머신러닝
1.[머신러닝] k-최근접이웃 알고리즘
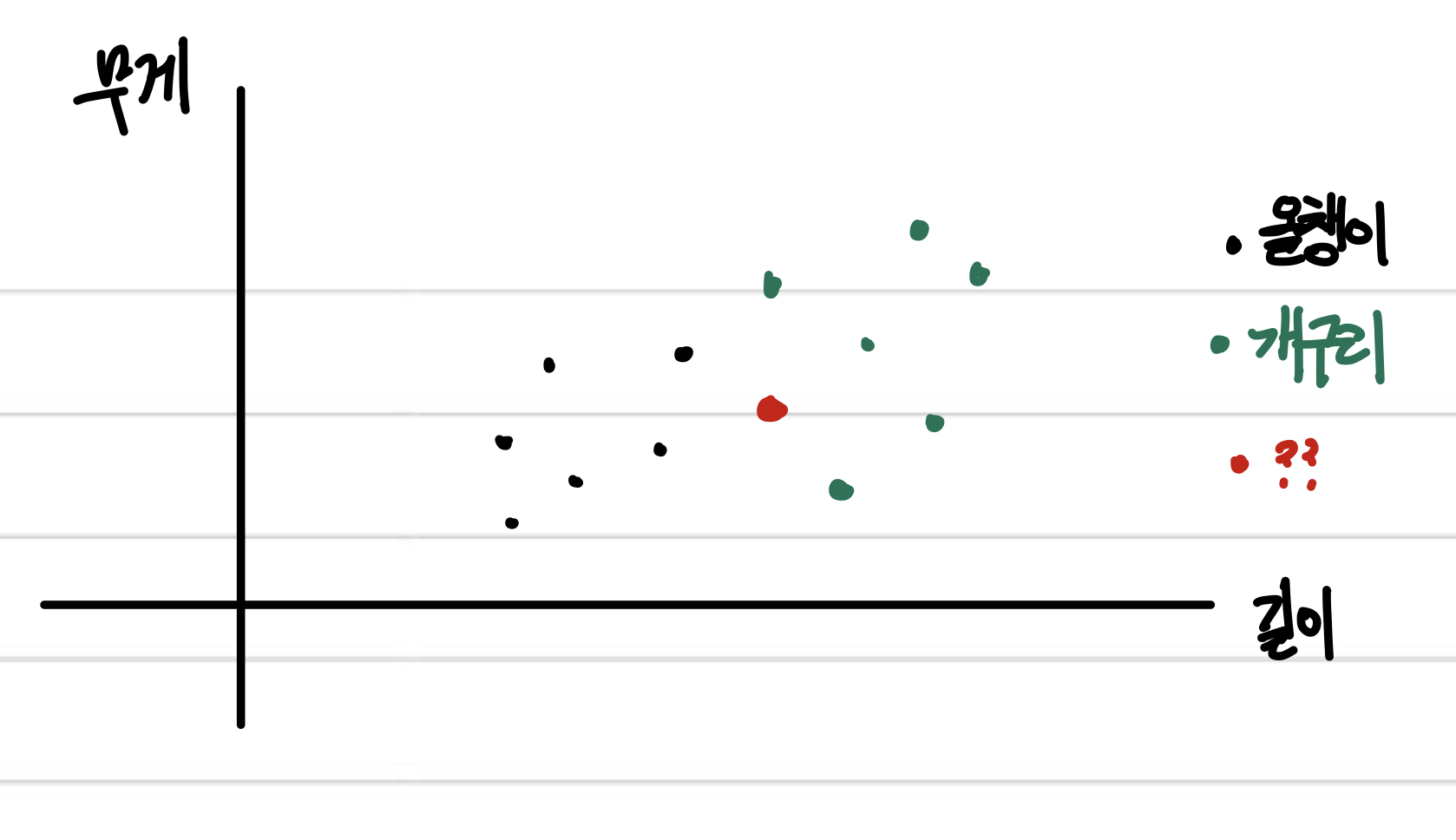
k-최근접 이웃 알고리즘 (k-Nearest Neighbor aka k-NN)은 분류 (Classification) 알고리즘으로, 가장 간단하게 말하면 새로운 데이터 주변 애들을 보고 새로운 놈이 어떤 놈인지 분류하는 것이다.이 때 $k$는 주변 몇 개의 데이터를 볼
2.[머신러닝] 선형회귀
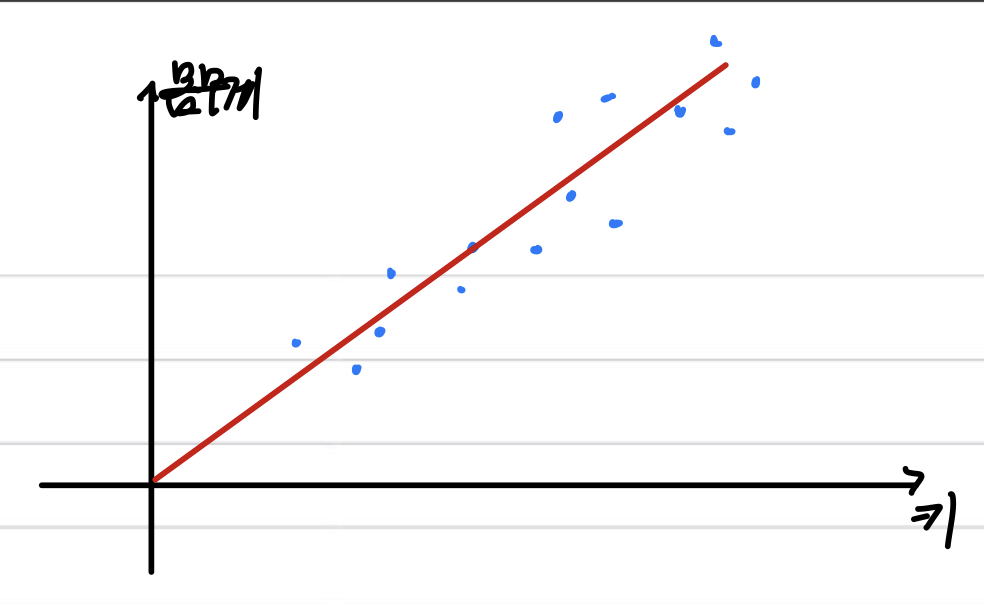
머신 러닝은 주로 어떤 데이터를 넣고 그 결과값을 예측하는 데 쓰인다. 이 중에서도 가장 간단한 방법은 하나의 선을 바탕으로 모델링을 하는 것.예를 들어 위 그래프처럼 키와 몸무게로 그래프를 그렸다고 하자.이 때 각 값에 대해 최소한의 오차를 가지는 하나의 선형 함수가
3.[머신러닝] 로지스틱 회귀
로지스틱 회귀는 이름은 회귀지만 대표적인 분류 알고리즘이다 !선형 회귀와 비슷하게 선형 방정식을 학습하고, 독립변수와 종속변수간의 관계를 파악하지만, 가장 큰 차이는 다음과 같다.💡 ... 하지만 로지스틱 회귀는 선형 회귀 분석과는 다르게 종속 변수가 범주형 데이터를
4.[머신러닝] 손실 함수와 경사하강법 (Gradient Descent)
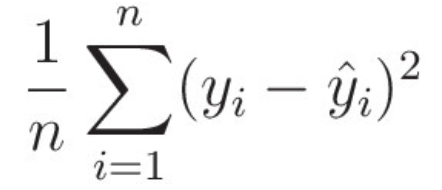
