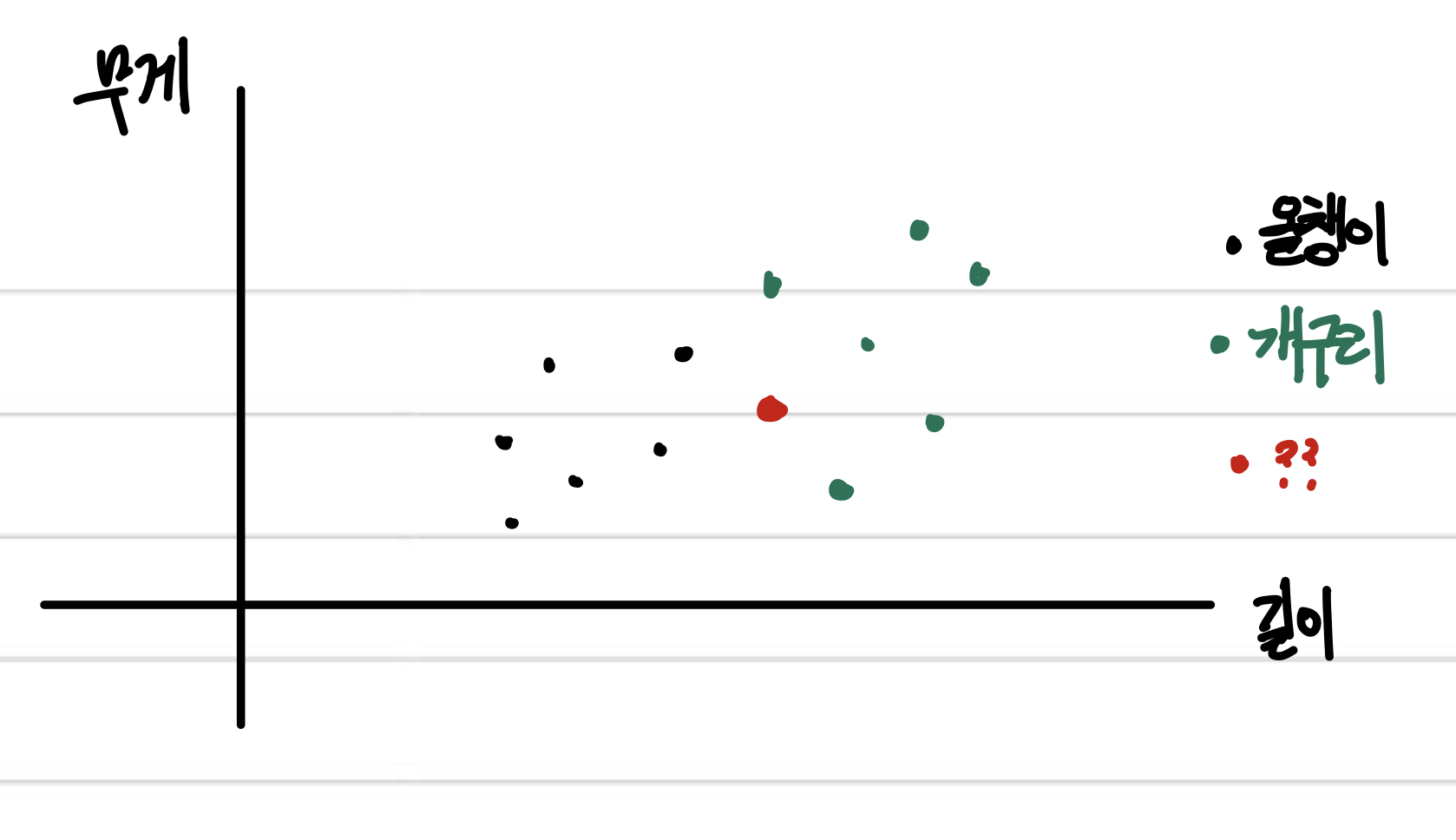
1. k-최근접 이웃 알고리즘이란?
k-최근접 이웃 알고리즘 (k-Nearest Neighbor aka k-NN)은 분류 (Classification) 알고리즘으로, 가장 간단하게 말하면 새로운 데이터 주변 애들을 보고 새로운 놈이 어떤 놈인지 분류하는 것이다.
