이전 포스트: [Oracle] Oracle Architecture
다음 포스트: [Oracle] Oracle Background Process
1. SELECT 문장의 실행 원리
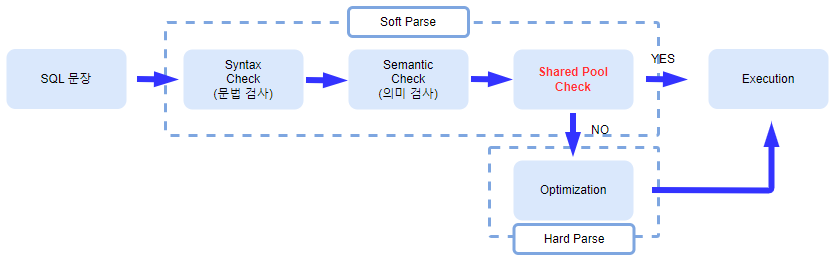
사용자가 SELECT 문장을 수행하면 서버 쪽에서는 아래 그림의 4단계로 해당 문장이 수행됩니다.

1) Parse(구문 분석 단계)
-
사용자가 SQL 문장을 수행하면 사용자 PC 쪽에 User Process라는 프로세스가 해당 SQL 문장을 서버의 Server Process로 전달해줍니다.
(User Process: SQL을 작성하는 프로그램(SQL*PLUS,SQL Developer,Toad,Orange))
이제부터 User Process는 결과가 나올 때까지 기다립니다. -
User Process로부터 SQL 문장을 받은 Server Process는
Syntax Check(문법 검사)->Semantic Check(의미검사)를 수행한 후권한 검사(어떤 사용자가 해당 오브젝트에 접근할 수 있는 권한이 있는지 확인하는 과정)를 수행합니다.
(일반 소스코드에서 컴파일 단계에 해당한다고도 볼 수 있는Parse(파스)과정입니다)
Syntax Check(문법 검사): SELECT, FROM, WHERE 같이 Oracle에서 미리 정해놓은 키워드를 검사Semantic Check(의미 검사): Oracle에서 미리 정해놓은 키워드 사이사이에 테이블 이름, 컬럼 이름과 같은 부분들을 검사
- Shared Pool의
Library Cache에서 공유되어 있는 실행계획이 있는지를 검사합니다(여기까지가Soft Parse)
(Library Cache: 한 번이라도 실행된 SQL, PL/SQL 문장과 해당 문장의 실행계획이 공유되어 있는 공간)
- 만약 공유되어 있는 실행계획이 있다면 바로
Execution단계로 넘어가고, 아니라면옵티마이저를 찾아가서 실행계획을 만들어 달라고 요청합니다.Optimizer(옵티마이저): Server Process로부터 요청을 받은 옵티마이저는Data Dictionary등을 참조해 실행계획을 생성합니다(Soft Parse에 비해 시간도 오래 걸리고 힘든 과정이라Hard Parse)- 옵티마이저는 실행계획을 만들 때 여러 개를 만들고, 거기서 비용을 따져서 가장 효율적인 실행계획 1가지를 선택합니다.
- 실행계획을 받은 Server Process는 실행계획을
Library Cache에 등록하고,PGA로 복사해서 가져온 후Execution단계로 넘어갑니다.
Soft Parse
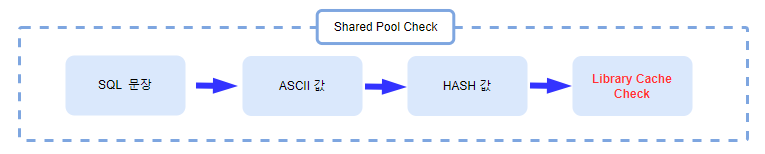
User Process(사용자 PC)가 SQL 문장을 Server Process(서버)로 전달하면 Server Process는 SQL Parser를 통해서 각 SQL 문장에 쓰인 키워드나 컬럼명 등을 분석해서 Parse Tree를 생성합니다.
Parse Tree 생성 과정에서 Syntax Check 를 수행하고, 이상이 없으면 Semantic Check를 수행합니다. 만약 키워드의 스펠링이 틀렸거나 문법이 틀렸을 경우 Parse Tree 생성 과정에서 오류가 발생하게 되고, Syntax Check를 무사히 거쳤으나 없는 테이블명을 조회하려고 했을 경우에는 Semantic Check에서 오류가 발생합니다.
Syntax Check와 Semantic Check 과정을 거치면서 해당 문법이 올바른지, 해당 테이블이 존재하는지 여부를 알기 위해 Data Dictionary를 사용하게 됩니다. 자주 사용하는 Data Dictionary는 SGA의 Shared Pool 안에 있는 Dictionary Cache에 캐싱해둡니다.
