C
자료구조 - 연결 리스트
크기가 3인 연결 리스트는 각 인덱스의 메모리 주소에서 자신의 값과 함께 바로 다음 값의 주소(포인터)를 저장합니다.

마지막의 NULL은 Null pointer로(0x00000000,'값이 없다', '비어있다'를 의미), 메모리 주소 0을 가르키는 pointer 이다. \0의 NUL과는 다르다.
연결 리스트는 아래 코드와 같이 간단한 구조체로 정의할 수 있습니다.
typedef struct node
{
int number;
struct node *next;
}
node;node 라는 이름의 구조체는 number 와 *next 두 개의 필드가 함께 정의되어 있습니다.
number는 각 node가 가지는 값, *next 는 다음 node를 가리키는 포인터가 됩니다.
typedef struct node 에서 ‘node’를 함께 명시해 주는 것은, 구조체 안에서 node를 사용하기 위함이다. 또한 이때의 'node'는 이 구조체의 정식명칭이 되는 것이고 맨 밑의 'node'는 이 구조체의 별칭이다.
구조체, 포인터 관련 https://dojang.io/mod/page/view.php?id=418 참고
#include <stdio.h>
#include <stdlib.h>
//연결 리스트의 기본 단위가 되는 node 구조체를 정의합니다.
typedef struct node
{
//node 안에서 정수형 값이 저장되는 변수를 name으로 지정합니다.
int number;
//다음 node의 주소를 가리키는 포인터를 *next로 지정합니다.
struct node *next;
}
node;
int main(void)
{
// list라는 이름의 node 포인터를 정의합니다. 연결 리스트의 가장 첫 번째 node를 가리킬 것입니다.
// 이 포인터는 현재 아무 것도 가리키고 있지 않기 때문에 NULL 로 초기화합니다.
node *list = NULL;
// 새로운 node를 위해 메모리를 할당하고 포인터 *n으로 가리킵니다.
node *n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
// n의 number 필드에 1의 값을 저장합니다. “n->number”는 “(*n).number”와 동일한 의미입니다.
// 즉, n이 가리키는 node의 number 필드를 의미하는 것입니다.
// 간단하게 화살표 표시 ‘->’로 쓸 수 있습니다. n의 number의 값을 1로 저장합니다.
n->number = 1;
// n 다음에 정의된 node가 없으므로 NULL로 초기화합니다.
n->next = NULL;
// 이제 첫번째 node를 정의했기 떄문에 list 포인터를 n 포인터로 바꿔 줍니다.
list = n;
// 이제 list에 다른 node를 더 연결하기 위해 n에 새로운 메모리를 다시 할당합니다.
n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
// n의 number와 next의 값을 각각 저장합니다.
n->number = 2;
n->next = NULL;
// list가 가리키는 것은 첫 번째 node입니다.
//이 node의 다음 node를 n 포인터로 지정합니다.
list->next = n;
// 다시 한 번 n 포인터에 새로운 메모리를 할당하고 number과 next의 값을 저장합니다.
n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
n->number = 3;
n->next = NULL;
// 현재 list는 첫번째 node를 가리키고, 이는 두번째 node와 연결되어 있습니다.
// 따라서 세 번째 node를 더 연결하기 위해 첫 번째 node (list)의
// 다음 node(list->next)의 다음 node(list->next->next)를 n 포인터로 지정합니다.
list->next->next = n;
// 이제 list에 연결된 node를 처음부터 방문하면서 각 number 값을 출력합니다.
// 마지막 node의 next에는 NULL이 저장되어 있을 것이기 때문에 이 것이 for 루프의 종료 조건이 됩니다.
for (node *tmp = list; tmp != NULL; tmp = tmp->next)
{
printf("%i\n", tmp->number);
}
// 메모리를 해제해주기 위해 list에 연결된 node들을 처음부터 방문하면서 free 해줍니다.
while (list != NULL)
{
node *tmp = list->next;
free(list);
list = tmp;
}
}위의 내용은 반복해서 다시보자....
