
2-1 관계형 데이터베이스 개요
데이터베이스와 DBMS
데이터베이스 : 데이터의 집합. 꼭 형식을 갖추지 않아도 엑셀 파일을 모아 둔다면 그것 또한 데이터베이스임
DBMS: 데이터를 효과적으로 관리하기 위한 시스템
개인이 파일을 여러 개 묶어서 폴더에 보관하면 데이터를 찾고 관리하는데 많은 비용이 발생
이를 보다 시스템적으로 작동하게 만든 시스템을 DBMS 라고 한다 (ORACLE, MYSQL 등)
관계형 데이터베이스 구성 요소
계정 : 데이터의 접근 제한을 위한 여러 업무별 / 시스템별 계정이 존재
테이블 : DBMS의 DB 안에서 데이터가 저장되는 형식
스키마 : 테이블이 어떠한 구성으로 되어있는지, 어떠한 정보를 가지고 있는지에 대한 기본적인 구조를 정의
테이블
- 정의
엑셀에서의 워크시트처럼 행(로우)과 열(컬럼)을 갖는 2차원 구조로 구성, 데이터를 입력하여 저장하는 최소 단위
컬럼은 속성이라고 부르기도 함 (모델링 단계마다 부르는 용어가 다름) - 특징
하나의 테이블은 반드시 하나의 유저(계정) 소유여야 함
테이블간 관계는 일대일(1:1), 일대다(1:N), 다대다(N:N)의 관계를 가질 수 있음
테이블명은 중복될 수 없지만, 소유자가 다른 경우 같은 이름으로 생성 가능
ex) SCOTT 소유의 EMP 테이블 존재, HR 소유의 EMP 테이블 생성 가능
(같은 계정 내 동일한 객체명 생성 불가)
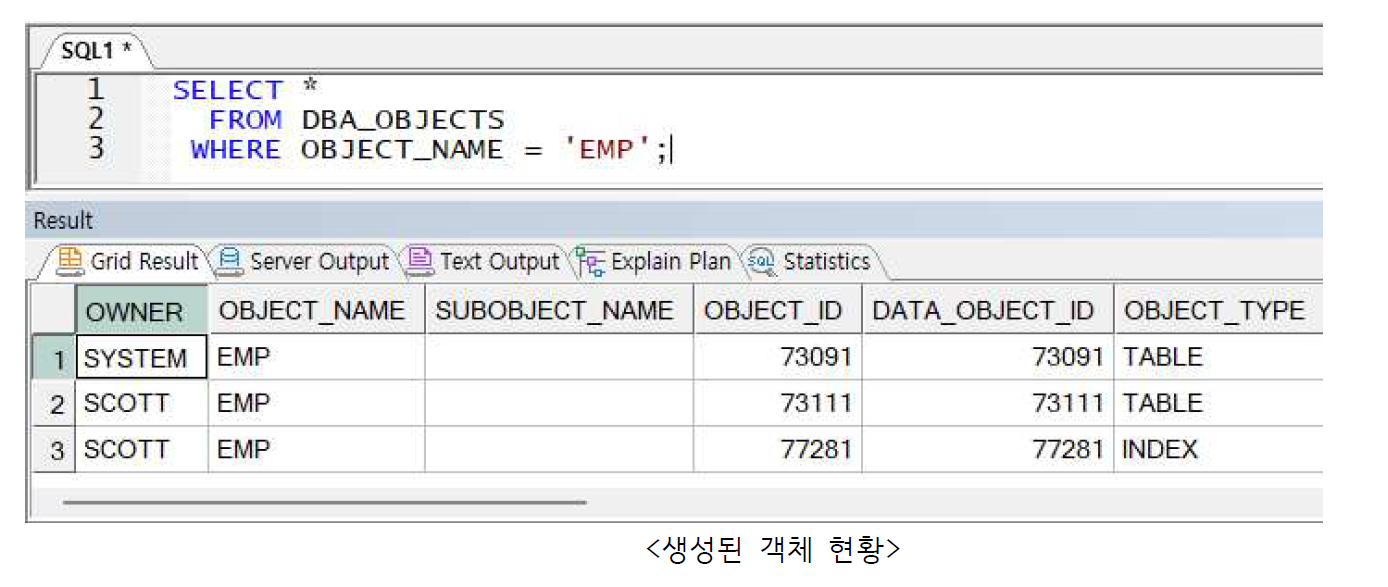
테이블은 행 단위로 데이터 입력, 삭제되며 수정은 값의 단위로 가능
ex) 사원테이블에 새로운 사원 정보를 사원번호, 사원이름 등의 테이블 내 모든 컬럼의 값을 동시에 전달하여 입력, 삭제 시에는 해당 사원의 모든 정보가 삭제됨(수정 시에는 특정 직원의 급여만 수정 가능)
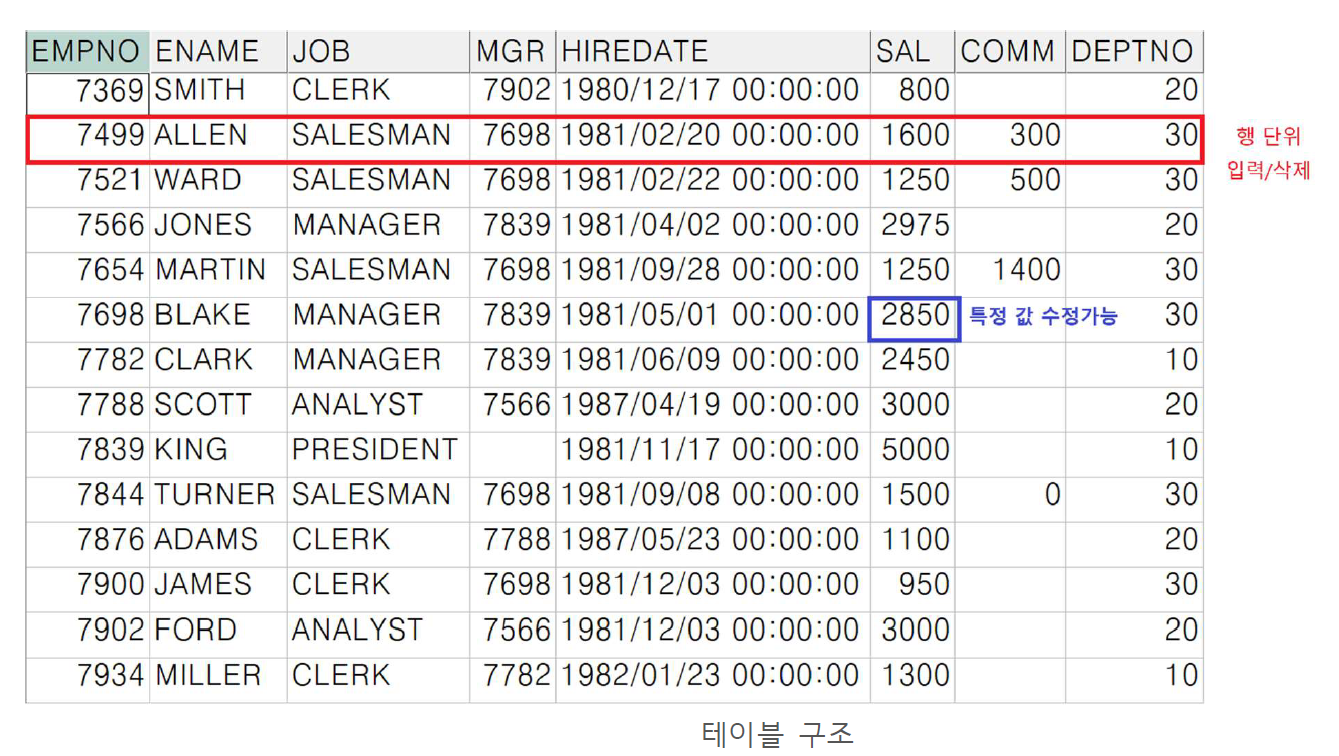
※ 객체 : DBMS에서의 객체는 생성하고 변경할 수 있는 하나의 관리 대상
SQL (Structured Query Language)
관계형 데이터베이스에서 데이터 조회 및 조작, DBMS 시스템 관리 기능을 명령하는 언어
데이터 정의(DDL), 데이터 조작(DML), 데이터 제어 언어(DCL) 등으로 구분
SQL 문법은 대,소문자를 구분하지 X
관계형 데이터베이스 특징
데이터의 분류, 정렬, 탐색 속도가 빠름
신뢰성이 높고, 데이터의 무결성 보장
기존의 작성된 스키마를 수정하기 어려움
데이터베이스의 부하를 분석하는 것이 어려움
데이터 무결성
데이터의 정확성과 일관성을 유지하고, 데이터에 결손과 부정합이 없음을 보증하는 것
데이터베이스에 저장된 값과 그것을 표현하는 현실의 비즈니스 모델의 값이 일치하는 정확성을 의미함
데이터 무결성을 유지하는 것이 데이터베이스 관리시스템에 중요한 기능
데이터 무결성 종류
- 개체 무결성 : 테이블의 기본키를 구성하는 컬럼(속성)은 NULL 값이나 중복 값을 가질 수 없음
- 참조 무결성 : 외래키 값은 NULL이거나 참조 테이블의 기본키 값과 동일해야 한다.
(외래키란 참조 테이블의 기본키에 정의된 데이터만 허용되는 구조이므로) - 도메인 무결성 : 주어진 속성 값이 정의된 도메인에 속한 값이어야 함
- NULL 무결성 : 특정 속성에 대해 NULL을 허용하지 않는 특징
- 고유 무결성 : 특정 속성에 대해, 값이 중복되지 않는 특징
- 키 무결성 : 하나의 릴레이션(관계)에는 적어도 하나의 키가 존재해야 함
(테이블이 서로 관계를 가질 경우 반드시 하나 이상의 조인키를 가짐)
※ 도메인 : 각 컬럼(속성)이 갖는 범위
※ 릴레이션 : 테이블간 관계를 말함
※ 튜플 : 하나의 행을 말함
※ 키 : 식별자
ERD(Entity Relationship Diagram)
ERD란 테이블 간 서로의 상관 관계를 그림으로 표현한 것
ERD의 구성요소에는 엔터티(Entity), 관계(Relationship), 속성(attribute)가 있다.