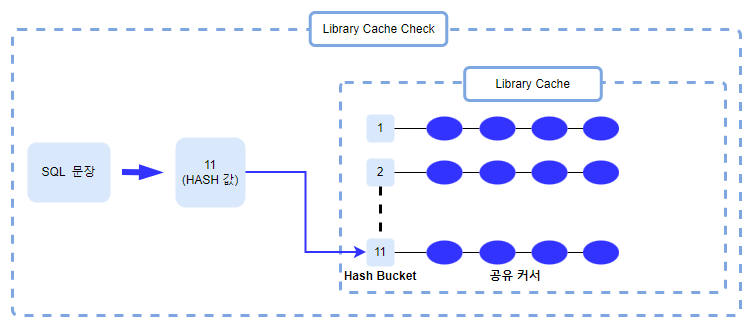
이 과정을 거쳐서 해당 SQL 문장에 오류가 없다면 SQL 문장을 ASCII 값(숫자 값)으로 변경한 후 해당 숫자 값을 HASH 함수를 통해 특정 HASH 값으로 변경합니다. 여기서 얻은 HASH 값과 Shared Pool 안에 있는 Library Cache에 있는 HASH 값들을 비교해서 동일한 값이 있는지 확인합니다(이 과정을 커서 공유 또는 Soft Parse라고 합니다).
Soft Parse: 어떤 길을 갈 때 예전에 가봤던 길을 가는 것
Hard Parse: 어떤 길을 갈 때 가본 적이 없어서 물어보면서 가는 것
HASH 값이 들어가 있는 부분을 Hash Bucket(해쉬 버킷)이라고 합니다. 그리고 그 해쉬 버킷 안에는 커서(cursor)들이 들어있습니다. 커서란 메모리에 어떤 데이터를 저장하기 위해 만드는 임시 저장 공간입니다. 일반적으로 공유 커서, 세션 커서, 어플리케이션 커서가 있습니다. 이 중에서 공유 커서의 역할은 이미 한 번 수행되었던 SQL 문장의 실행계획과 관련 정보를 보관하고 있다가 재활용 함으로써 Hard Parse의 부담을 줄여 SQL 문장의 수행 속도를 빠르게 하는 것입니다.
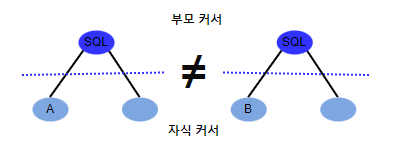
한편, 공유 커서는 부모 커서와 자식 커서로 나뉘게 되는데, SQL 문장 자체에 대한 값은 부모 커서에 있지만 사용자나 옵티마이저 모드 같은 정보는 자식 커서에 있게 됩니다. 따라서, A와 B가 각각 다른 계정으로 DB에 로그인 한 후 동일한 SQL 문장을 실행했다면 같은 부모 커서를 조회하더라도 자식 커서가 서로 달라 커서 공유를 실패합니다.
일반적으로 Library Cache에는 수많은 SQL 문장과 실행 계획이 들어있기 때문에 실행 계획을 찾을 때 커서를 하나씩 찾아보는 것은 시간이 너무 오래 걸립니다. 그래서 Oracle은 어떤 커서에 어떤 데이터가 들어있는 지를 Hash List를 통해 관리합니다. Hash List에 들어있는 정보들은 Chain 구조로 데이터가 연결되어 있습니다.
Hash 값을 통해 Library Cache에서 일치하는 값을 찾는 과정은 Hash Bucket을 찾은 것입니다. 그리고 그 안에 커서를 조회하게 될텐데, 커서들이 메모리 상에 연속적으로 저장되어 있진 않습니다. 빈자리가 있으면 그 자리에 저장하는 Heap 구조이기 때문입니다. Heap 구조는 데이터를 저장할 때는 속도가 빠르지만 데이터를 찾을 때는 시간이 오래 걸린다는 단점이 있습니다. 그래서 Hash List에서 연관된 데이터를 Chain 구조로 저장해서 데이터를 찾기 쉽게 해줍니다.
그런데 문제는 Hash List는 1개 밖에 없습니다. 그렇다면 수많은 사용자가 하나의 Hash List를 조회하려 한다면 문제가 발생하겠죠. 그래서 Oracle에서는 Library Cache를 탐색하기 위해서는 반드시 Library Cache Latch를 갖도록 합니다. Hash List를 조회하기 위한 번호표를 받아 차례대로 조회할 수 있도록 합니다. 어쨌거나 한 번에 결국 내 순서가 될 때까지 다른 사용자는 기다려야 하기에 성능이 저하될 수 밖에 없습니다(이 문제를 해결하기 위해서 Session_Cached_Cursors라는 파라미터를 제공합니다).
Hard Parse
Library Cache에 실행 계획이 존재하지 않는다면, 옵티마이저를 통해 실행 계획을 받고 Execution 단계로 넘어갑니다.