이 때 는 주변 몇 개의 데이터를 볼 것인지를 뜻하는 매개변수가 된다.
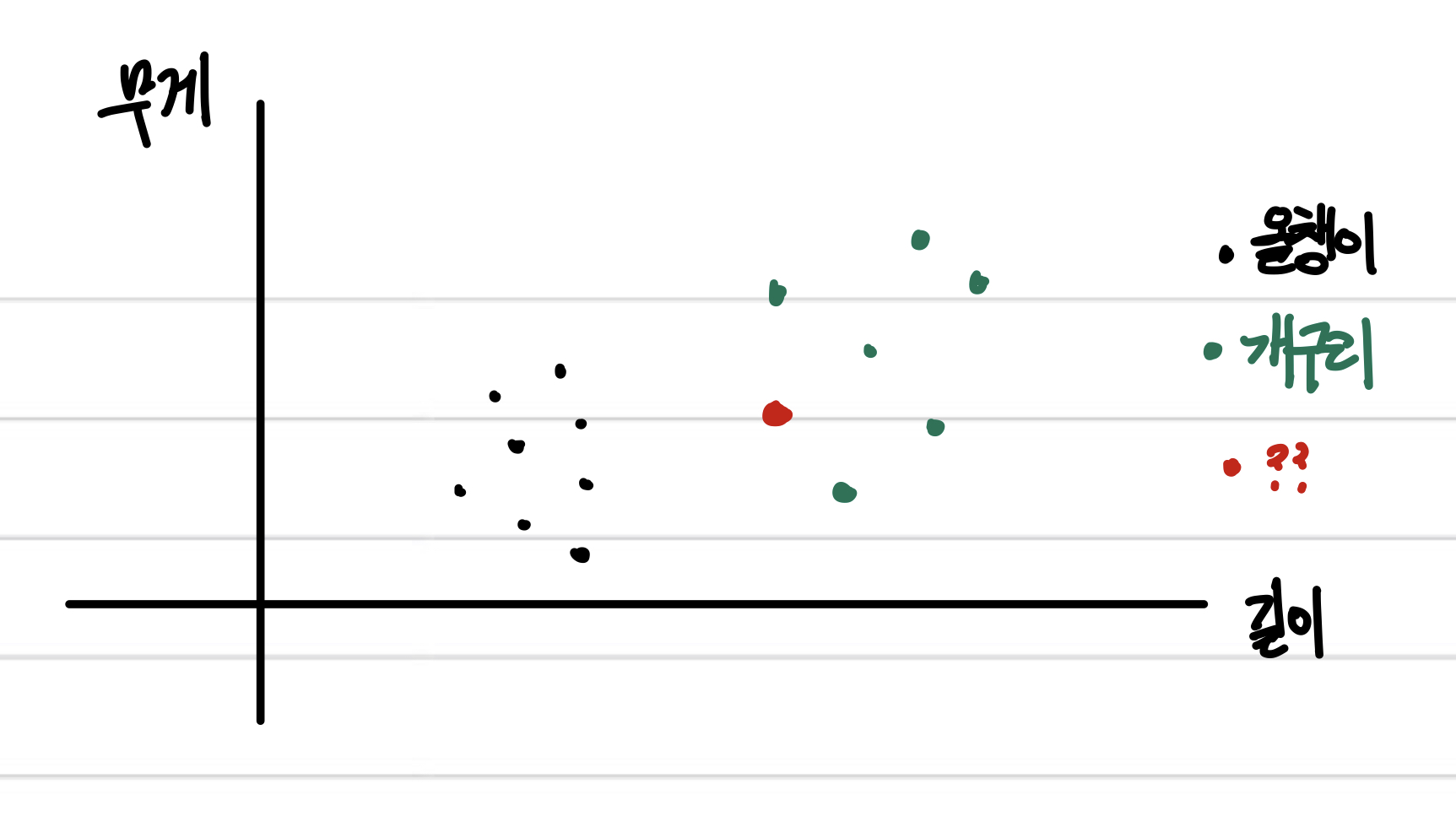
위 그림에서 까만 점이 올챙이, 초록 점이 개구리라고 하자.
그러면 빨간 놈의 정체는 무엇일까? 직관적으로 당연히 개구리일 것이다.
k-최근접 이웃 알고리즘은 이처럼 가장 가까운 데이터를 참고해서 데이터의 정체를 분류한다.