-> 현실 세계의 데이터는 이 3가지의 구성으로 모두 표현 가능
2-2 SELECT 문
SQL 종류
| 구분 | 특징 |
|---|---|
| DDL | CREATE, ALTER, DROP, TRUNCATE |
| DML | INSERT, DELETE, UPDATE, MERGE |
| DCL | GRANT, REVOKE |
| TCL | COMMIT, ROLLBACK |
| DQL | SELECT |
SELECT문 구조
SELECT문은 다음과 같이 6개 절로 구성
각 절의 순서대로 작성해야 함
(GROUPBY 와 HAVING은 서로 바꿀 수 있지만 보통 사용하지 않음)
SELECT문의 내부 파싱(문법적 해석) 순서는 나열된 순서와는 다름
FROM > WHERE > GROUP BY > HAVING > SELECT > ORDER BY 순서대로 실행함

SELECT 절
SELECT 문장을 사용하여 불러올 컬럼명, 연산 결과를 작성하는 절
*를 사용하여 테이블 내 전체 컬럼명을 불러올 수 있음
원하는 컬럼을 ,로 나열하여 작성 가능 (순서대로 출력함)
표현식이란 원래의 컬럼명을 제외한 모든 표현 가능한 대상(연산식, 기존 컬럼의 함수 변형식 포함)
문법

특징
SELECT 절에서 표시할 대상 컬럼에 Alias(별칭) 지정 가능
대소문자를 구분하지 않아도 인식한다.
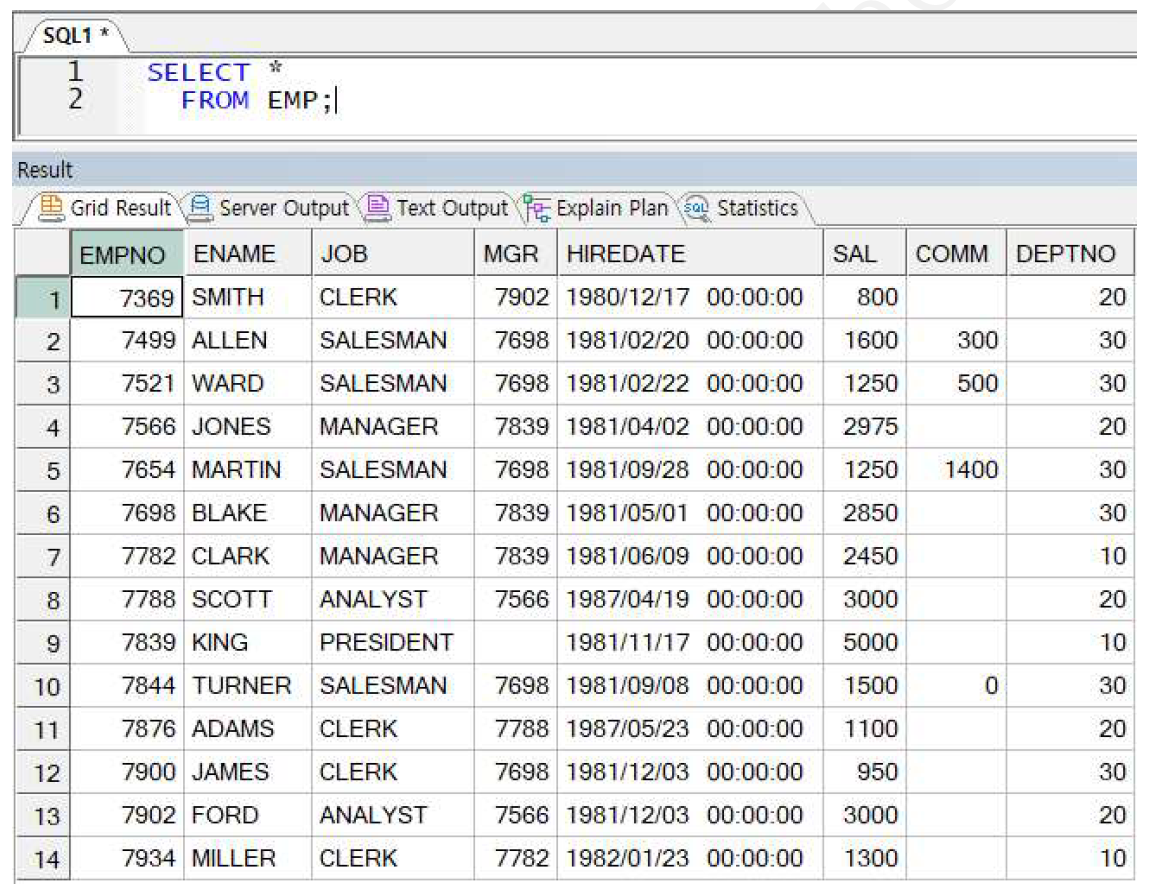
ex) emp 테이블의 전체 컬럼 조회
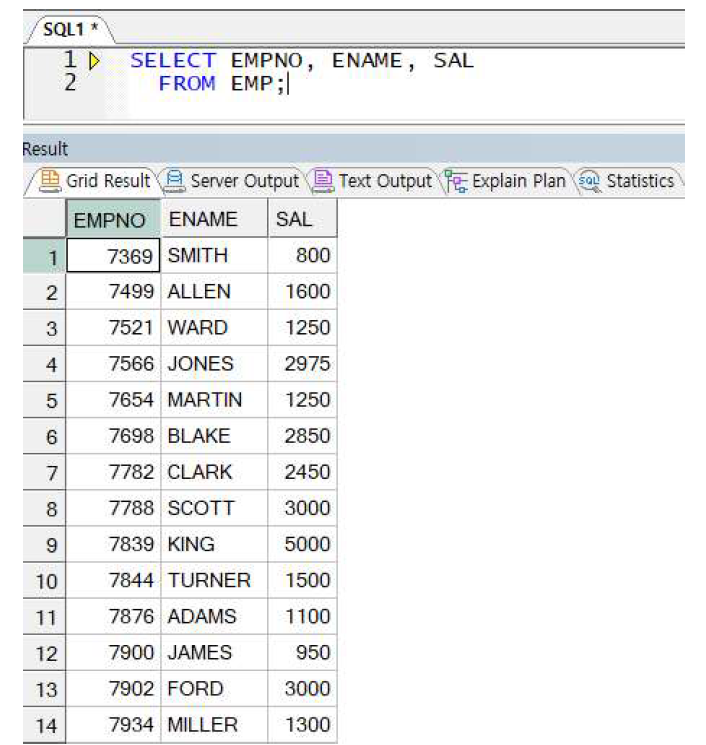
ex) emp 테이블에서 특정 컬럼 조회
ex) 표현식을 사용하여 원본과 다른 데이터 출력 가능
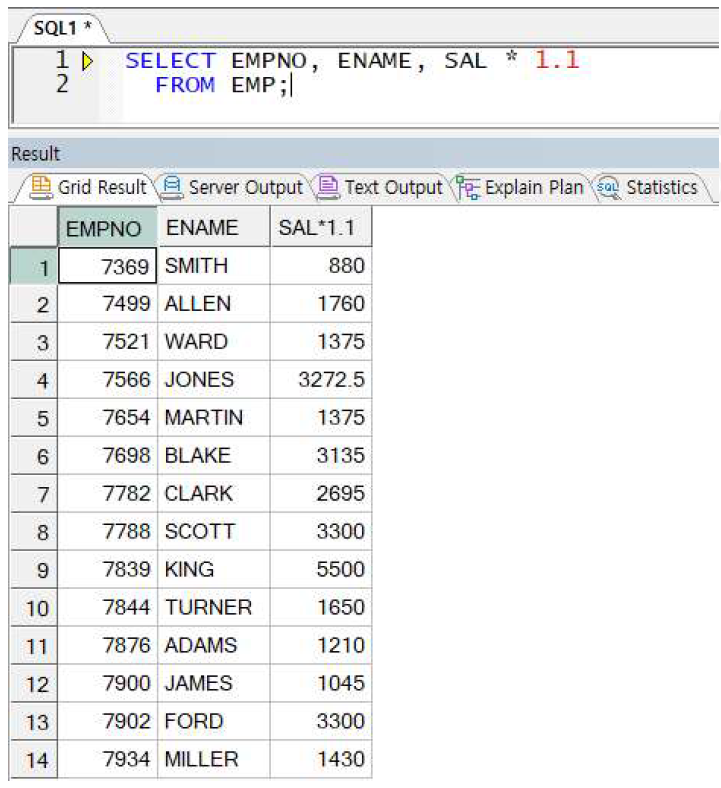
☞ SAL * 1.1이라는 컬럼은 없지만 기존 컬럼의 값을 사용하여 연산결과를 SELECT 절에서 정의하여 출력할 수 있음. 이런 표현 가능한 모든 수식을 표현식이라고 함 (함수식, 연산식 등)
컬럼 Alias(별칭)
컬럼명 대신 출력할 임시 이름 지정
(SELECT 절에서만 정의 가능, 원본 컬럼명을 변경되지 X)
컬럼명 뒤에 AS와 함께 컬럼 별칭 전달(AS는 생략 가능)
특징 및 주의사항
SELECT문보다 늦게 수행되는 ORDER BY절에서만 컬럼 별칭 사용 가능
(그 외 절에서 사용시 에러 발생)
한글 사용 가능 (한글 지원 캐릭터셋 설정 시)
이미 존재하는 예약어는 별칭으로 사용 불가
ex) avg, count, decode, SELECT, FROM 등
다음의 경우 별칭에 반드시 쌍따옴표 전달 필요
1) 별칭에 공백을 포함하는 경우
2) 별칭에 특수문자를 포함하는 경우("_" 제외)