옵티마이저는 크게 Rule Based Optimizer(RBO)와 Cost Based Optimizer(CBO)로 나눌 수 있습니다.
RBO
Server Process가 실행계획을 세워 달라고 요청이 들어오면 이름대로 미리 정해져 있는 규칙을 사용해서 실행 계획을 세웁니다.
| Level | 접근 경로 |
|---|---|
| 1 | Single Row by Rowid |
| 2 | Single Row by Cluster Join |
| 3 | Single Row by Hash Cluster Key with Unique or Primary Key |
| 4 | Single Row by Unique or Primary Key |
| 5 | Clustered Join |
| 6 | Hash Cluster Key |
| 7 | Indexed Cluster Key |
| 8 | Composite Index |
| 9 | Single-Column Indexes |
| 10 | Bounded Range Search on Indexed Columns |
| 11 | Unbounded Range Search on Indexed Columns |
| 12 | Sort-Merge Join |
| 13 | MAX or MIN of Indexed Column |
| 14 | ORDER BY on Indexed Column |
| 15 | Full Table Scan |
어떤 SQL문이 있다면 15번부터 하나씩 대입하면서 적당한 실행 계획을 찾게 됩니다.
예를 들어, select * from emp where empno=7902;라는 SQL 문이 있고, empno 컬럼에는 인덱스가 생성되어 있다고 가정해 봅시다. Server Process가 RBO를 찾아가서 실행 계획을 요청했다면, RBO는 위 테이블을 꺼내놓고 15번부터 하나씩 대입하면서 적당한 실행 계획을 모두 찾습니다. 15번은 Full Scan이므로 무조건 가져가고, 14번에는 ORDER BY 구문이 없으므로 패스합니다. 마찬가지로 13번 역시 MAX, MIN이 없으므로 패스합니다. 이런 식으로 1번까지 모두 대입해보면 15번, 9번을 확보합니다. 여기서 가장 작은 숫자(9번)를 실행 계획으로 채택합니다.
RBO의 문제는 모든 SQL이 15가지 경우 안에서만 실행 계획을 만들어야 한다는 것입니다. 그래서 11g 버전 부터 RBO는 지원되지 않습니다.
CBO
CBO는 실행 계획을 세울 때 Data Dictionary 정보를 봅니다.
Hard Parse는 Soft Parse에 비해 수행 시간이 오래 걸리기 때문에 가능한 Soft Parse를 할 수 있도록 쿼리를 작성해 주는 것이 중요합니다.
만약 Hard Parse를 수행 해야 한다면, 옵티마이저가 실행 계획을 잘 세울 수 있도록 사람이 도와줘야 합니다. 사람이 도와줘야 한다? 옵티마이저는 Data Dictionary를 참고해서 실행 계획을 생성하는데, 중요한 점은 이 딕셔너리가 자동으로 업데이트 되는 것이 아니라는 것입니다. 옵티마이저가 항상 최신 정보를 가지도록 하기 위해서는 딕셔너리 관리를 사람이 해주어야 합니다. 좋은 인덱스 생성, 공간 관리 같은 일을 통해 좋은 실행 계획을 세울 수 있도록 도와주어야 합니다.
2) BIND(바인드)
전체 학생이 1,000명인 학교가 있다고 합시다.
학번과 이름을 이용해 학생의 정보를 조회한다고 하면 대충 SQL 문장은 아래와 같겠습니다.
select *
from 학생
where 학번 = ' '
and 이름 = ' ';이때, 각 학생에 대한 SQL 문장은 조건절(where) 이후의 학번과 이름만 다를 것입니다. 하지만 Parse 과정에서는 다른 SQL 문장으로 인식해서 Hard Parse를 매번 수행하게 됩니다. 1,000번 Hard Parse를 수행하도록 하지 않고 1번 Hard Parse를 수행하도록 하고 이후부터는 Library Cache에 캐싱되어 있는 Soft Parse를 이용한다면 훨씬 수행 속도가 개선될 것입니다.
이때 사용하는 것이 Bind 변수입니다. 학번과 이름을 Bind 변수 a와 b로 만든다면 SQL 문장은 아래와 같이 바뀔 것입니다.
select *
from 학생
where 학번 = a
and 이름 = b;그럼 1,000명의 정보를 조회해도 SQL 문장은 같은 문장으로 인식됩니다. 따라서 Soft Parse가 가능해집니다.
하지만 bind 변수에도 단점은 존재합니다. 만약 테이블에 입력된 데이터들이 한 쪽으로 편중(skewed)되어 있다면 bind 변수를 사용할 수 없습니다. 데이터가 편중되어 있다는 뜻은 테이블에 있는 데이터들이 균일한 비율이 아닌 특정 데이터가 집중적으로 많이 들어가 있다는 뜻입니다.