이 '가까움' 에는 주로 유클리드 거리를 이용한다.
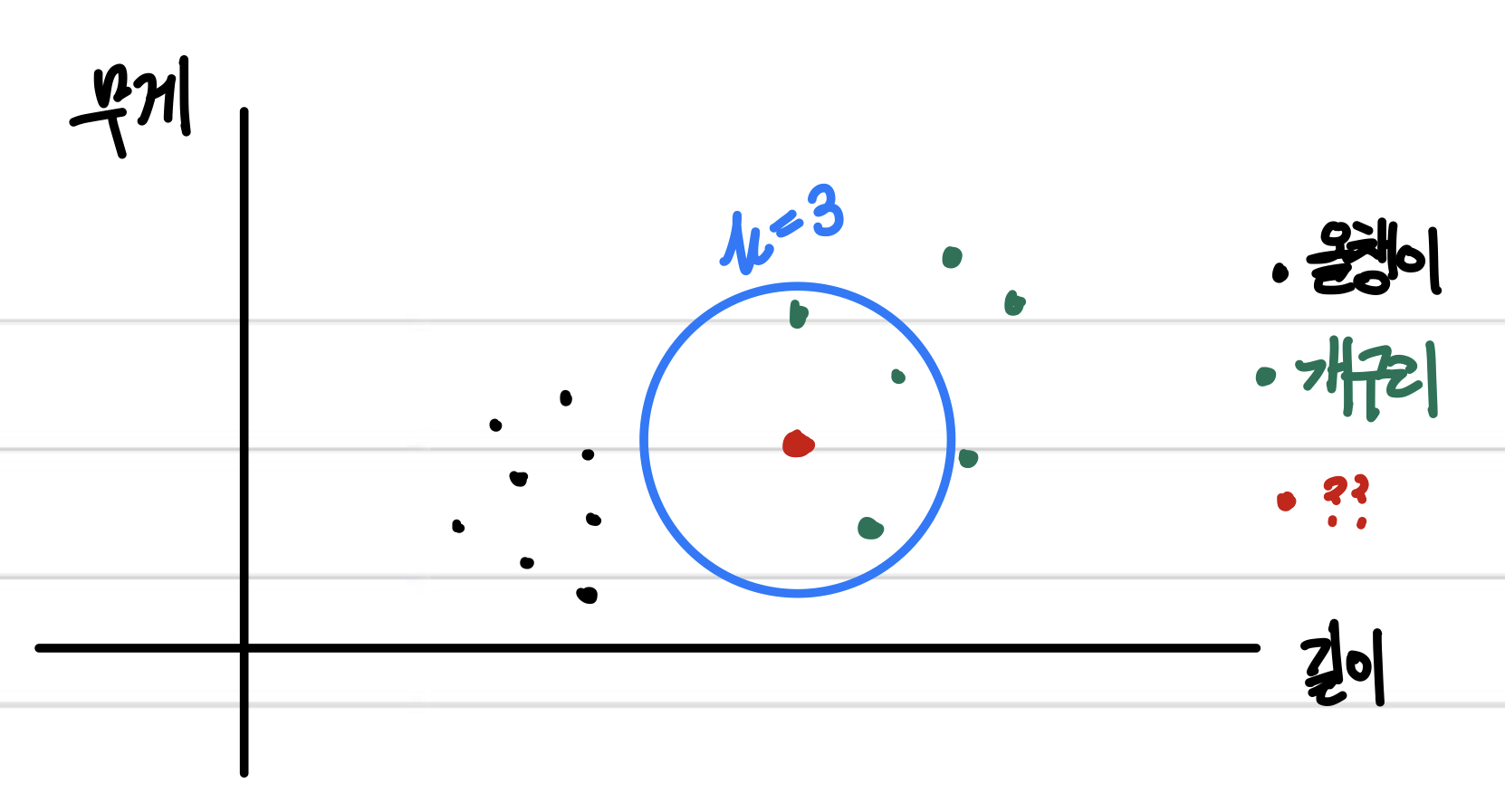
k=3이면 위 그림처럼 주변 세 개의 데이터를 참고하는 것.
