📚 주성분분석
- 데이터의 주성분을 가져와 차원을 축소시키는 알고리즘.
- '주성분' 이라 함은 원래 데이터를 가장 잘 표현할 수 있는 성분들
- 때문에 원래 데이터의 분산이 큰 방향 (주성분)을 찾아 거기로 데이터를 투영시키는 과정이다.
- 차례대로 분산이 가장 큰 '주성분'을 찾아 차원을 줄이는 개념이다.
- 이를 통해 저장 공간을 줄이거나 모델의 훈련 시간을 감소시킬 수 있다.
사이킷런의 PCA 클래스로 구현 가능!
설명된 분산
- 주성분분석의 결과인 주성분이 원래 데이터의 분산을 얼마나 잘 설명하는지를 의미한다.
💻 실습
실습은 [혼자 공부하는 머신러닝 + 딥러닝] 을 참고하였다.
데이터 가져오기
!wget https://bit.ly/fruits_300 -O fruits_300.npy
import numpy as np
fruits = np.load('fruits_300.npy')
fruits_2d = fruits.reshape(-1, 100*100)역시 이전에 K-평균 알고리즘에서 다뤘던 데이터인 과일 이미지 데이터를 가져온다.
PCA
sklearn의
PCA 클래스를 이용해서 주성분분석을 할 수 있다.
#PCA 분석
from sklearn.decomposition import PCA
# n_components = 변환할 주성분의 개수
pca = PCA(n_components=50)
pca.fit(fruits_2d)그리고 데이터의 원래 shape와 PCA를 통한 데이터의 shape을 출력해보자.
print(fruits_2d.shape)
print(pca.components_.shape)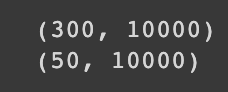
원래 300개의 특성을 가졌던 데이터의 주성분이 50개 정도로 추려진 것을 확인할 수 있다.
주성분의 이미지를 한 번 출력해보면 어떨까?
import matplotlib.pyplot as plt
fig, ax = plt.subplots(5, 10)
for i in range(len(pca.components_)):
ax[i//10][i%10].imshow(pca.components_[i].reshape(100, 100))
ax[i//10][i%10].axis("off")
명확하게 식별 가능한 것들은 아니지만, 주성분이라고 한다.
그럼 실제로 주성분분석을 통해 차원을 낮춰보자.
print(fruits_2d.shape)
fruits_pca = pca.transform(fruits_2d)
print(fruits_pca.shape)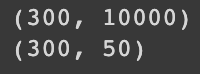
300개의 데이터에 대해 1000개 (100*100)였던 특성이 50개로 추려진 것을 확인할 수 있다.
원본 데이터 재구성
PCA 클래스의 inverse_transform 메서드를 통해 원본 데이터를 재구성할 수 있다.
(물론 약간의 손실은 어쩔 수 없다)
# 원본 데이터 재구성
fruits_inverse = pca.inverse_transform(fruits_pca)
print(fruits_inverse.shape)
설명된 분산
위에서 기록했듯이, 주성분이 원본 데이터의 분산을 얼마나 잘 나타내는지 기록한 값이다.
pca 클래스의 explained_variance_ratio에 담겨있는데, 이는 각 주성분에 대한 분산값이므로 모두 더해줘야 원본 데이터에 대한 분산값이 된다.
print(np.sum(pca.explained_variance_ratio_))
주성분들이 원본 데이터의 약 92%의 분산을 나타내고 있다는 것을 알 수 있다.
이 때 이거를 그래프로 그려보면 주성분분석은 분산이 큰 순서대로 주성분을 골라잡는다 라는 것을 이해할 수 있다.
plt.plot(pca.explained_variance_ratio_)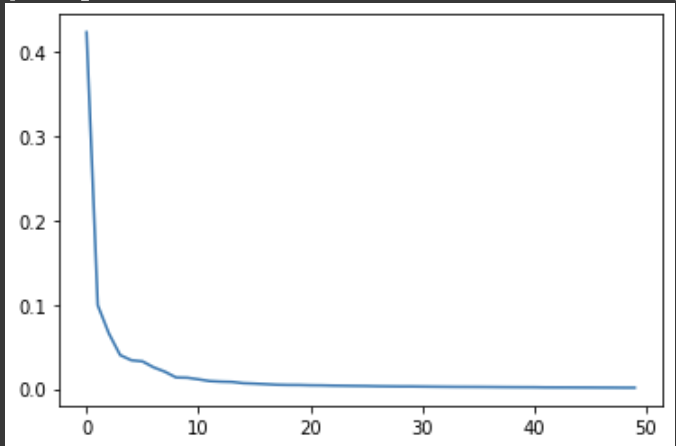
50번째 주성분에 가까워져갈수록 분산 비율은 낮아진다.
분산 비율에 맞춰 PCA하기
사실 우리가 원하는 것은 주성분의 갯수를 하이퍼파라미터 튜닝하는 것이 아니라, 적정 분산을 표현할 수 있는 분산을 알아서 구하는 것이다.
이는 pca 클래스의 n_components 파라미터에 0과 1 사이의 값을 줌으로써 구할 수 있다.
# pca 클래스는 지정한 비율에 도달할 때까지 주성분을 탐색
pca = PCA(n_components=0.5) # 주성분 개수 대신 비율로 입력, 50%의 분산을 나타낼 수 있는 주성분
pca.fit(fruits_2d)
print(pca.n_components_)출력은 2가 나온다. 이는 2개의 주성분만으로 원래 데이터의 50% 분산을 표현할 수 있다는 말.
