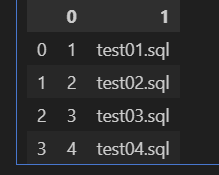
#csv를 pandas로 읽어와서 데이터 확인
import pandas as pd
df=pd.read_csv("police_station.csv")
df.head()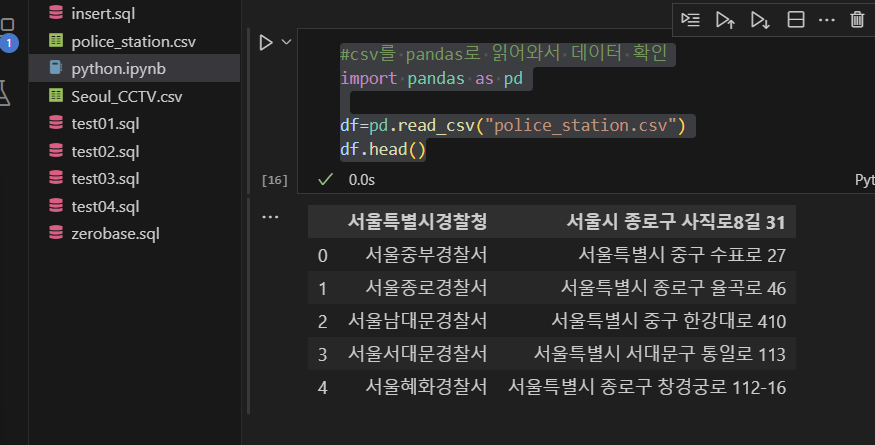
##위의 csv파일을 db에 insert하기
conn = mysql.connector.connect(
host ="database-1.c7kgisgcqpwc.ap-northeast-2.rds.amazonaws.com" ,
port='3306',
user ="admin",
password ="Supervis0r",
database="zerobase"
)
cursor = conn.cursor(buffered=True)
sql ="INSERT INTO police_station VALUES (%s,%s)"
for i, row in df.iterrows():
cursor.execute(sql, tuple(row))
print(tuple(row))
conn.commit() 
##결과확인
cursor.execute("SELECT * FROM police_station")
result = cursor.fetchall()
for row in result:
print(row)
#검색 결과를 Padas로 읽기
df = pd.DataFrame(result)
df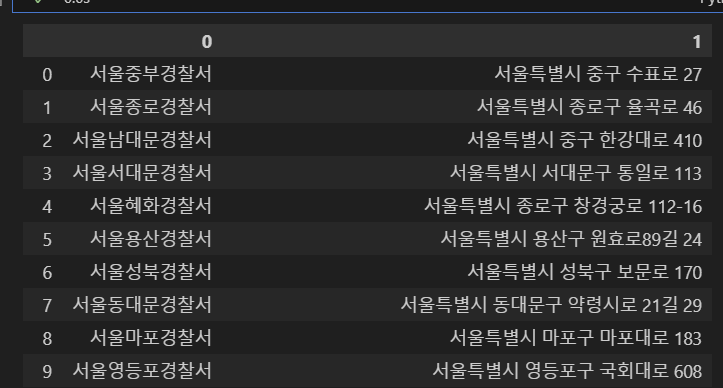
#한글깨질때
import pandas as pd
df=pd.read_csv('2020_crime.csv',encoding='euc-kr')
df.head()#2020_crime csv파일을 db에 crime_status table에 insert하기
import mysql.connector
conn = mysql.connector.connect(
host ="database-1.c7kgisgcqpwc.ap-northeast-2.rds.amazonaws.com" ,
port='3306',
user ="admin",
password ="Supervis0r",
database="zerobase"
)
import pandas as pd
df=pd.read_csv('2020_crime.csv',encoding='euc-kr')
df.head()
sql="""insert into crime_status values("2020",%s,%s,%s,%s)"""
cursor=conn.cursor(buffered=True)
for i, row in df.iterrows():
cursor.execute(sql, tuple(row))
print(tuple(row))
conn.commit()
cursor.execute("select *from crime_status")
result=cursor.fetchall()
for row in result:
print(row)
df- pd.DataFrame(result)
df.head()
conn.close()#2020_crime csv파일을 db에 crime_status table에 insert하기
import mysql.connector
conn = mysql.connector.connect(
host ="database-1.c7kgisgcqpwc.ap-northeast-2.rds.amazonaws.com" ,
port='3306',
user ="admin",
password ="Supervis0r",
database="zerobase"
)
#csv 읽기
import pandas as pd
df=pd.read_csv('2020_crime.csv',encoding='euc-kr')
df.head()#밖에 큰따옴표" 썻으면 안에 ' 작은따옴표 쓰는거 잊지말기
sql="insert into crime_status values('2020',%s,%s,%s,%s)"
cursor=conn.cursor(buffered=True)
for i, row in df.iterrows():
cursor.execute(sql, tuple(row))
print(tuple(row))
conn.commit()왜,,,지역정보가 안들어오지 ,,?
#실습
#cctv csv파일을 db에 cctv table에 insert하기
import mysql.connector
conn = mysql.connector.connect(
host ="database-1.c7kgisgcqpwc.ap-northeast-2.rds.amazonaws.com" ,
port='3306',
user ="admin",
password ="Supervis0r",
database="zerobase"
)#csv 읽기
import pandas as pd
df=pd.read_csv('Seoul_CCTV.csv',encoding='utf-8')
df.head()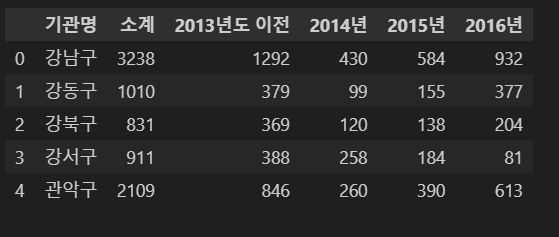
#테이블만들기
sql="create table cctv (기관명 varchar(8), 소계 int , 2013년도이전 int, 2014년 int, 2015년 int, 2016년 int )"
cursor =conn.cursor(buffered=True)
cursor.execute(sql)#데이터 insert
sql="insert into cctv values( %s, %s , %s , %s , %s, %s )"
cursor=conn.cursor(buffered=True)
for i, row in df.iterrows():
cursor.execute(sql, tuple(row))
print(tuple(row))
conn.commit()
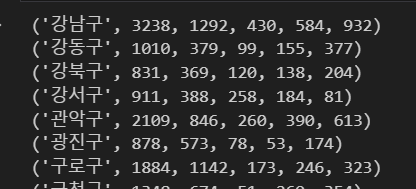
cursor.execute("select * from cctv")
result=cursor.fetchall()
for row in result:
print(row)
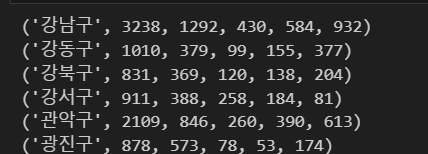
df= pd.DataFrame(result)
df.head()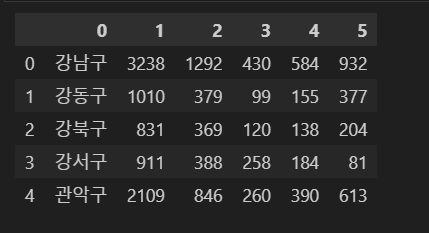
conn.close()
김지율