다음 포스트: [Oracle] Select 문장의 실행 원리
Oracle Server Architecture
인스턴스 생성 과정
-
유저가 DB에 접속해서 Oracle을 시작(startup)
-
startup 요청을 받은 최초의 Oracle Server Process가 초기화 파라미터(
/etc/sysctl.conf(리눅스),/etc/system(솔라리스))를 참고해 OS Kernel에게 공유 메모리를 할당해 달라고 요청 -
이후 SGA가 생성(공유 메모리 할당)되면 OS Kernel이 관리
OS Kernel에게 SGA 생성을 요청한 Oracle Server Process가 종료되어도 SGA는 종료되지 않습니다.
Instance가 종료되어야 SGA가 공유 메모리에서 사라지게 됩니다.
SGA는 공유 메모리로 구성되어 여러 Server Process가 공유해서 사용
파라미터 정리
세마포어(Semaphore)
깃발(Flag)이라는 의미로 어떤 자원의 현재 사용 여부를 표현합니다.
메모리는 메모리 블록 단위로 관리되고, 프로세스는 메모리 블록에 접근합니다.
이때 여러 프로세스가 동시에 하나의 메모리 블록에 접근하게 되면 큰 문제가 발생할 수 있습니다(Kernel Panic, Blue Screen)
그래서 Server에서 동작하는 모든 프로세스는 해당 메모리 블록이 사용되고 있는지를 세마포어 상태를 통해 확인합니다.
메모리 블록마다 세마포어 세트가 할당되어 있습니다.
세마포어 상태는 set/unset으로 나뉩니다.
만약 set으로 세팅되어 있다면 해당 메모리 블록은 사용 중이라는 의미입니다.
나중에 release되어 unset이 되는 순간 세마포어를 set으로 세팅하고 메모리 블록을 사용할 수 있게 됩니다.
세마포어 관련 주요 kernel 파라미터
SEMMSL: 세마포어 세트 당 세마포어 최대 개수SEMMNI: 리눅스 전체에서 설정 가능한세마포어 세트 최대 개수. Oracle 권장 값은100이상SEMMNS: 리눅스 전체에서 사용 가능한세마포어 최대 개수. 이론적으로SEMMSL X SEMMNI값 이상이어야 합니다.SEMOPM: 1call(1개의 시스템 호출)이초당 호출 가능한 최대 세마포어 개수. 보통SEMMSL과 동일하게 설정하는 것이 권장됩니다.
아래 명령을 통해 세마포어 파라미터가 어떻게 설정되어 있는지 확인할 수 있습니다.
$ ipcs -ls세마포어 값들은 Oracle사에서 Oracle 버전과 유닉스 버전에 맞는 최적화된 권장값을 알려줍니다.
그 밖의 파라미터
-
SHMMAX- 공유 메모리 세그먼트의 최대 크기
- Kernel이 응용 프로그램에게 메모리를 할당해 줄 때 작게 여러 번 할당하지 않고 큰 덩어리(
세그먼트)로 한꺼번에 할당 - 만약 Oracle이 RAM을
100MB를 쓸 수 있는데 이 파라미터를20MB로 설정할 경우 5개의 세그먼트로 나누어서 사용해야 하므로 성능이 떨어집니다. - 그렇다고 너무 크게 설정할 경우 메모리 낭비가 심해집니다.
kernel.shmmax값을 아주 작게 주고 DB에 접속을 시도할 경우 아래와 같은 메시지가 발생할 수 있습니다.
$ sqlplus / as sysdba ERROR: ORA-12547: TNS:lost contact또는 아래와 같은 메시지가 발생할 수 있습니다.
ORA-27123: unable to attach to shared memory segment- 현재 시스템에 설정되어 있는
kernel.shmmax값을 확인하려면 아래 명령을 수행합니다.
