📊 모집단 (population) : 어떤 데이터 집합을 구성하는 전체 집합
📊 표본 (sample) : 모집단의 특성을 파악하기 위해서 모집단으로부터 추출한 모집단의 일부 집단
표본추출법
모집단의 크기는 대부분 늘 너무 크고 방대하고, 모든 데이터를 모으기도 힘들기에 그의 부분집합인 표본을 통해 모집단의 특성을 파악하려는 노력을 하게 되는데, 이 때 표본을 추출하는 방법을 표본추출법이라고 한다.
표본추출법은 확률적 표본추출(probability sampling)과 비확률적 표본추출(non-probability sampling)로 구분할 수 있다.
두 방법에 대한 대표적인 예로 리터러리 다이제스트와 갤럽 조사의 사례가 있다. 미국의 대선을 앞두고, 두 후보 알프레드 랜던과 프랭클린 루즈벨트 중 누가 대통령이 될지에 대해서 예측을 시행했다.
리터러리 다이제스트는 1000만 명을 조사해 알프레드 랜던이 압도적으로 이길 것이라 예측했고, 갤럽 조사는 2000명을 대상으로 조사해 루즈벨트가 대통령이 될 것이라 예측했다. 결과는 우리 모두 알듯이 프랭클린 루즈벨트가 대통령이 되었다.
두 회사의 차이점은 통계를 구한 집단이 달랐다는 점.
리터러리 다이제스트는 정기 구독자라던가, 사치품 등을 구매해 마케팅 명단에 있는 사람들 위주로 설문조사를 했다. 당연히 이들은 사회적 지위가 비교적 높은 사람들일 수밖에 없었다. 따라서 그 수가 아무리 많더라도, 표본 편항(sample bias)이 발생한 것.
😡 표본 편향
모집단을 잘못 대표하는 표본을 말한다.
-> 모집단과 표본 사이의 차이가 크고, 표본을 뽑은 방법 그대로 몇 번을 다시 뽑아도 차이가 유지될 것 같을 때 표본편향이 발생했다고 볼 수 있다.
사격을 생각해보면 이해하기 쉬운데, 사격 후 총알이 몰려있는 것처럼 뽑은 표본이 모집단을 대표하지 못하고 쏠려있는 것.
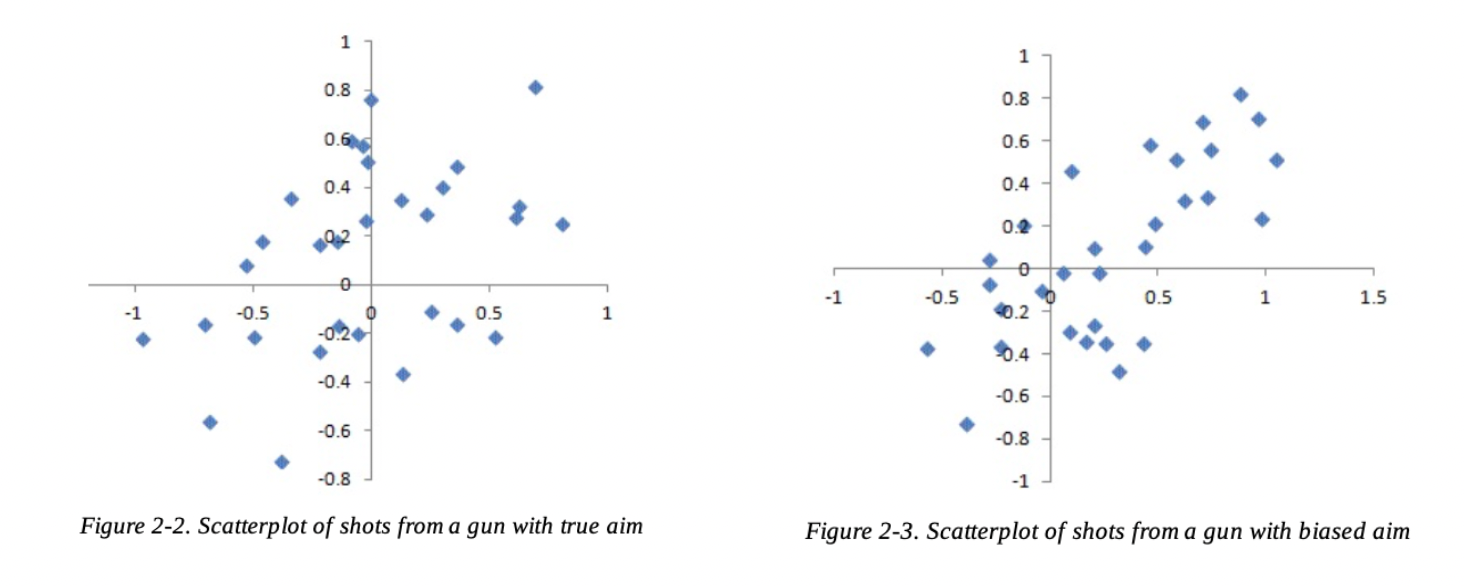
출처 : 책 [데이터 과학을 위한 통계]
이 중에서 모집단을 대표할 수 있는 불특정 표본을 추출하는 방법을 확률적 표본추출법, 리터러리 다이제스트처럼 임의가 아닌 표본추출을 비확률적 표본추출법이라고 한다.