손실 함수는 가중치에 대한 오차의 값을 정의하는 함수이다.이 오차의 값을 구하는 방법에는 여러 가지가 있다.외에도 엔트로피를 활용하는 식 등 많은 식이 있다.이렇게 오차를 정의하고 그래프를 그리면 이것을 손실 함수라고 한다.경사 하강법(傾斜下降法, Gradient de
5.[머신러닝] 확률적 경사하강법 (Stochastic Gradient Descent)
바로 이전 포스트에서 경사하강법에 대해서 다루었다.경사하강법의 경우 손실함수의 최솟값을 잘 찾지만, 한 번 가중치를 변경할 때마다 미분을 해야하므로 계산량이 많다는 단점이 있다(=사용하는 자원이 많다).따라서 주어진 데이터를 모두 이용하지 않고, 그 중에서 무작위로 데
6.[머신러닝] 결정 트리
분류 알고리즘의 하나로, 이해하기가 굉장히 쉽다라는 장점이 있다.클래스 라벨을 따져서 논리곱을 보여줌으로써, 각 질문을 만족시키는지/만족시키지 못하는지에 따라서 클래스 분류 확률을 보여준다.백문에 불여일견 ! 일단 해보자.실습은 혼자 공부하는 머신러닝+딥러닝 에서 가져
7.[머신러닝] 교차 검증
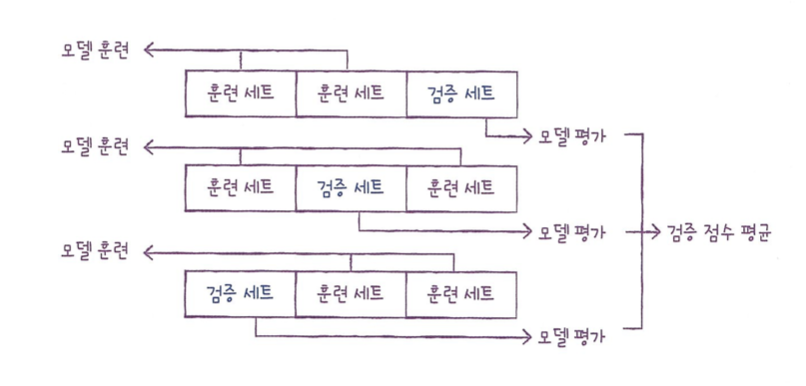