(일반적으로 디폴트 값은 32MB입니다. 하지만 Oracle SGA로 활용하기에는 턱없이 부족하기 때문에 보통2GB로 설정합니다)
$ cat /proc/sys/kernel/shmmax 16777214-
파라미터 변경법
/proc파일시스템에 변경사항을 직접 반영시켜 Server의 재부팅 없이SHMMAX값 변경
$ echo "2147483648" > /proc/sys/kernel/shmmax $ cat /proc/sys/kernel/shmmax 2147483648sysctl명령어를 사용해SHMMAX값 변경
$ sysctl -w kernel.shmmax=2147483648/etc/sysctl.conf파일에 Kernel 변수 값들을 추가함으로써 변경 사항을 영구적으로 적용. 이 파일을 수정한 후 OS의 재부팅 없이 즉시 적용하려면 root 계정으로sysctl -p명령 수행
-
SHMMNI- 공유 메모리 세그먼트 최대 개수
- 일반적으로 디폴트 값은
4096 - 설정 확인 방법
$ cat /proc/sys/kernel/shmmni 4096 -
SHMALL- 특정 시점에 시스템에서 사용 가능한 공유 메모리의 최대 크기
ceil(SHMMAX/PAGE_SIZE)값보다 큰 값을 사용할 것을 권장- 디폴트 사이즈는
2097152 bytes.i386기반Red Hat Linux의 페이지 사이즈는4096 bytes - 설정 확인 방법
$ cat /proc/sys/kernel/shmall 2097152 -
SHMMIN- 단일 공유 메모리 세그먼트의 최소 크기(byte)
-
SHMSEG- 1개의 프로세스에 부여될 수 있는 공유 메모리 세그먼트의 최대 개수
메모리 공간 할당 방법
1. 하나의 세그먼트에 전체 SGA 할당
메모리 할당 방법 중 가장 성능이 좋은 방법입니다.
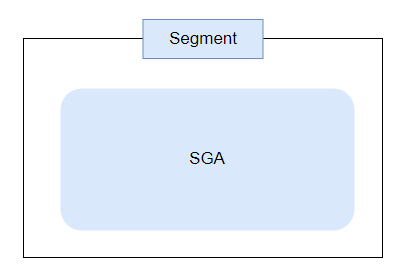
2. 연속된 여러 세그먼트에 SGA를 분산시켜 할당
SGA내 fixed Area 부분은 반드시 전체가 하나의 세그먼트에 할당되어야 합니다.
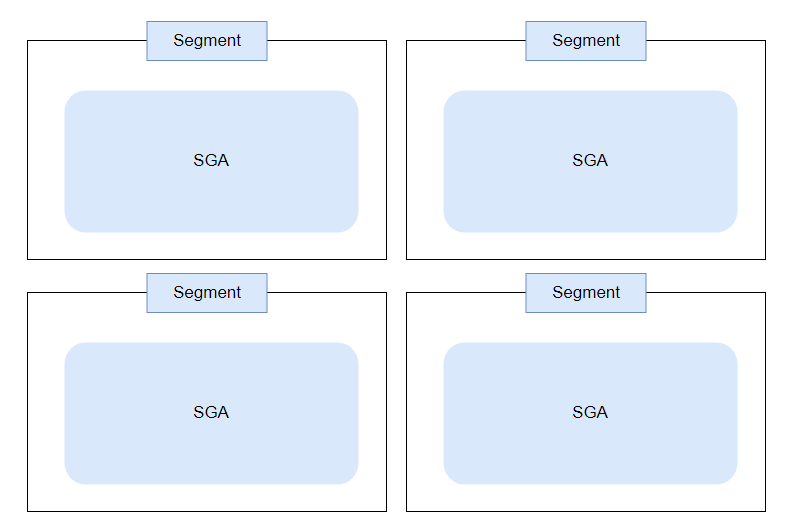
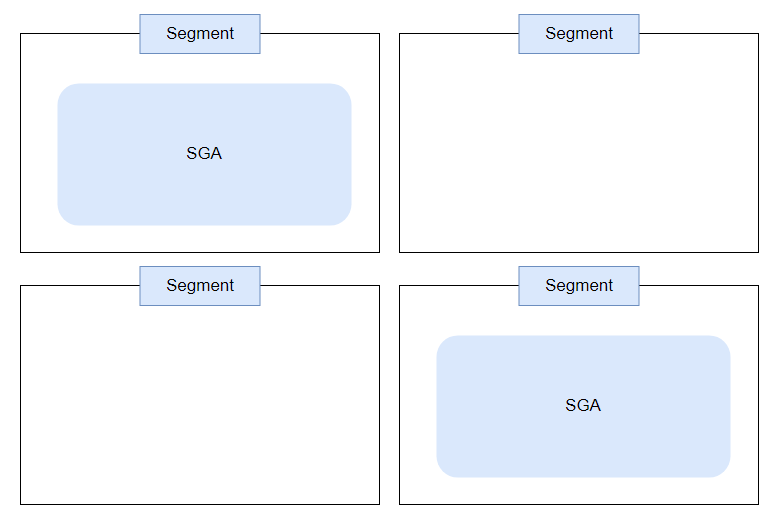
3. 떨어진 여러 세그먼트에 SGA를 분산시켜 할당
메모리가 단편화되어 있다고 표현합니다.