3) 별칭 그대로 전달할 경우 (입력한 대소를 그대로 출력하고자 할 때)
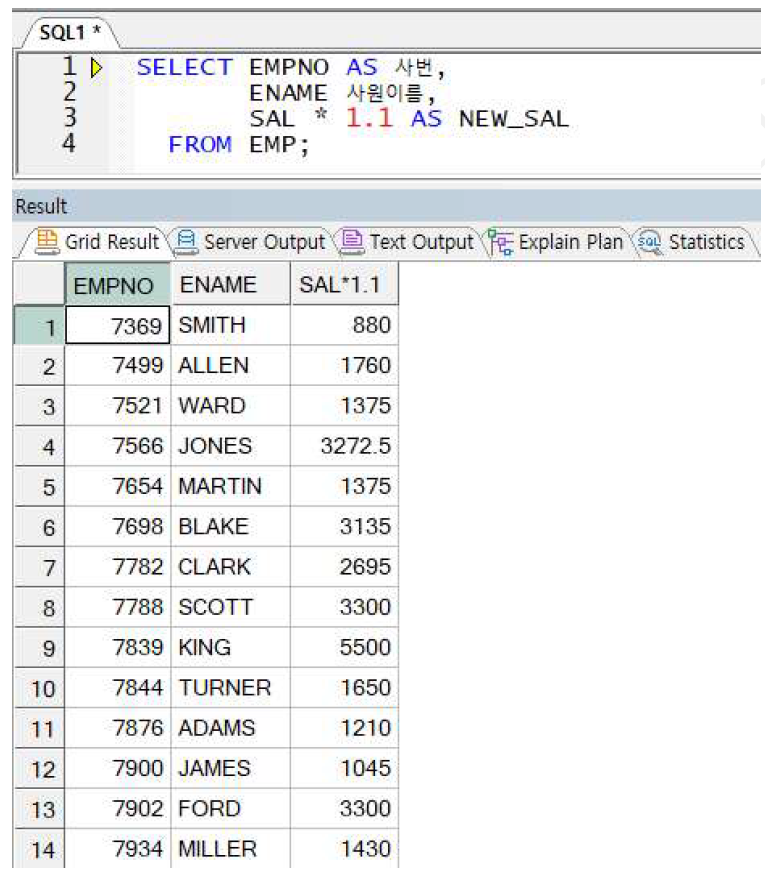
예제) 별칭 사용 예 (AS 생략 가능)
예제) 별칭 선언 시 쌍따옴표가 필요한 경우
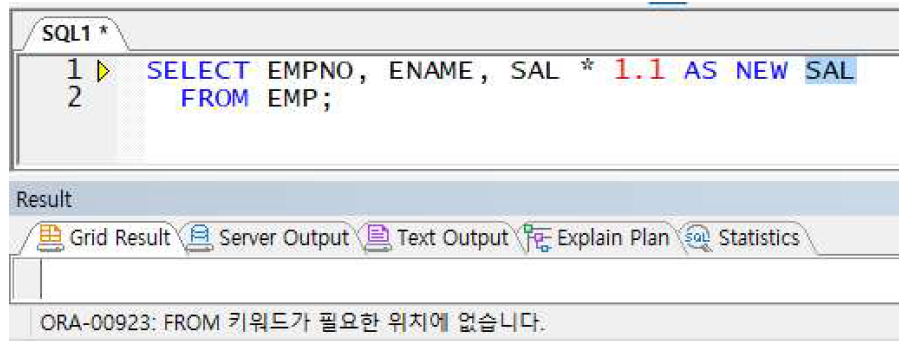
-> 쌍따옴표 사용하지 않아 에러 발생함
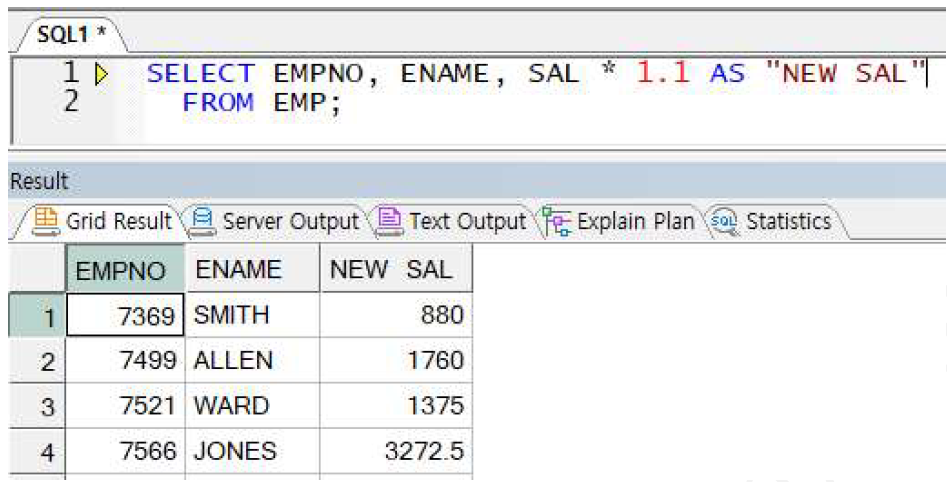
-> 별칭에 공백 포함 시 반드시 쌍따옴표와 함께 전달
FROM 절
테이블을 불러올 테이블명 또는 뷰명 전달
테이블 여러 개 전달 가능(컴마로 구분) -> 조인 조건 없이 테이블명만 나열 시 카타시안 곱 발생 주의!
테이블 별칭 선언 가능(AS 쓰지 않음)
※ 테이블 별칭 선언 시 컬럼 구분자는 테이블 별칭으로만 전달(테이블명으로 사용 시 에러 발생)
ORACLE에서는 FROM절 생략 불가
(의미상 필요 없는 경우 DUAL 테이블 선언)
※ ORACLE 23c 버전부터는 생략 가능
MSSQL에서는 FROM절 필요 없을 경우 생략 가능 (오늘 날짜 조회 시)
※ 뷰 : 테이블과 동일하게 데이터를 조회할 수 있는 객체이지만 테이블처럼 실제 데이터가 저장된 것이 아닌, SELECT문 결과에 이름을 붙여 그 이름만으로 조회가 가능하도록 한 기능
예제) ORACLE에서의 FROM절 생략 시 에러 발생 케이스 (DUAL 테이블 사용)
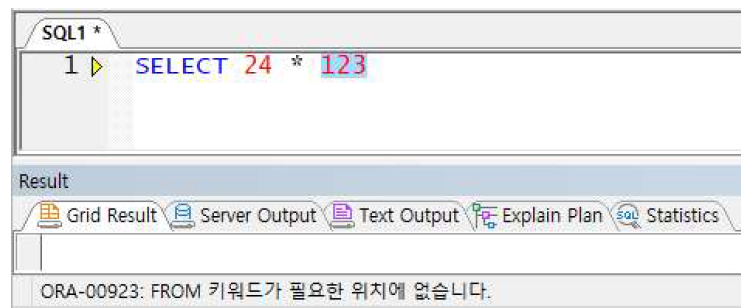
-> ORACLE에서 FROM절 생략 시 에러 발생
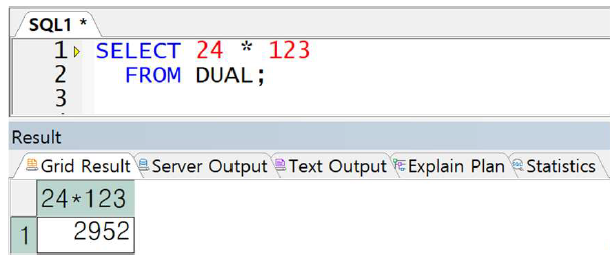
-> 의미상 FROM 절이 필요 없는 경우 DAUL 전달
예제) 테이블 별칭 사용 예제
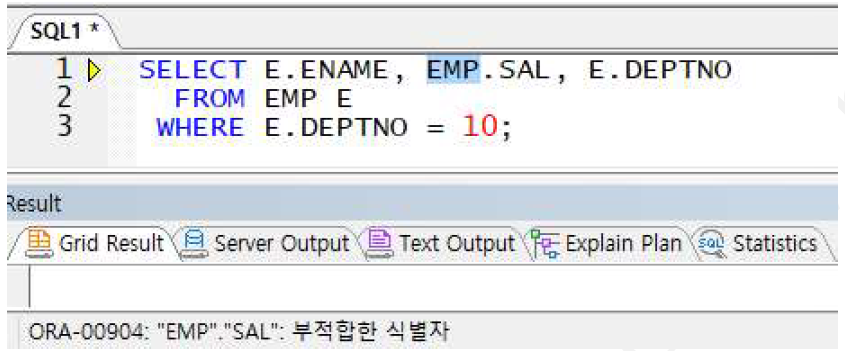
-> 잘못된 사용 예
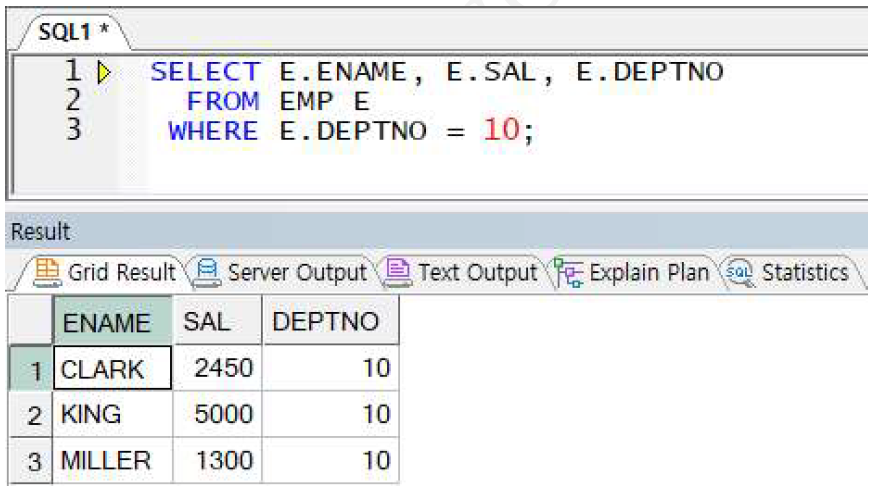
-> 테이블 별칭을 선언한 경우 컬럼참조(동일한 이름의 컬럼을 구분하기 위해 테이블명 또는 별칭을 컬럼명 앞에 전달)는 테이블명으로 사용 불가
2-3 함수
함수정의
input value가 있을 경우 그에 맞는 output value를 출력해주는 객체
input value와 out value의 관계를 정의한 객체
from 절을 제외한 모든 절에서 사용가능
함수기능
기본적인 쿼리문을 더욱 강력하게 해줌
데이터 계산을 수행
개별 데이터의 항목을 수정
표시할 날짜 및 숫자 형식을 지정
열 데이터의 유형(data type)을 변환
함수의 종류 (입력값의 수에 따라)
단일행 함수와 복수행 함수로 구분!