훈련 데이터와 테스트 데이터로 데이터를 나누어 모델을 훈련시키다 보면, 우리 모델의 성능 지표는 테스트 점수와 훈련 점수 밖에 없다.따라서 실전에 잘 맞는 모델이 아니라 테스트 세트에 맞춰진 모델이 만들어질 수 있다.이를 해결하기 위해서 교차 검증이라는 개념이 존재한다
8.[머신러닝] 하이퍼파라미터 튜닝

머신러닝 모델이 학습하는 파라미터를 모델 파라미터라고 한다.이 때 모델이 학습할 수 없어서 사람이 직접 지정해야 하는 파라미터를 하이퍼파라미터라고 한다.하이퍼파라미터 : 모델이 자동으로 학습할 수 없어 사용자가 지정해줘야 하는 파라미터이를 튜닝하는 것은, 먼저 모델이
9.[머신러닝] 트리의 앙상블 알고리즘 - 랜덤 포레스트, 엑스트라 트리, 부스팅

여러 개의 분류기를 학습하고 그 결과를 합쳐서 최선의 예측 결과를 낸다.성공률이 단일 분류기보다 높다 (낮으면 높은 것을 목표로 한다)주어진 표본을 재표본추출하여 같은 크기인 다양한 변동성의 표본을 만든다.(부트스트래핑)각 노드를 분할할 때, 무작위 개수의 특성을 선택
10.[머신러닝] 주성분분석(PCA)
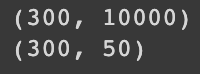
📚 주성분분석 데이터의 주성분을 가져와 차원을 축소시키는 알고리즘. '주성분' 이라 함은 원래 데이터를 가장 잘 표현할 수 있는 성분들 때문에 원래 데이터의 분산이 큰 방향 (주성분)을 찾아 거기로 데이터를 투영시키는 과정이다. 차례대로 분산이 가장 큰 '주성분'을