메모리를 정리해서 Oracle이 연속적인 공간을 할당 받을 수 있도록 해 주어야 합니다.
SGA의 주요 구성 요소
Oracle의 거의 모든 작업이 SGA에서 이루어집니다.
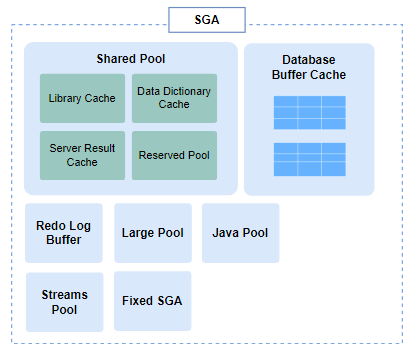
Database Buffer Cache
데이터의 조회와 변경 등의 실제 작업이 일어나는 공간으로 사용자가 조회하거나 변경하려는 모든 데이터는 이 곳에 있어야 합니다.
사용자가 데이터를 입력하면 데이터는 하드 디스크의 데이터 파일에 저장되지만,
저장되어 있는 데이터를 조회하거나 변경하려면 그 데이터가 저장되어 있는 데이터 파일의 블록을 복사한 후 Database Buffer Cache로 가져와서 작업을 수행합니다.
번거로울 수 있어 보이지만 작업 속도가 높아집니다.
작업 속도가 디스크보다 메모리가 훨씬 빠를 뿐더러,
메모리에 있는 데이터는 다른 사용자에게 공유될 수 있기 때문에 여러 사람이 작업하는 환경일 경우 전체적인 작업 속도가 빨라집니다.
여러 명의 사용자가 같은 곳의 메모리 블록을 동시에 사용할 경우 심각한 장애가 발생할 수 있기 때문에 서로 중복사용이 되지 않도록 잘 관리가 되어야 합니다.
Database Buffer Cache 상태
: 만약 어떤 사용자가 데이터를 조회하거나 변경해야 할 경우 해당 데이터가 이 곳에 없다면 하드 디스크의 데이터 파일에서 필요한 블록을 찾아 Database Buffer Cache로 복사를 해와야 합니다. 하지만 그 전에 Database Buffer Cache의 블록 상태를 먼저 확인해야 합니다. 여러 사용자가 공동으로 사용하는 곳이므로 하나의 블록에 여러 사용자가 동시에 I/O를 시도할 수 있기 때문입니다.
Pinned Buffer: 다른 사용자가 현재 사용하고 있는 Buffer 블록Dirty Buffer: 현재 작업은 진행되지 않지만 다른 사용자가 내용을 변경한 후 아직 데이터 파일에 변경된 내용을 저장하지 않은 Buffer를 의미합니다.Free Buffer: 사용되지 않았던지(Unused)Dirty Buffer였다가 하드 디스크로 저장이 완료(DBWR에 의해 기록됨)되어 재사용할 수 있는 블록을 의미합니다(미사용 Buffer + DBWR에 의해 기록된 Buffer).