단일행 함수: input과 output의 관계가 1:1
복수행 함수: 여러 건의 데이터를 동시에 입력 받아서 하나의 요약값을 리턴
(그룹함수 또는 집계함수라고도 함)
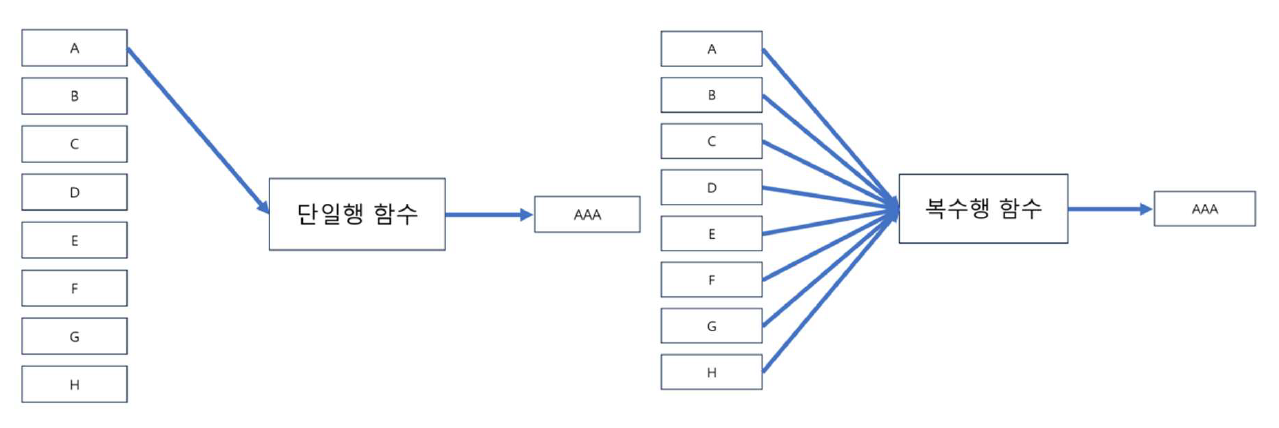
입/출력값의 타입에 따른 함수 분류
1) 문자형 함수
문자열 결합, 추출, 삭제 등을 수행
단일행 함수 형태
output은 대부분 문자값 (LENGTH, INSTR 제외)
문자함수 종류
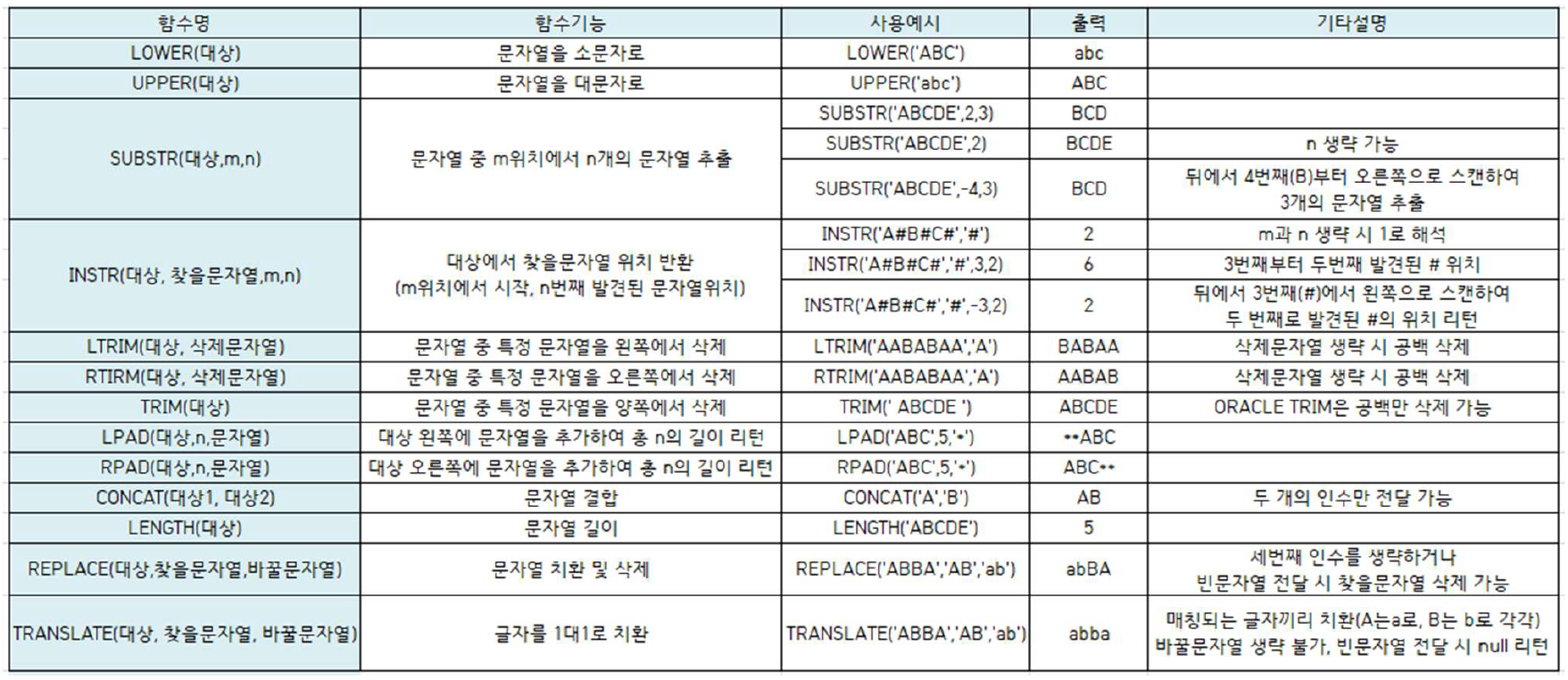
SQL-Server)
SUBSTR -> SUBSTRING
LENGTH -> LEN
INSTR -> CHARINDEX
2) 숫자형 함수
숫자를 입력하면 숫자 값을 반환
단일행 함수 형태의 숫자함수
ORACLE과 SQL-Server 함수 거의 동일
숫자함수 종류
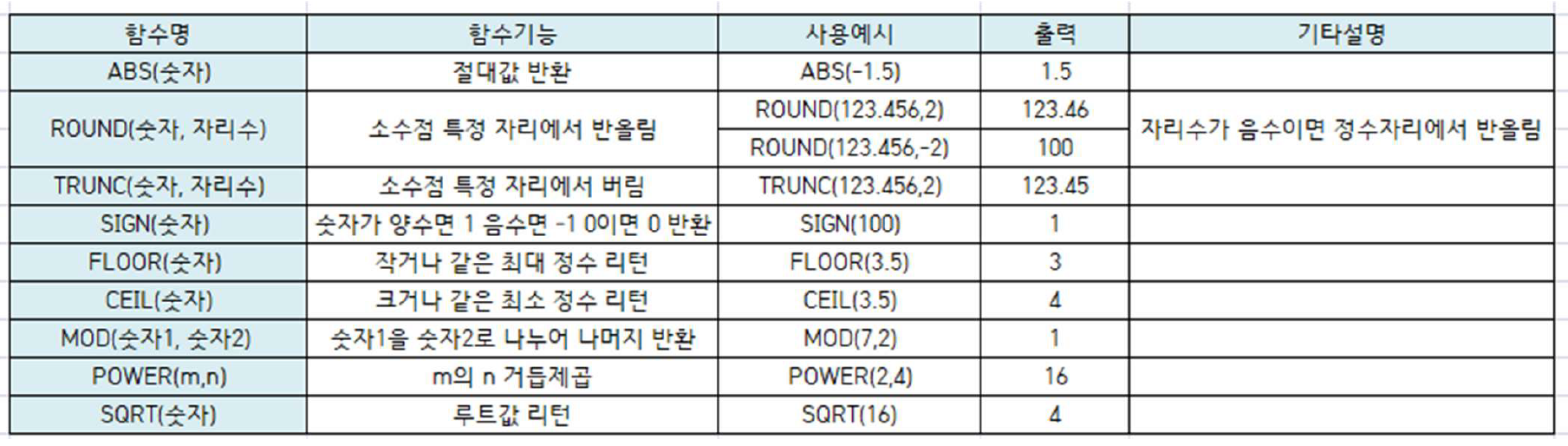
3) 날짜형 함수
날짜 연산과 관련된 함수
ORACLE과 SQL-Server 함수 거의 다름
날짜함수 종류
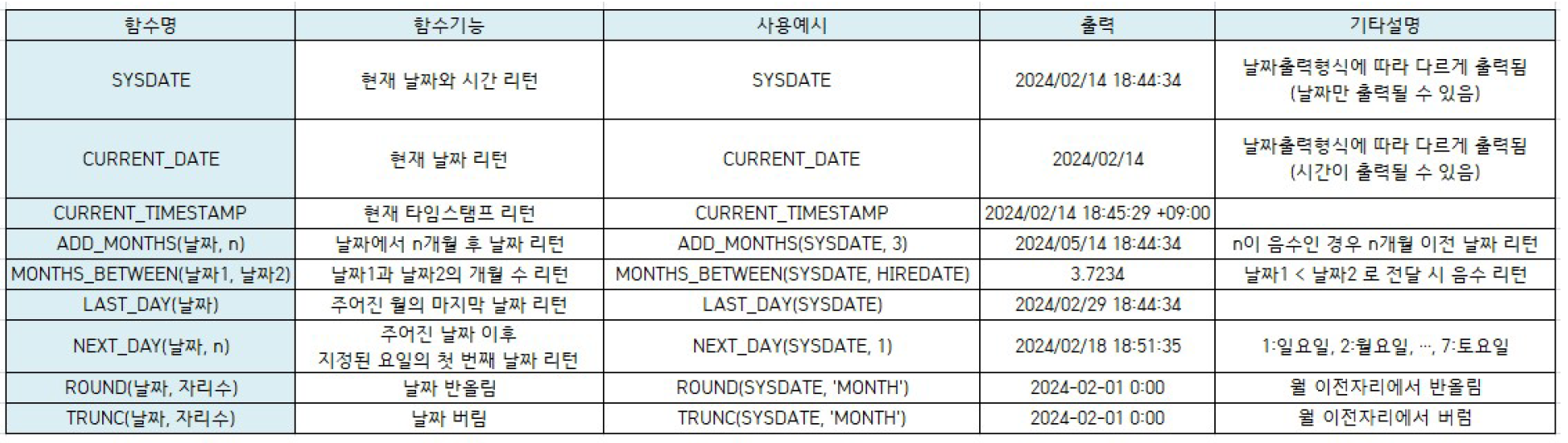
SQL-Server)
SYSDATE -> GETDATE
ADD_MONTHS -> DATEADD (월 뿐만 아니라 모든 단위 날짜 연산 가능)
MONTHS_BETWEEN -> DATEDIFF (두 날짜 사이의 년, 월, 일 추출)
4) 변환함수
값의 데이터 타입을 변환
문자를 숫자로, 숫자를 문자로, 날짜를 문자로 변경
변환함수 종류

SQL-Server)