그러나 이는 바꿔 말해 k값에 따라 예측값이 달라질 수 있다는 점이다.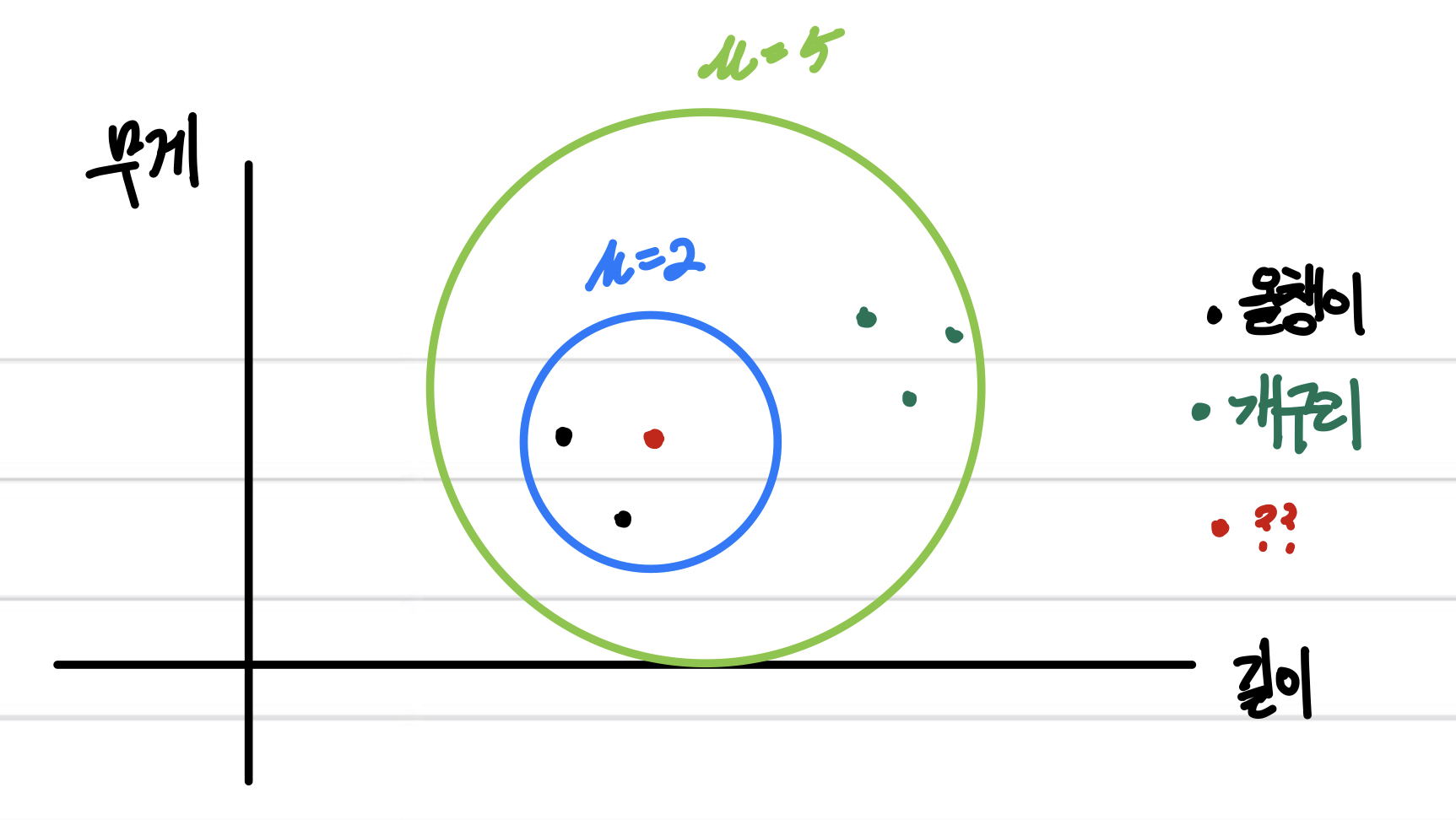
위 그림에서는 k=2라면 데이터를 올챙이로 분류하겠지만, k=5라면 개구리로 분류하게 되는 것.
따라서 적절한 k값을 설정하는 것이 중요하다고 하는데, 이는 주로 총 데이터 수의 제곱근으로 설정한다고 한다.