LRU(Least Recently Used) List
: 제한적인 메모리 공간을 효율적으로 관리(기존의 블럭에 덮어쓰기)하기 위한 리스트
- Database Buffer Cache의 Buffer Block의 상태를
LRU 알고리즘을 이용하여 관리하는 리스트입니다. LRU 알고리즘: 만약 SGA 용량이 100MB인데 사용자들이 변경하고자 하는 자료가 150MB일 때, SGA의 일부분을 덮어 써야 합니다. 이때 가장 최근까지 많이 사용된 것은 지키고 가장 사용이 안된 것은 덮어쓰는(버리는) 알고리즘입니다.메인 리스트: 사용된 Buffer들의 리스트.Hot/Cold로 나뉩니다.보조 리스트: 미 사용된 Buffer들이나, DBWR에 의해 기록된 Buffer들의 리스트(Free List)
만약 어떤 사용자가 데이터 파일의 데이터를 Database Buffer Cache로 가져와야 할 경우가 생긴다면,
(하드 디스크의 데이터 파일에서 필요한 블록을 찾아 DB Buffer Cache로 복사해 오는 작업은 Server Process가 담당합니다)
- 보조 리스트에서
free buffer를 먼저 찾습니다. - 보조 리스트의 buffer가 모두 사용된 경우라면, 메인 리스트의
cold영역에서free buffer를 다시 찾습니다. - 특정 개수(
10G 기준 40%)만큼 찾고 더이상 free buffer를 찾을 수 없다면 스캔을 멈추고DBWR에게Dirty Buffer를 내려 쓰라고 요청을 하게 됩니다. 그럼Dirty Buffer는Free Buffer로 바뀌게 되고, 보조 리스트에 추가하면서Free Buffer를 확보합니다.
DBWR(Database Writer) Process: 변경이 완료된 데이터를 데이터 파일로 저장해주는 백그라운드 프로세스
Latch
: 유한한 자원(EX. Free List) 을 여러 프로세스가 한꺼번에 사용하려고 할 경우 사용 순서를 관리해줍니다.
- 모든 메모리 자원에는 각
Latch가 별도로 존재합니다. - 모든 프로세스들은 해당 메모리 자원에 접근해서 사용하려면 반드시 그 메모리의
Latch를 가지고 있어야만 합니다. - 자원에 순서대로 접근할 수 있게 번호표를 준다고 생각하면 될 것 같습니다.
Redo Log Buffer
데이터에 변경사항이 생길 경우(DDL, DML) 해당 변경 내용을 기록해 두는 역할을 합니다.
장애가 발생했을 때 Redo Log를 이용해 복구할 수 있습니다.
(Redo log: 돈을 빌려주고 적는 장부와 같은 것)
Redo Log가 저장되는 메모리 공간을 Redo Log Buffer라고 합니다.
Redo Log Buffer가 저장되는 디스크 내의 파일을 Redo Log File이라고 합니다.
모든 변경사항들이 Redo Log에 기록되는 것은 아닙니다.
Direct Load(SQL Loader, insert /*+ APPEND */)나 table, index 생성 시 nologging 옵션을 준다면 Redo Log에 기록되지 않습니다.
(nologging 옵션을 주고 table을 생성했다 하더라도 테이블 내에서 발생하는 insert, update, delete는 모두 Redo Log에 기록됩니다)
Redo Log는 Oracle Recovery의 핵심 요소이지만 전체적인 성능이 저하되는 부작용이 있습니다.
Shared Pool
shared_pool_size 파라미터의 크기를 통해 shared pool의 전체 크기를 설정할 수 있습니다.
Library Cache와 Dictionary Cache의 크기는 따로 관리할 수 없습니다.
Library Cache
Soft Parse할 때 사용되는 공간으로 이미 수행되었던 SQL 문장이나 PL/SQL 문장의Parse Code와해당 SQL/PLSQL 문장,실행계획(플랜)등이 저장되어 있습니다.LRU 알고리즘으로 관리됩니다.