TO_NUMBER, TO_DATE, TO_CHAR -> CONVERT(포맷 전달 시)
단순 변환일 경우 주로 CAST 사용
5) 그룹함수
다중행 함수
여러 값이 input값으로 들어가서 하나의 요약된 값으로 리턴
group by와 함께 자주 사용됨
ORACLE과 SQL-server 거의 동일
그룹함수의 종류
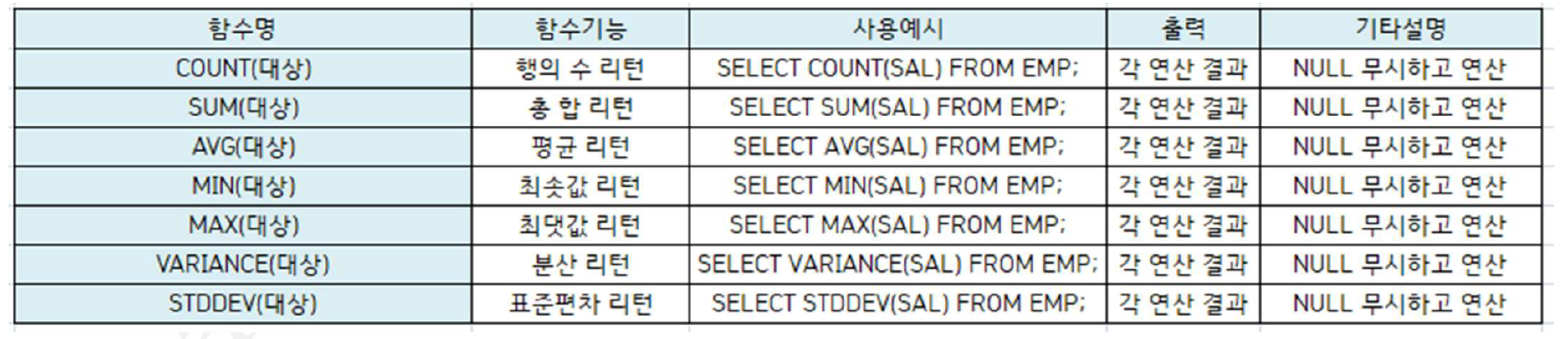
SQL-server)
VARIANCE -> VAR
STDDEV -> STDEV
6) 일반함수
기타 함수(널 치환 함수 등)
일반(기타)함수 종류

DECODE 사용 예제1
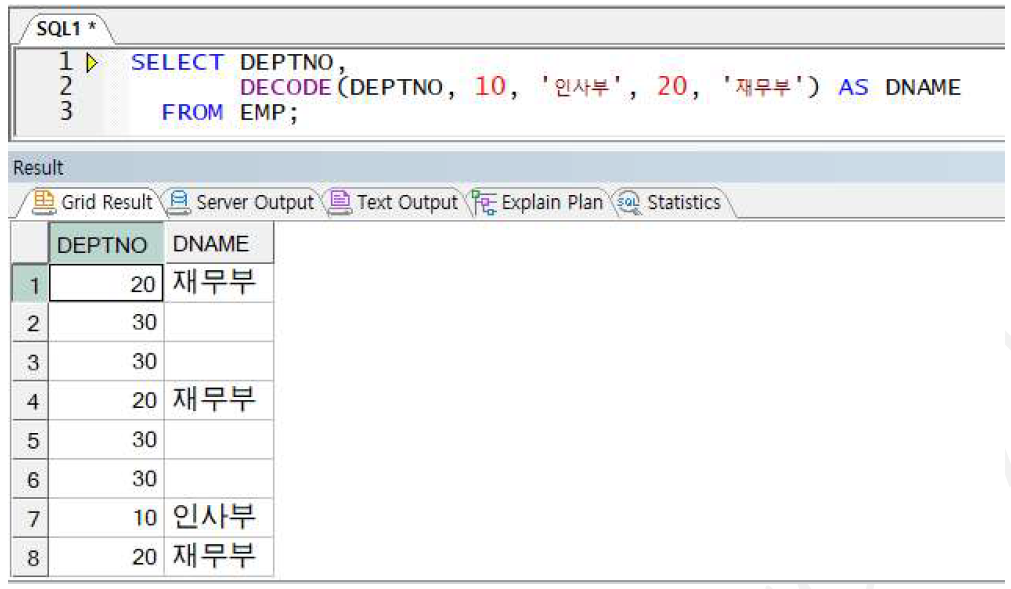
-> 부서번호가 10번이면 인사부, 20번이면 재무부, 나머지는 널 리턴
DECODE 사용 예제2
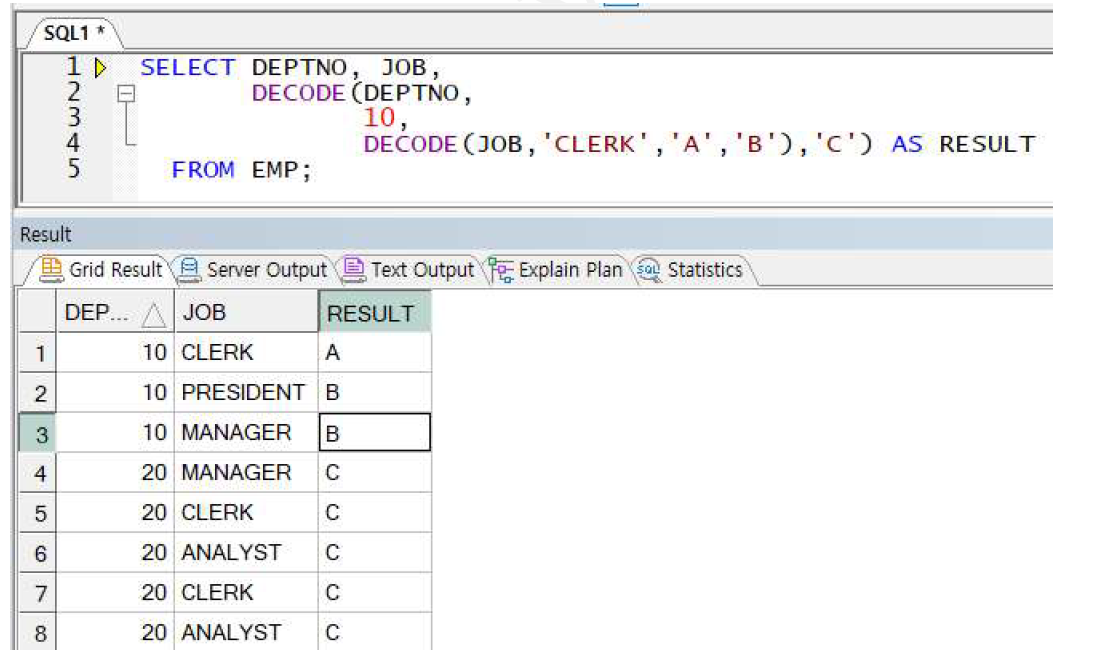
-> DEPTNO가 10이면서 JOB이 CLERK이면 A, CLERK 아니면 B, DEPTNO가 10이 아니면 C
NVL,NVL2 사용 예제
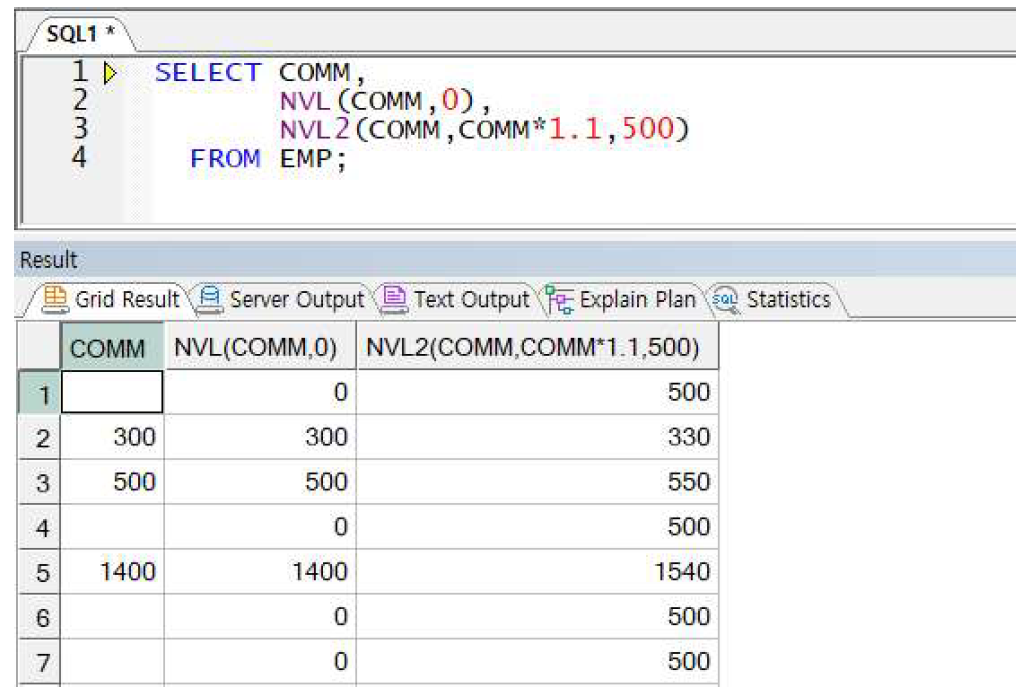
-> NVL2의 경우 NVL이랑 다르게 COMM의 값이 널이 아닐 때도 치환값 정의 가능
-> NVL2의 경우 COMM이 널이 아니면 10% 인상값, 널이면 500 리턴
COALESCE 사용 예제
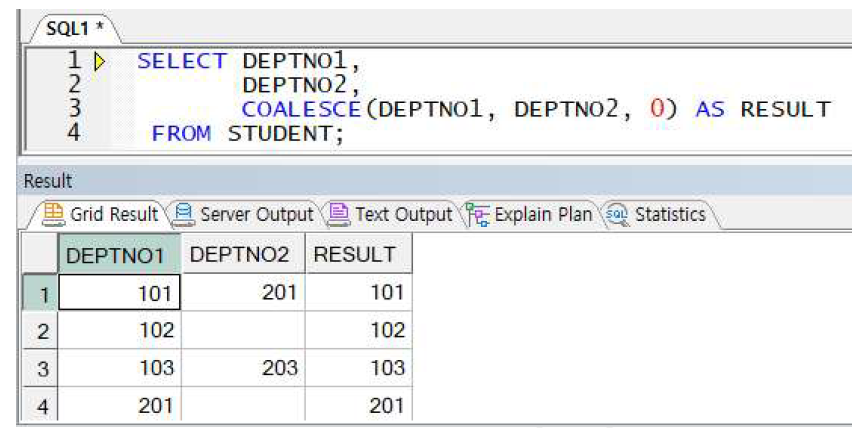
-> DEPTNO1과 DEPTNO2중 널 아닌값 출력 (둘 다 널이 아니면 맨 앞 순서대로 출력).
