DFS?
깊이 우선 탐색
- 루트 노드(혹은 다른 임의의 노드)에서 시작해서 다음 분기(branch)로 넘어가기 전에 해당 분기를 완벽하게 탐색하는 방법
- 모든 노드 방문하고자 할 때 주로 사용
- 그래프에서 깊은 부분을 우선적으로 탐색하는 알고리즘
- BFS보다 간단하며 BFS에 비해 느리다
- 스택 구조나 재귀함수를 이용
특징
- 자기 자신을 호출하는 순환 알고리즘 형태
- 어떤 노드를 방문했는 지 여부를 반드시 검사해야한다. (무한 루프 위험)
BFS?
너비 우선 탐색
- 루트 노드(혹은 다른 임의의 노드)에서 시작해서 인접한 노드를 먼저 탐색하는 방법
- 두 노드 사이의 최단 경로 혹은 특정 경로를 찾고 싶을 때 사용
- 깊이가 1인 모든 노드를 방문하고 깊이가 2인 모든 노드 탐색 그 후 +1하며 계속 탐색하며 방문할 곳이 없으면 탐색 마침
- 큐 자료구조를 이용한다.
특징
- 단계별로 탐색하는 개념
- 재귀적으로 작동하지 않는다.
- 어떤 노드를 방문했는 지 여부를 반드시 검사해야한다. (무한 루프 위험)
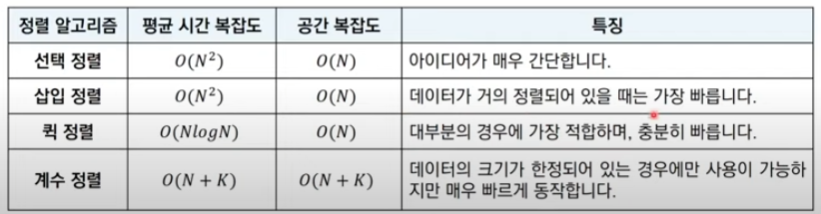
정렬
선택 정렬
총 N개일 때 처리되지 않은 데이터 중 가장 작은 수 앞으로 보냄

시간복잡도 : O(N²)
삽입 정렬
첫 데이터는 정렬이 되었다 생각하고 나머지 원소들의 자리를 찾아 삽입하는 정렬
시간 복잡도 : 최선 O(N) / 최악 O(N²)
퀵 정렬
- 기준 데이터(피벗)을 설정하고 왼쪽에서 시작해 피벗보다 큰 데이터와 오른쪽에서 시작한 작은 데이터를 찾아 위치를 바꾼다.
- 데이터가 엇갈릴 경우(이미 왼쪽에 작은 데이터가 있는 경우) 피벗과 작은 데이터의 위치를 바꾼다.
- 피벗을 기준으로 데이터를 묶어 반복한다.
시간복잡도 : 최선 O(NlogN) / 최악 O(N²)
계수 정렬
데이터가 양의 정수일 때 사용
1. 가장 작은 데이터부터 큰 데이터까지 범위가 담길 수 있는 리스트 생성
2. 데이터를 하나씩 읽으면서 데이터와 같은 인덱스의 값을 1 증가
추가적인 메모리 공간 필요
시간복잡도 : O(N)

차근차근