SQL: 관계형 데이터베이스에 저장된 데이터에 Access하기 위하여 사용하는 표준언어입니다.PL/SQL: SQL문을 사용하여 프로그램을 작성할 수 있도록 확장해 놓은 오라클의 Procedural Language이다.
Dictionary Cache
- 구문분석이나 옵티마이저가 실행계획을 세울 때 사용되는 주요 Dictionary들이 Row 단위로 Cache되어 있습니다.
LRU 알고리즘으로 관리됩니다.
Server Result Cache
11g부터 새로 생긴 영역쿼리의 결과를 저장해두는 영역으로 Database Buffer Cache 영역까지 가지 않고,Server Result Cache에서 가져가도록 해서성능을 향상시켰습니다.- 여러 사용자가 Buffer Block을 동시에 액세스 하고 있는 환경에서 경합으로 인해 발생하는 속도 저하를 막기 위해 등장한 기능입니다.
- 하지만, 무조건 좋은 것은 아닌 것이, 만약 쿼리의 결과가 Server Result Cache에 존재하지 않을 경우 다시 Database Buffer Cache까지 가서 가져와야 하므로 시간이 더 걸릴 수 있고, Database Buffer Cache에서 변경 사항이 발생했을 때 Server Result Cache에 이중으로 반영해야 한다는 점을 고려해야 합니다.
SQL Query Result Cache: SQL의 결과값을 저장하는 영역PL/SQL Query Result Cache: PL/SQL의 결과값을 저장하는 영역
기존에는 쿼리를 요청하면 Server Process가 디스크로부터 쿼리의 결과값을 SGA의 Database Buffer Cache Block에 저장하고, Database Buffer Cache에서 데이터를 찾아와(
Fetch: 인출) PGA에서 취합한 후 사용자에게 보여주는 구조였습니다.
Reserved Pool
- Shared Pool에 5KB(11g 기준)가 넘는 오브젝트가 적재되어야 할 경우 사용하기 위해 예약해 둔 공간입니다.
- 드물지만 java나 PL/SQL, SQL 객체 중에
대용량인 객체가 있을 경우Shared Pool의 공간이 부족할 때 사용하는 공간입니다. - 관리자가 이 공간의 크기를 명시적으로 설정하고 싶다면
SHARED_POOL_RESERVED_SIZE파라미터로 용량을 설정하면 됩니다. - 보통 이 공간의 크기는
Shared_Pool_Size크기의5% ~ 50%입니다. - 이 공간이 부족한지 충분한지를 조회하려면
v$shared_pool_reserved를 조회하면 됩니다.REQUEST_FAILURES값이 증가하면 이 공간이 부족하다는 뜻이므로SHARED_POOL_RESERVED_SIZE의 값을 늘려주면 됩니다.REQUEST_MISSES의 값이 0이거나 증가되지 않는다면 공간이 부족하지 않다는 뜻입니다.
Large Pool
SGA의 필수 구성 요소는 아니며 아래와 같은 경우에 사용합니다.
- Shared Server mode로 Oracle Server를 운영할 경우
UGA를 이곳에 생성합니다. - Parallel Execution(병렬 처리) 작업을 할 경우 각 프로세스들간의
Message Buffer가 이곳에 생성됩니다. - RMAN으로 백업이나 복구를 할 경우
RMAN이 사용하는I/O용 Buffer가 이곳에 생성됩니다.
Java Pool
SGA의 필수 구성 요소는 아니며 java와 관련해서 code나 JVM 관련 데이터를 저장하기 위해 생성되는 선택적인 공간입니다.
Streams Pool
10g 이상 버전부터 생긴 SGA의 구성 요소입니다.
Streams 기능을 사용할 경우 생성됩니다.
그래서 디폴트 크기는 0이지만, Streams 기능을 사용하게 되면 Oracle Streams가 동적으로 그 크기를 증가시킵니다.
Fixed SGA
Oracle이 내부적으로 사용하기 위해 생성하는 공간입니다.
Background Process들이 필요로 하는 Database의 전반적인 공유 정보나 각 Process들끼리 공유해야 하는 Lock 정보와 같은 내용들이 저장되는 영역입니다.