모두 널이면 0 출력
CASE문 사용 예제1
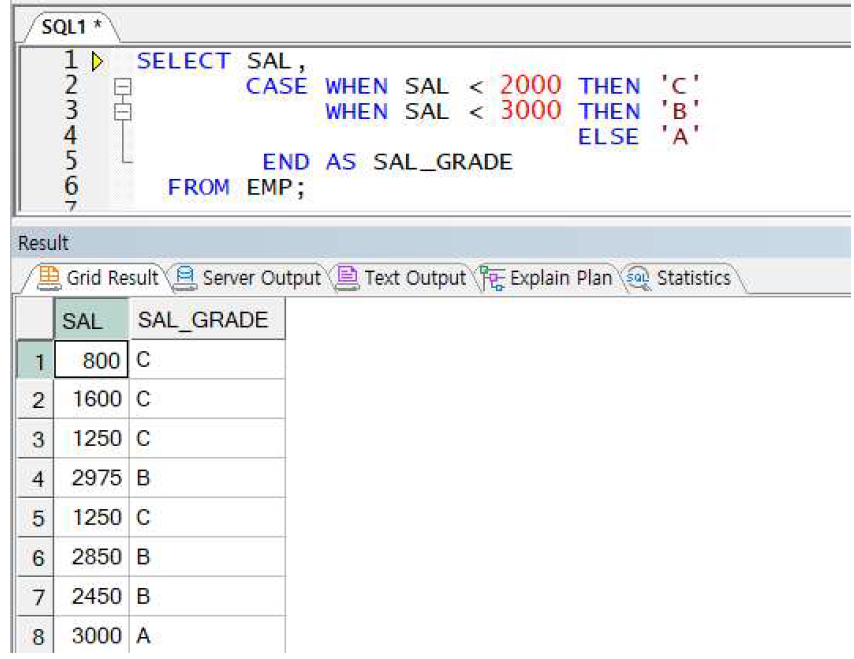
-> CASE문을 사용하여 여러 조건(대소비교 가능)에 대한 치환 및 연산 가능!
CASE문 사용 예제2
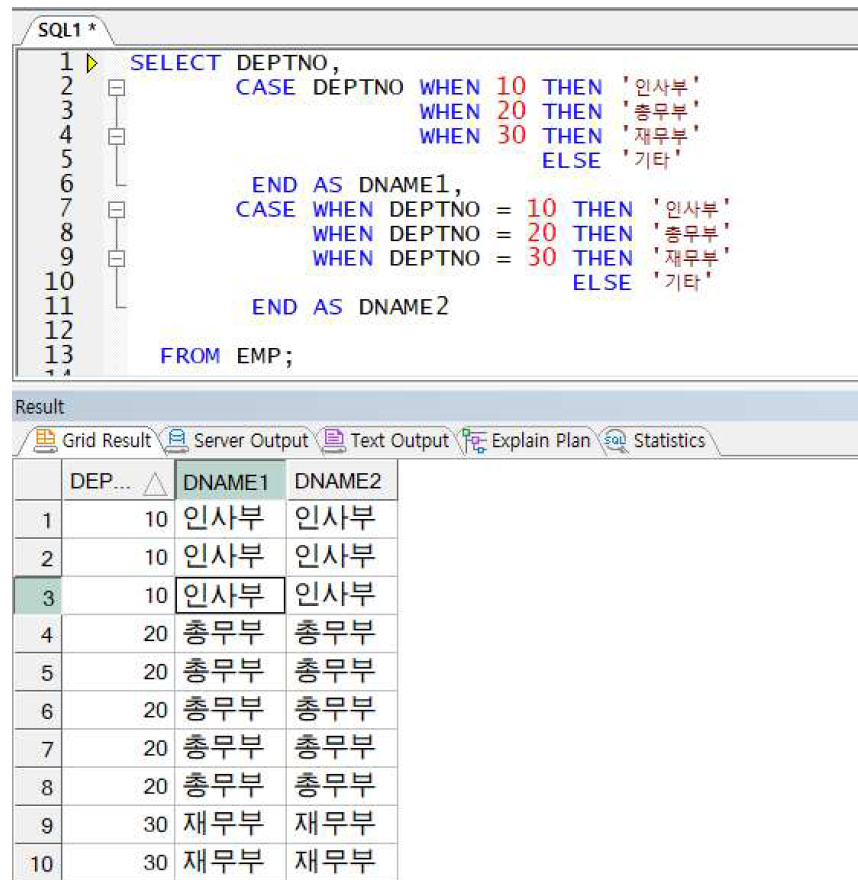
-> 동등비교 시 위처럼 비교대상(DEPTNO)를 CASE와 WHEN 사이에 배치하면서 WHEN절 마다 반복하지 않아도 됨(이 때 DEPTNO. 데이터 타입과 WHEN절의 명시된 비교대상의 데이터타입 반드시 일치해야 함)
2-4 Where 절
where 절
테이블의 데이터 중 원하는 조건에 맞는 데이터만 조회하고 싶을 경우 사용
(엑셀의 필터기능과 유사)
여러 조건 동시 전달 가능(AND와 OR로 조건 연결)
NULL 조회 시 IS NULL/ IS NOT NULL 연산자 사용(=연산자로 조회 불가)
연산자를 사용하여 다양한 표현 가능
조건 전달 시 비교 대상의 데이터 타입 일치하는 것이 좋음
ex) EMP 테이블의 부서번호 컬럼의 데이터타입은 숫자인데 문자상수로 비교 시 성능 문제 발생할 수 있음
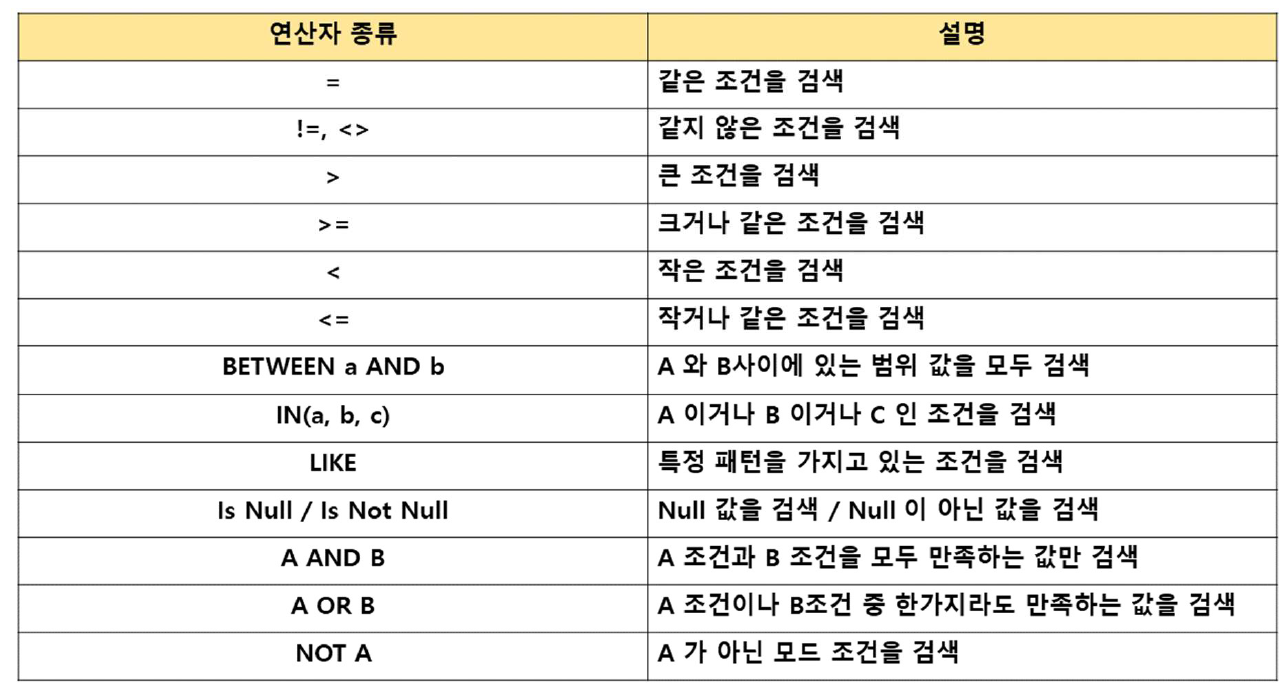
문법

주의사항
문자나 날짜 상수 표현 시 반드시 홀따옴표 사용(다른 절에서도 동일 적용)
ORACLE은 문자 상수의 경우 대소문자를 구분
MSSQL은 기본적으로 문자상수의 대소문자를 구분하지 X
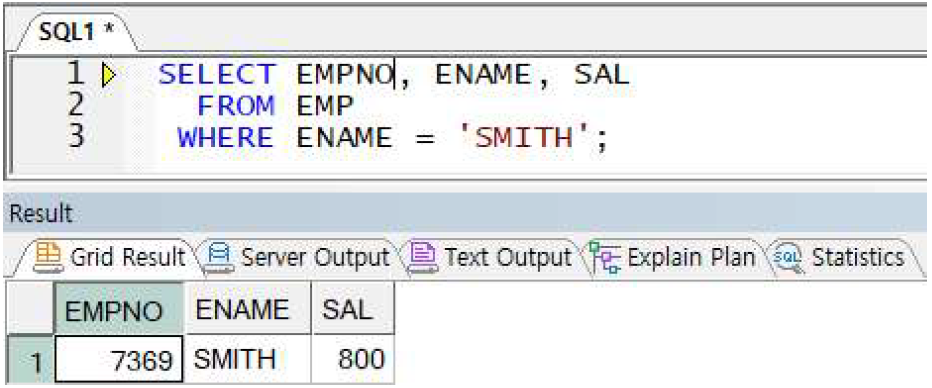
예제) 이름이 SMITH인 직원 조회(조건절에 문자 상수 사용)
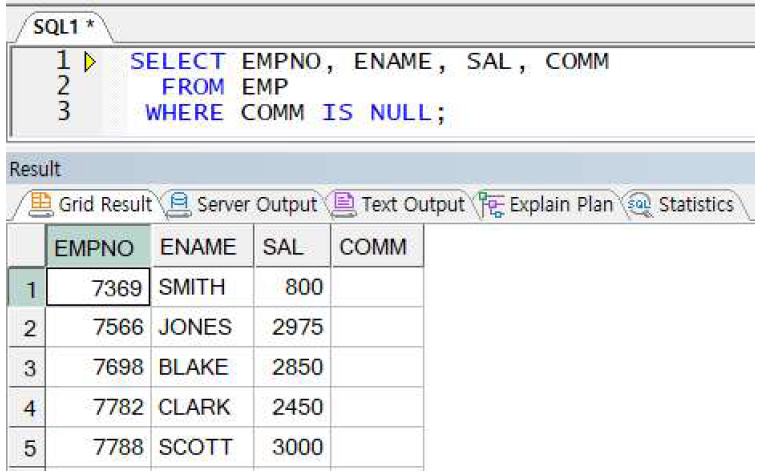
예제) COMM 값이 NULL인 직원 정보 출력
예제) 여러 조건 전달 - AND 연산자의 사용