확률적 표본추출법에는 단순 임의 추출, 층화적 임의 추출, 군집 추출이나 체계적 추출 등이 있고,
비확률적 표본추출법에는 편의 추출, 자발적 표본추출, 유의 표본추출, 눈덩이 표본추출 등이 있다.
모집단을 적절하게 대표하는 표본(대표성을 보장하는 표본) 을 추출하기 위해서는 확률적 표본추출법을 따르는 것이 🚨핵심🚨이다.
확률적 표본추출법
? 단순 임의 추출
단순 임의 추출은 말 그대로 모집단에서 무작위로 표본을 추출하는 방법.
다만 모집단은 너무 커다랗기에 전체 모집단을 대상으로 랜덤룰렛을 돌릴 수는 없는 법.
그래서 접근 가능한 모집단을 잘 정의해야 한다.
이렇게 모집단을 정의하고 단순히 룰렛을 돌리는 것을 단순 임의 추출이라고 한다.
이 때, 뽑은 원소를 다시 넣냐 마냐에 따라서 복원추출과 비복원추출로 갈린다.
단순 임의 추출 코드
#Python pandas 모듈의 DataFrame.sample() 메소드를 사용해서 DataFrame으로 부터 무작위 (확률, 임의) 표본 추출 (random sampling) 하는 방법
import pandas as pd
df = pd.DataFrame({'num_legs': [2, 4, 8, 0],
'num_wings': [2, 0, 0, 0],
'num_specimen_seen': [10, 2, 1, 8]
},
index=['falcon', 'dog', 'spider', 'fish'])
df.sample(n=3, replace=False) #n은 임의추출할 표본의 크기, replace는 복원 여부. False가 디폴트로 비복원추출이다.출처 : KHUDA 박선우 선생님
이 때 비복원추출로 놓고 n을 모집단의 크기보다 크게 하면 에러가 뜬다.
당연히 하나씩 빼는데 모집단보다 더 많이 뺄수는 없기 때문 !
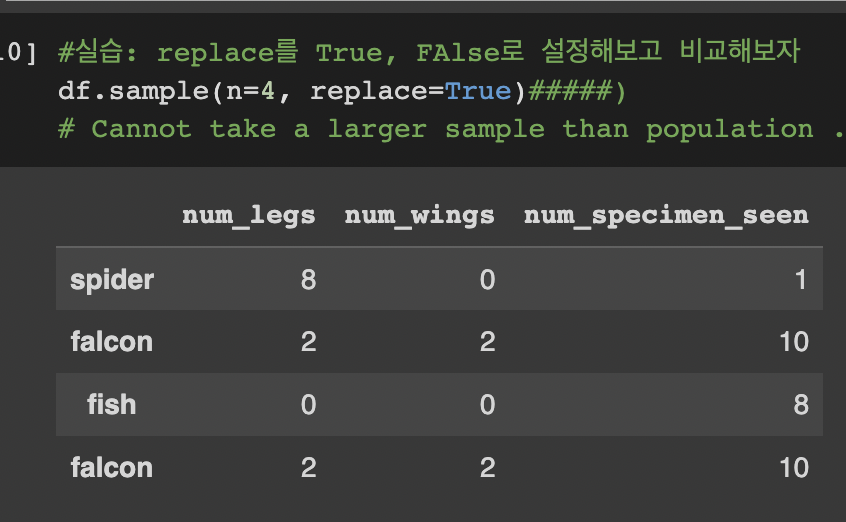
💡 이렇게 복원추출 시 동일한 표본도 다시 뽑히는 것을 알 수 있다.
? 층화 표본 추출
층화라는 말에서 엿볼 수 있듯이, 정의한 모집단을 층으로 나눠서 모집단의 특성이 잘 살아있는 표본을 추출하는 방법이다.
예를 들어 시민들의 일주일 단위 운동 시간을 모집한다고 해보자. 이 때 시민 중 랜덤으로 100명을 뽑을 경우 표본 편향이 일어날 수 있다. 하지만 BMI를 기준으로 마름/보통/체격있음 식으로 층을 나눈다면 모집단과 더 비슷한 표본을 뽑을 수 있을 것.
이렇게 접근 가능한 모집단을 층화시키고 적정 가중치를 줘서 각 층에서 표본을 추출하는 방법이다.
이 때 가중치를 주는 방법은 여러 가지가 있다. 표본의 크기를 이라고 하자.
📚 각 층에 을 동일하게 분배한다
📚 각 층이 모집단에서 차지하는 비율에 비례하게 을 분배한다
📚 각 층이 모집단에서 차지하는 비율에 비례하지 않게 을 분배한다 -> 연구하려는 층이 모집단에서 크기가 작거나, 불필요한 층이 너무 클 때 사용
군집 추출 (Cluster Sampling)
모집단이 전체 모집단을 설명하기에 적절한 여러 군집으로 이루어져 있을때, 무작위 군집에서 표본을 추출하는 방법. 모집단을 그룹으로 나누고 그룹에서 표본을 추출한다는 점에서 층화 임의 추출과 유사한 모습을 띄지만, 두 표본추출법은 엄연히 다르다.