이 공간의 크기는 Oracle이 시작될 때 자동으로 설정되며 사용자나 관리자가 임의로 변경할 수 없습니다.
Dynamic SGA
9i 버전부터 등장한 기능으로 관리자가 필요에 의해서 SGA의 구성요소의 크기를 변경한 후 Oracle Instance의 재기동 없이 즉시 적용할 수 있는 기능입니다.
변경 방법은 alter system set 명령을 사용하면 됩니다.
SYS> alter system set DB_CACHE_SIZE=100M;그래뉼(Granule)
동적으로 SGA 영역의 크기를 변경할 때 Oracle에서 메모리를 할당하는 단위입니다.
SGA_MAX_SIZE라는 파라미터의 크기에 따라 결정됩니다.
9iSGA_MAX_SIZE<= 128MB :1Granule = 4MBSGA_MAX_SIZE> 128MB :1Granule = 16MB
10g이후SGA_MAX_SIZE<= 1G :1Granule = 4MBSGA_MAX_SIZE> 1G :1Granule = 16MB
show sga
Oracle에서 현재 사용 중인 SGA 크기를 확인하려면 show sga 명령을 사용합니다.
SYS> show sga;
Total System Global Area 1660940992 bytes
Fixed Size 8897216 bytes
Variable Size 956301312 bytes
Database Buffers 687865856 bytes
Redo Buffers 7876608 bytes
Total System Global Area: SGA 전체 용량Fixed Size: Background Process들이 사용하는 공간Variable Size: Shared Pool, Large Pool, Java PoolDatabase Buffers: Database Buffer CacheRedo Buffers: Redo Log Buffer
show parameter
Oracle에 설정된 각 파라미터를 조회하고 싶다면 show parameter 명령을 사용합니다.
SYS> show parameter sga_max_size;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
sga_max_size big integer 1584M
SYS> show parameter shared_pool_size;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
shared_pool_size big integer 0
SYS> show parameter db_cache_size;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_cache_size big integer 0
파라미터 변경
먼저 SGA_MAX_SIZE의 값을 조회해봅니다.
SYS> show parameter sga_max_size;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
sga_max_size big integer 160M
SGA_MAX_SIZE는 160M인 것을 확인했습니다.
이제 shared_pool_size의 값을 10MB로 변경해봅시다.
SYS> alter system set shared_pool_size=10m
System altered.
SYS> show parameter shared_pool_size;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
shared_pool_size big integer 12M
SGA_MAX_SIZE가 160M로 1G 미만이기 때문에 1Granule은 4M입니다.
따라서 4의 배수로 할당되어 shared_pool_size는 12M로 할당되었습니다.
만약 shared_pool_size를 8M로 변경하면 어떻게 될까요?
SYS> alter system set shared_pool_size=8M;
System altered.
SYS> show parameter shared_pool_size;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
shared_pool_size big integer 8M4의 배수로 할당되므로, 8M 그대로 할당된 것을 확인할 수 있습니다.
PGA의 구성 요소
PGA(Program Global Area)는 각 프로세스들이 개별적으로 사용하는 메모리 공간입니다.
SGA가 학교의 운동장이라면,
PGA는 학생들의 개별 사물함입니다.
Oracle에서 동작하는 모든 프로세스들(Server Process, Background Process)은 모두 PGA를 가지고 있습니다.
그 중에서 Server Process가 사용하는 Instance PGA의 아키텍처를 살펴보겠습니다.
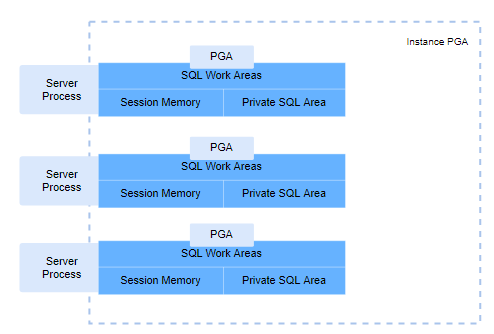
다음은 PGA의 세부적인 아키텍처를 살펴보겠습니다.