DEPTNO가 10번이면서 SAL이 2000 이상인 직원 출력
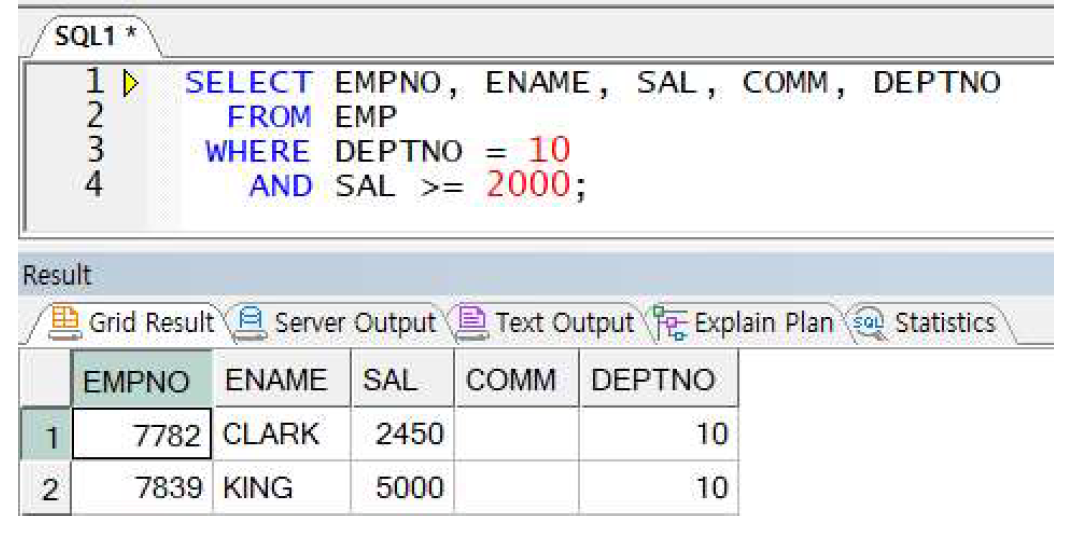
-> 두 조건이 모두 만족하는 대상을 찾을 경우 AND 연산자 사용
예제) 여러 조건 전달 - OR 연산자의 사용
DEPTNO가 10번이거나 SAL이 2000이상인 직원 정보 출력
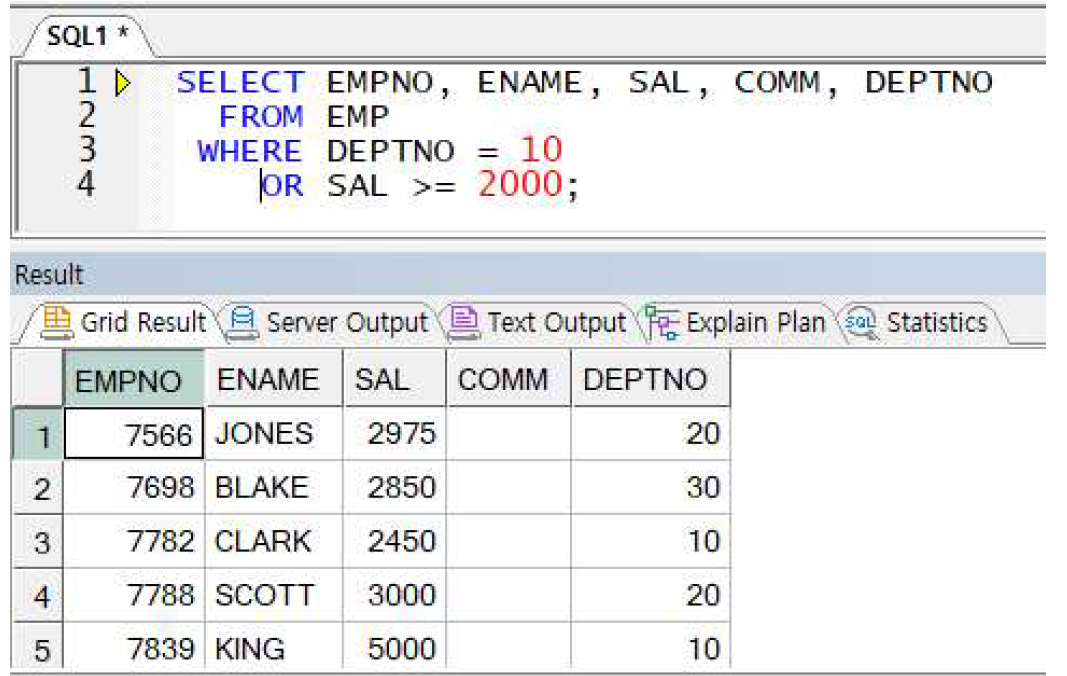
-> 위와 똑같은 조건이지만 두 조건을 연결하는 논리연산자를 AND(모두 만족)로 사용할 때와 결과가 다름. OR는 두 조건 중 하나만 성립해도 되는, 두 조건 결과의 합집합을 출력하는 논리연산자임.
IN 연산자
포함연산자로 여러 상수와 일치하는 조건 전달 시 사용
상수를 괄호로 묶어서 동시에 전달 (문자와 날짜 상수의 경우 반드시 홀따옴표와 함께)
예제) SMITH와 SCOTT의 직원 정보 출력
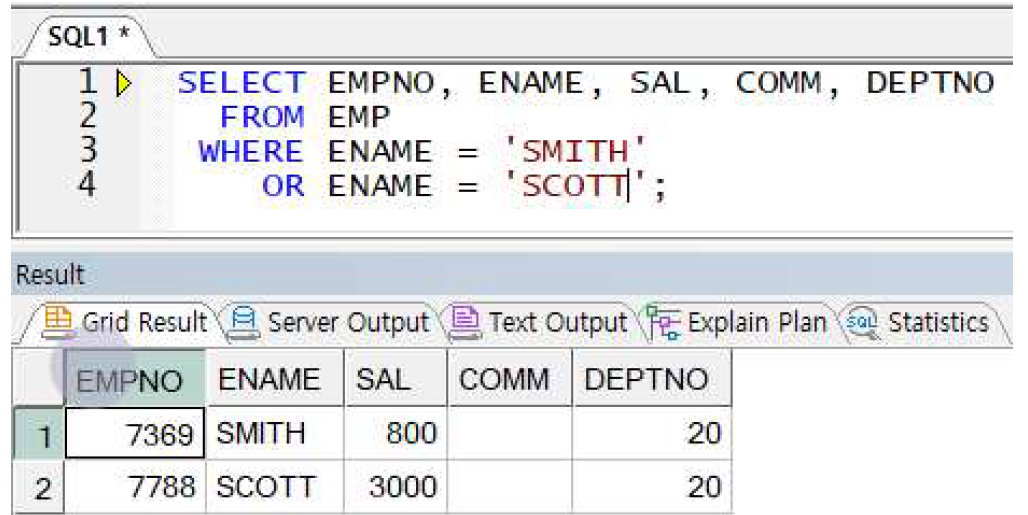
-> 이름이 SMITH 이면서 SCOTT일 수는 없으므로 두 조건을 각각 만족하는 합집합을 구하라는 의미임. 하지만 동일한 조건대상(ENAME)이 계속 반복돼야 하는 불편함이 있음 -> IN 연산자 사용
예제) IN 연산자로 변경
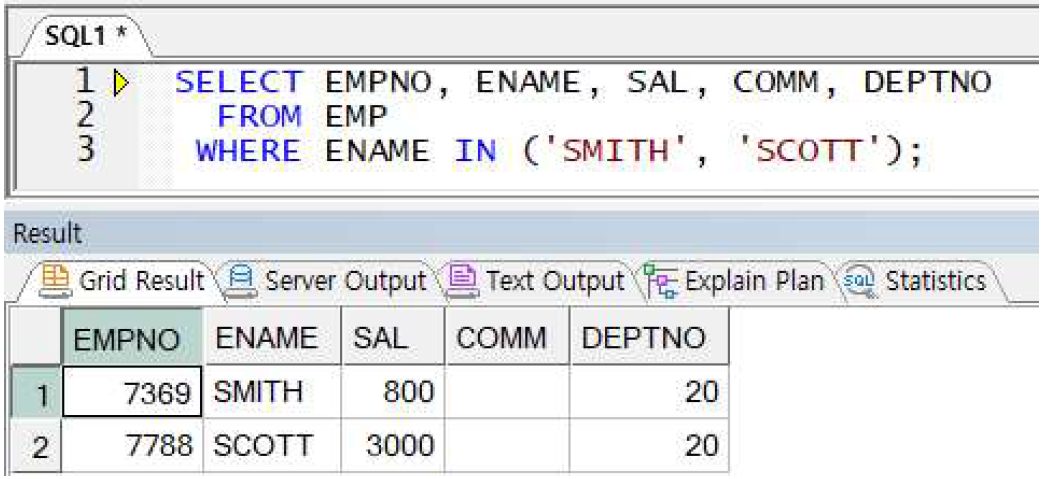
-> IN 연산자를 사용하면 조건대상(ENAME)과 연산자(=)의 반복을 줄일 수 있음. 이 때, ()안의 상수도 문자상수와 날짜상수는 홀따옴표 필수
BETWEEN A AND B 연산자
A보다는 크거나 같고 B도 작거나 같은 조건을 만족
A와 B에는 범위로 묶을 상수값 전달 (문자,숫자,날짜 모두 전달 가능)
반드시 A가 B도 작아야 함 (반대로 작성 시 아무것도 출력되지 X)
예제) SAL이 2000이상 3000이하인 직원 정보 출력