이에 대한 대안으로 histogram이 있습니다. 하지만 histogram을 이용할 경우 bind 변수를 사용할 수 없습니다.
어쨌거나 bind 기능은 Hard Parse를 줄이고 성능을 향상 시킬 수 있는 좋은 방안이기 때문에 꼭 사용하는 것이 좋습니다.
3) Execute(실행)
Parse와 Bind 단계를 거치고 나면 Execute 단계로 들어갑니다.
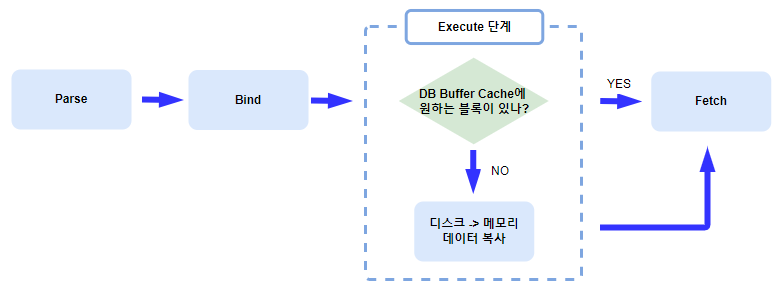
Execute 단계에서는 SGA 내 Database Buffer Cache의 블록들 중에 SQL 문장에 대해 캐싱되어 있는 값이 있는지 조회하고 캐싱되어 있다면 바로 Fetch를 수행합니다. Server Process가 DB Buffer Cache에서 데이터를 조회하는 원리는 찾는 블록의 주소를 Hash 값으로 만들고 이 Hash 값과 일치하는 값을 DB Buffer Cache의 Hash List에서 찾습니다.
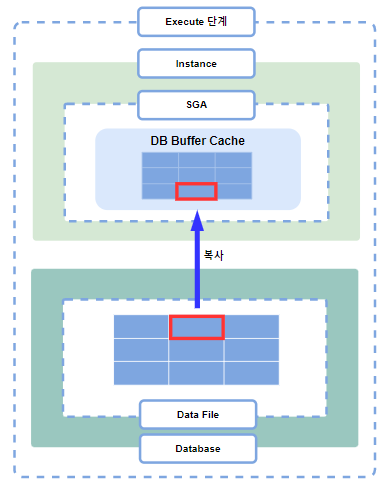
캐싱되어 있지 않다면 Server Process는 Database의 Data File에서 해당하는 블록을 DB Buffer Cache로 복사해옵니다.
블록(Block)
Oracle에서는 Data File -> DB Buffer Cache / DB Buffer Cache -> Data File로 데이터를 복사할 때 가장 최소 단위인 블록 단위로 움직입니다.
블록(Block): 여러 건의 데이터를 담은 작은 박스
DB_BLOCK_SIZE: 블록 크기를 결정하는 파라미터10g부터DB_BLOCK_SIZE의 디폴트값은8K- 이 크기가 크면 I/O를 줄일 수 있는 장점이 있는 반면에 공간 낭비가 많이 생길 수 있고 한 번
조회/변경할 때 많은 데이터를조회/변경해야 하므로 DB Buffer Cache에서wait가 많이 생겨 성능이 저하될 수 있음.
4) Fetch
DB Buffer Cache의 Block에서 원하는 데이터를 골라내서 User Process에 가져다 주는 과정이 Fetch(인출) 과정입니다.
과정 속에 정렬(sort)이 필요하다면 PGA에서 수행합니다.
(PGA 내 SQL Work Area의 Sort Area)
2. Update 문장의 실행 원리
update의 경우 Parse, Bind까지는 동일한 과정을 거치나 Execute 과정이 select에 비해 좀 더 복잡합니다.
DB Buffer Cache에 Server Process가 원하는 블록이 존재하는지 확인하고, 존재하지 않는다면 Data File에서 데이터 블록을 복사해오는 것까지는 동일합니다. 하지만, update(insert, delete까지 모두 포함)의 경우 데이터가 변경된다는 것을 의미합니다. 그래서 이와 관련된 작업이 추가됩니다.
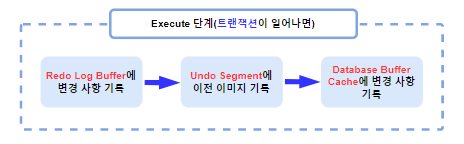
Server Process는 변경되는 데이터의 변경 내역을 Redo Log Buffer에 기록합니다. 그 후 Undo Segment에 이전 이미지를 기록한 후 DB Buffer Cache에 변경 사항을 기록합니다.
트랜잭션(Transaction): 데이터의 변경
참고
- <오라클 관리 실무> 서진수 지음
이전 포스트: [Oracle] Oracle Architecture
다음 포스트: [Oracle] Oracle Background Process