Private SQL Area
사용자가 SQL 문장을 수행하면 User Process가 Server Process로 해당 쿼리를 전달합니다. Server Process는 User Process와 관련된 정보를 Session Memory에 저장하고, 해당 SQL의 Parse 작업을 시작합니다.
Persistent Area: Bind 변수 값을 저장해두는 공간입니다.Runtime Area: 쿼리를 수행하는 도중에 데이터를 임시로 저장하는 공간입니다. 예를 들어 100만 건의 데이터를 조회해서 출력해야 할 때, 100만 건 모두가 DB Buffer Cache에서 PGA로 Fetch되어야만 화면에 출력할 수 있는데, 100만 건 모두가 Fetch될 때까지Runtime Area에서 데이터를 모읍니다.
Bind 변수: 사용자로부터 특정 값을 입력 받을 경우 입력 받는 값을 저장할 변수
SQL Work Area
Sort, Hash 관련 작업을 수행하는 공간입니다.
PGA 공간 자동 관리
8i 이전 버전까지는 PGA의 각 공간을 수동으로 직접 관리했습니다.
9i부터는 Oracle Server가 자동으로 관리할 수 있는 방법이 등장하게 됩니다.
PGA의 총량을 지정하는 파라미터인 PGA_AGGREGATE_TARGET의 값을 설정한 후 WORKAREA_SIZE_POLICY 파라미터를 AUTO로 설정하면 PGA를 구성하는 각각의 구성요소의 크기를 Oracle Server가 동적으로 관리하게 됩니다.
(WORKAREA_SIZE_POLICY를 MANUAL로 지정하면 기존처럼 수동으로 관리할 수 있습니다)
적절한 PGA 용량 계산 방법
- OLTP 시스템 환경일 경우:
PGA_AGGREGATE_TARGET = (<총 물리 메모리 용량> * 80%) * 20%- DSS 시스템 환경일 경우:
PGA_AGGREGATE_TARGET = (<총 물리 메모리 용량> * 80%) * 50%
개별 Server Process가 쓸 수 있는 PGA 용량은 SMM_MAX_SIZE 파라미터로 설정할 수 있습니다.
아래의 명령을 통해 PGA 관련 값들을 조회할 수 있습니다.
SYS> select * from v$pgastat;
NAME VALUE
---------------------------------------------------------------- ----------
UNIT CON_ID
------------ ----------
aggregate PGA target parameter 671088640
bytes 0
aggregate PGA auto target 440423424
bytes 0
global memory bound 104857600
bytes 0
NAME VALUE
---------------------------------------------------------------- ----------
UNIT CON_ID
------------ ----------
total PGA inuse 181725184
bytes 0
total PGA allocated 233025536
bytes 0
maximum PGA allocated 234139648
bytes 0
NAME VALUE
---------------------------------------------------------------- ----------
UNIT CON_ID
------------ ----------
total freeable PGA memory 17563648
bytes 0
MGA allocated (under PGA) 0
bytes 0
maximum MGA allocated 0
bytes 0
NAME VALUE
---------------------------------------------------------------- ----------
UNIT CON_ID
------------ ----------
process count 58
0
max processes count 58
0
PGA memory freed back to OS 6488064
bytes 0
NAME VALUE
---------------------------------------------------------------- ----------
UNIT CON_ID
------------ ----------
total PGA used for auto workareas 0
bytes 0
maximum PGA used for auto workareas 0
bytes 0
total PGA used for manual workareas 0
bytes 0
NAME VALUE
---------------------------------------------------------------- ----------
UNIT CON_ID
------------ ----------
maximum PGA used for manual workareas 0
bytes 0
over allocation count 0
0
bytes processed 29732864
bytes 0
NAME VALUE
---------------------------------------------------------------- ----------
UNIT CON_ID
------------ ----------
extra bytes read/written 0
bytes 0
cache hit percentage 100
percent 0
recompute count (total) 281
0
21 rows selected.
다음 포스트: [Oracle] Select 문장의 실행 원리
참고
- <오라클 관리 실무> 서진수 지음