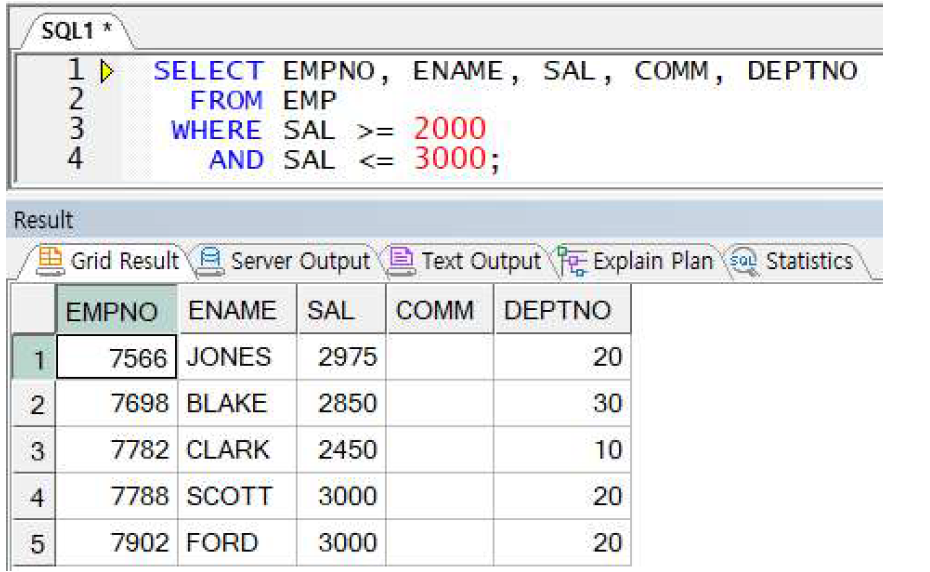
-> 역시 SAL이 반복되는 특징을 보임 -> BETWEEN A AND B 연산자 사용
예제) BETWEEN 연산자 사용
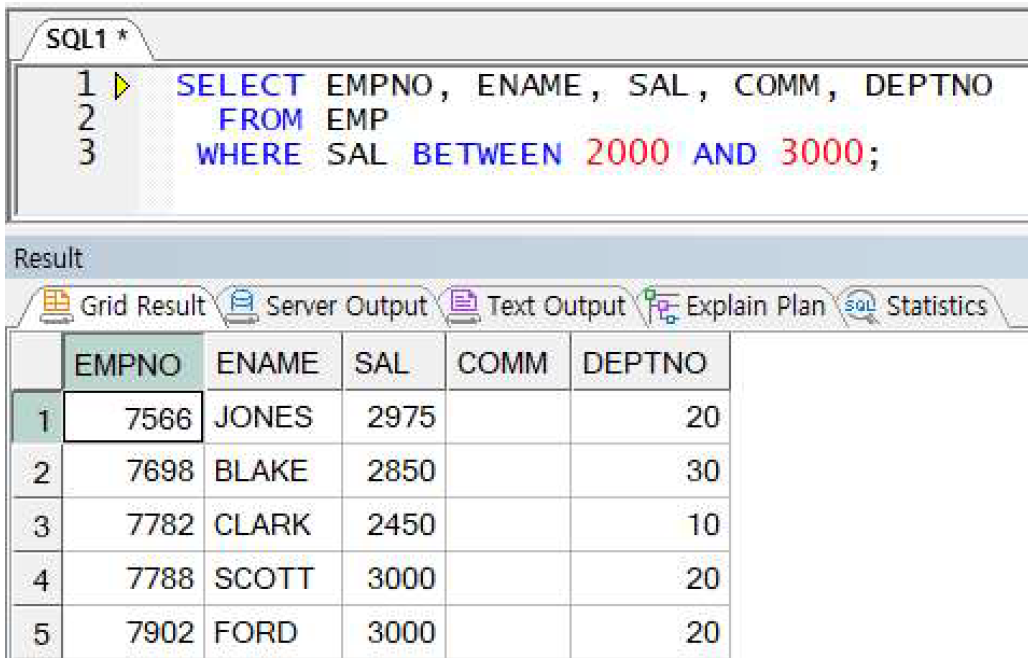
-> BETWEEN 연산자를 사용하면 SAL에 대한 반복을 할 필요 없음
예제) BETWEEN 연산자 주의사항
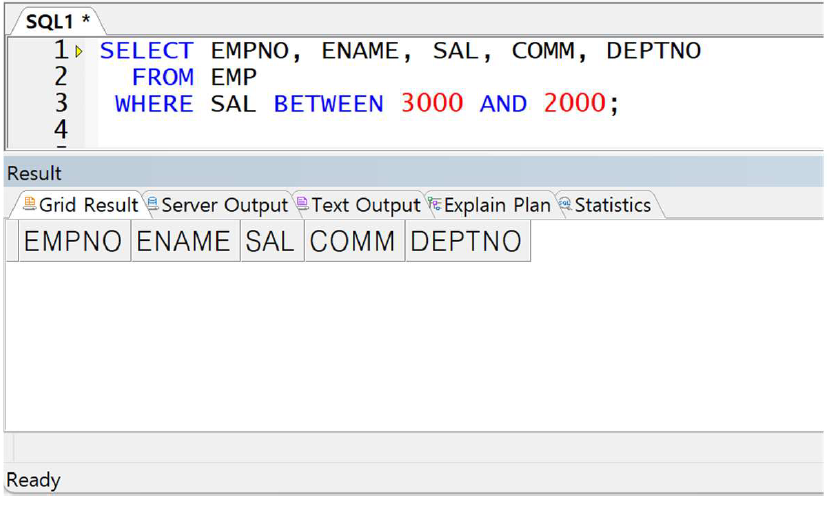
-> BETWEEN A AND B에서 A가 B보다 더 큰 값일 경우 아무것도 조회되지 않음
LIKE 연산자
ENAME LIKE 'S%' : 이름이 S로 시작하는
ENAME LIKE '%S%' : 이름에 S를 포함하는
ENAME LIKE '%S' : 이름이 S로 끝나는
ENAME LIKE '_S%' : 이름의 두 번째 글자가 S인
(맨 앞이 _인것 주의! %이면 자리수 상관없이 S를 포함하기만 하면 됨)
ENAME LIKE '__S__' : 이름의 가운데 글자가 S이며 이름의 길이가 5글자인
NOT 연산자
조건 결과의 반대집합. 즉, 여집합을 출력하는 연산자
NOT 뒤에 어는 연산 결과의 반대 집합 출력
주로 NOT IN, NOT BETWEEN A AND B, NOT LIKE, NOT NULL로 사용
예제) NOT 연산자의 사용
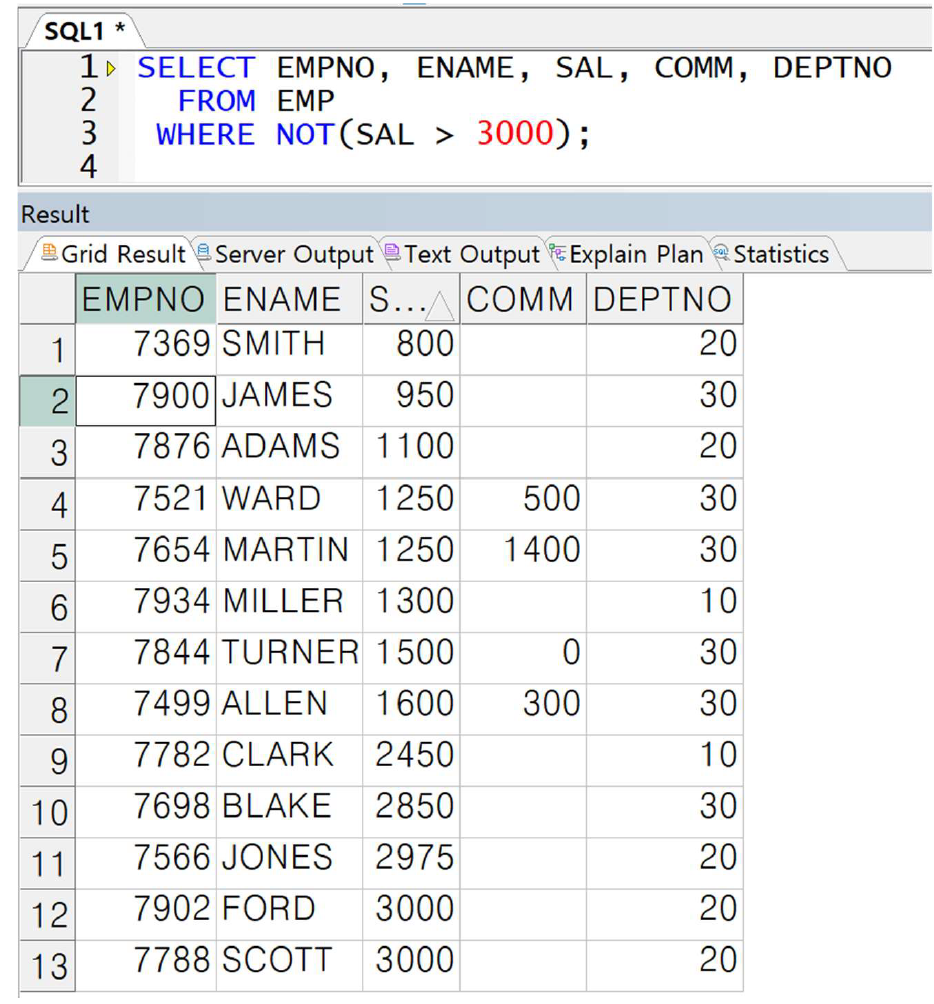
-> 이 경우 "3000보다 작거나 같은" 조건으로 변경 가능하므로 위처럼 NOT을 사용하지 않는다
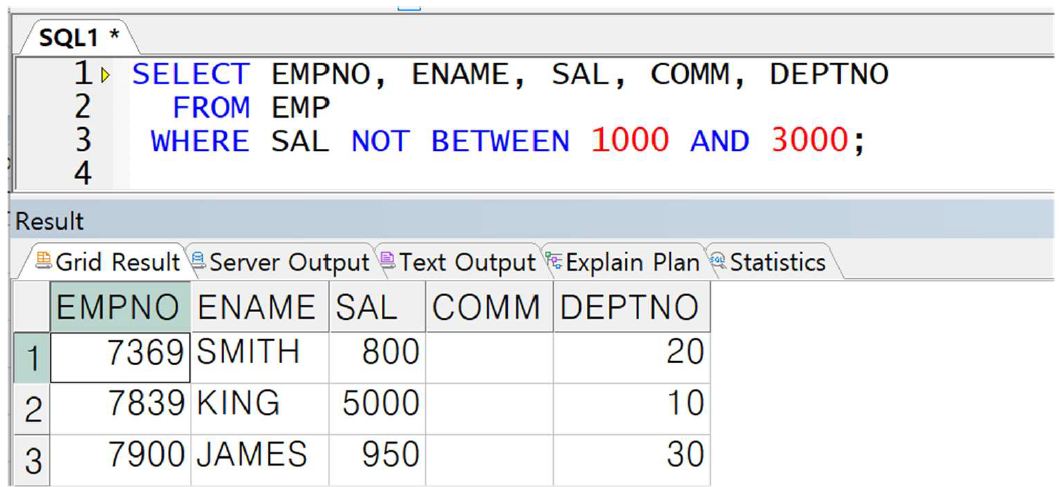
-> 1000 이상 3000 이하의 반대 집합 -> 1000 미만 또는 3000 초과
참조
해당 글은 홍쌤의 데이터랩의 영상강의를 기반으로 작성되었습니다.