1.1. k-NN 알고리즘의 장점
- 간단하다. 구현하기 쉽다.
- 훈련 단계가 빠르게 수행된다.
-> 애매한데, 애초에 k-NN 알고리즘은 데이터가 들어오면 훈련이 아니라 저장하는 게 전부다. ㅋㅋ
1.2. k-NN 알고리즘의 단점
- 적절한 k를 설정해줘야 한다. 이에 따라 결과가 바뀔 수 있다.
- 변수 간 상관관계를 파악하고 있어야 이용할 수 있다.
2. k-NN 알고리즘 실습
실습은 [혼자 공부하는 머신러닝+딥러닝] 책을 참고하였다.
데이터 가져오고 뿌려보기
데이터 출처는 https://www.kaggle.com/aungpyaeap/fish-market
import matplotlib.pyplot as plt
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]
plt.xlabel("길이")
plt.ylabel("무게")
#그래프 그려보기
plt.scatter(bream_length, bream_weight)
plt.show()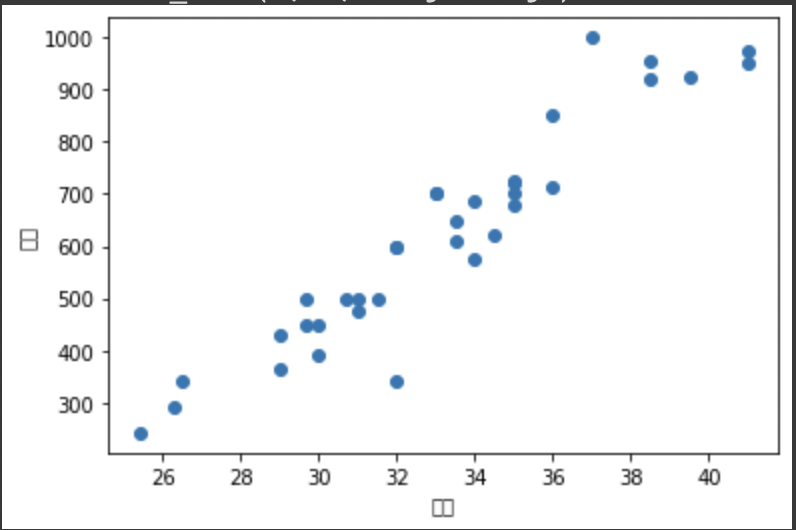
도미 물고기의 데이터가 대략 선형으로 이쁘게 이루어져 있음을 확인할 수 있다.
이번엔 빙어의 데이터도 함께 보자.
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
plt.scatter(bream_length, bream_weight)
plt.scatter(smelt_length, smelt_weight)
plt.show()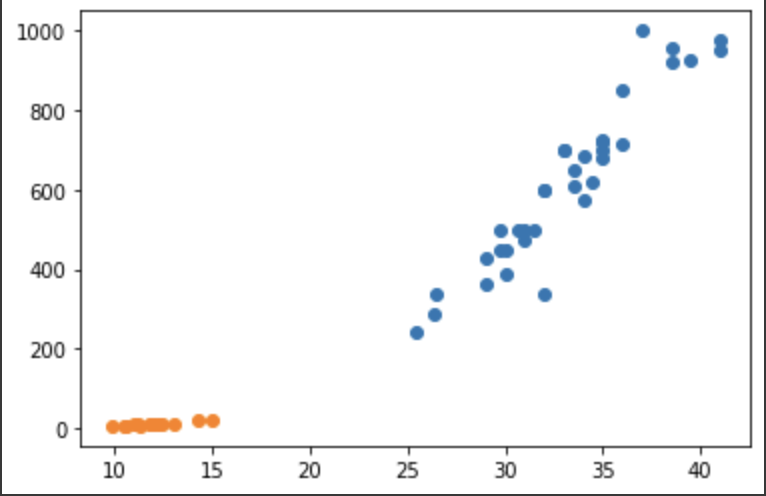
k-NN을 이용하기 위한 준비
학습을 위해서는 하나의 데이터로 합쳐서 넣어줘야 하므로, 두 데이터를 길이-무게 형식만 유지하고 합쳐준다.
length = bream_length + smelt_length
weight = bream_weight + smelt_weight
fish_data = [[l,w] for l, w in zip(length, weight)]
fish_data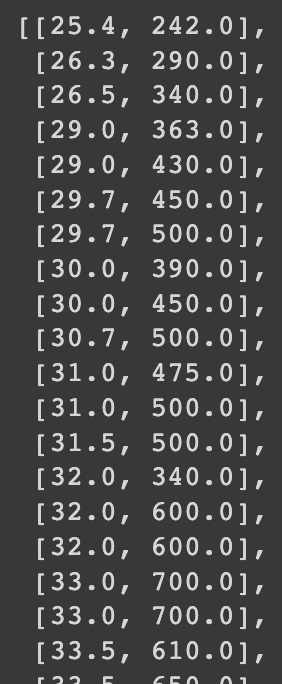
도미 35개와 빙어 14개를 단순히 이어붙인 데이터이니, 맞춰야 할 타겟 값은 다음과 같이 된다.
fish_target = [1] * 35 + [0] * 14
fish_target
# [1, 1, 1, .... 0, 0, 0]
도미를 1, 빙어를 0으로 놓자.
k-NN 알고리즘 구현 클래스 이용하기
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
kn.fit(fish_data, fish_target) #학습
kn.score(fish_data, fish_target) #점수 : 1.0fit을 통해서 객체를 학습시키고, 다시 score를 통해 점수를 출력해보면 1.0이 나온다.
이 때 나오는 점수는 1에 가까울수록 좋음.
이제 새로운 데이터를 넣고 그게 도미인지 빙어인지 예측해보자.
# 길이 30, 무게 600 물고기 예측해보기. 근접 이웃을 기준으로 판단
print(kn.predict([[30, 600]]))
plt.scatter(bream_length, bream_weight) #도미 데이터
plt.scatter(smelt_length, smelt_weight) #빙어 데이터
plt.scatter(30, 600, marker='^') #예측한 물고기의 위치
plt.show()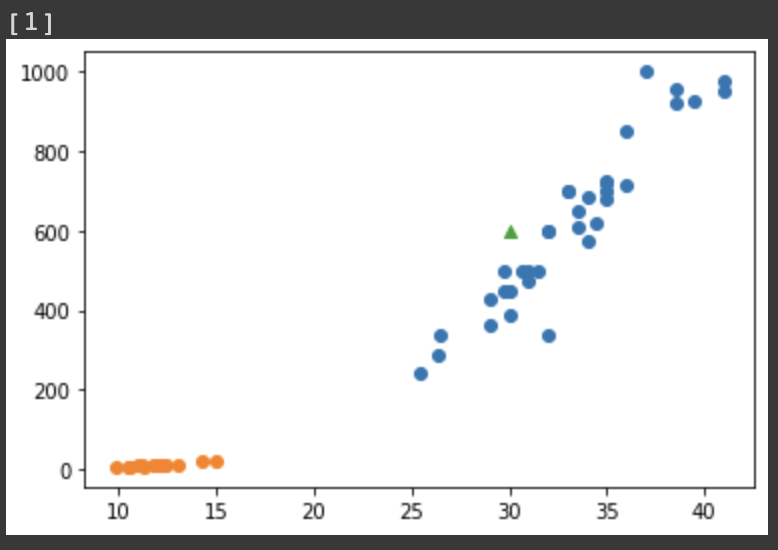
객체는 데이터를 [1], 즉 도미로 예측했고 실제로 위치를 찍어봐도 다른 도미들의 값과 유사함을 확인할 수 있다.
k값 수정하기
# 참고하는 인접 데이터의 수를 수정할 수 있음 (기본 5)
kn49 = KNeighborsClassifier(n_neighbors=49)
kn49.fit(fish_data, fish_target)
kn49.score(fish_data, fish_target) #35/49총 데이터의 개수와 동일하게 이웃의 수를 49로 놓으면, 객체는 데이터 주변 49개의 데이터를 살피고 결단을 내릴 것.
그런데 모두 살펴보면 도미가 35개, 빙어가 14개로 도미가 더 많으므로 예측값은 반드시 도미가 된다.
적절한 k값 설정이 필요한 이유!
오늘은 가장 간단한 머신러닝 기법 중 하나인 k-NN 알고리즘을 살펴봤다.
앞으로도 화이링 !