list->next = n; 는
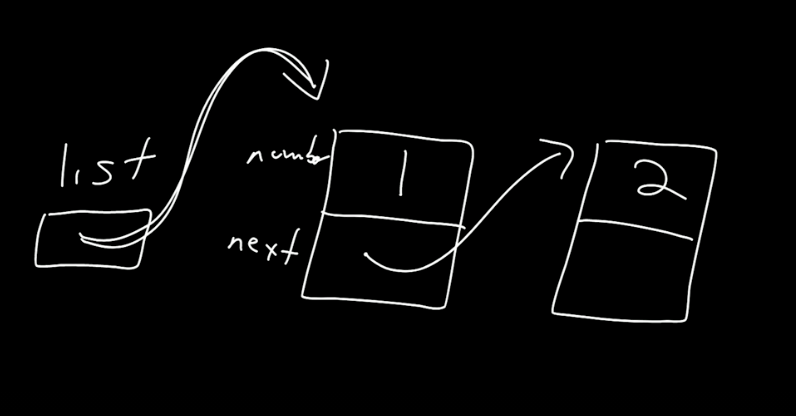
list->next->next = n; 는 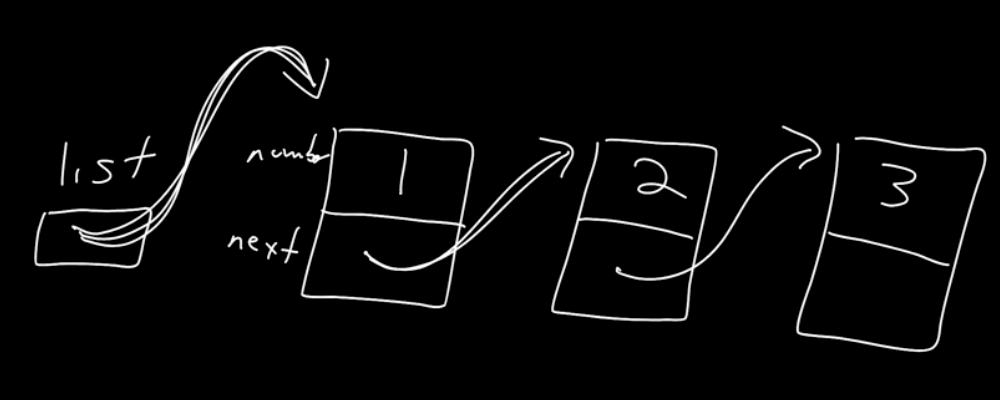
와 같은 그림으로 이해해보자.
배열과 비교해서 연결 리스트는 새로운 값을 추가할 때 다시 메모리를 할당하지 않아도 된다는 장점이 있습니다.
하지만 이런 유동적인 구조는 그 대가가 따릅니다. 구조가 정적인 배열과 달리 연결 리스트에서는 임의 접근이 불가능합니다.
트리는 연결리스트를 기반으로 한 새로운 데이터 구조이다.
연결리스트에서의 각 노드 (연결 리스트 내의 한 요소를 지칭)들의 연결이 1차원적으로 구성되어 있다면, 트리에서의 노드들의 연결은 2차원적으로 구성된다.
각 노드는 일정한 층에 속하고, 다음 층의 노드들을 가리키는 포인터를 가짐.
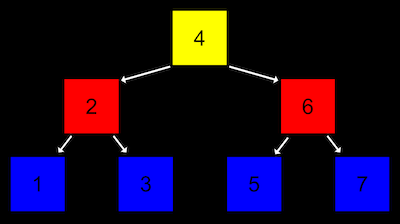
가장 높은 층에서 트리가 시작되는 노드를 ‘루트’, 루트 노드는 다음 층의 노드들을 가리키고 있고, 이를 ‘자식 노드’라고 한다.
위 그림에 묘사된 트리는 구체적으로 ‘이진 검색 트리’이다.
먼저 하나의 노드는 두 개의 자식 노드를 가집니다.
또 왼쪽 자식 노드는 자신의 값 보다 작고, 오른쪽 자식 노드는 자신의 값보다 크다.
따라서 이런 트리 구조는 이진 검색을 수행하는데 유리하다.
하지만 트리의 균형이 잡혀 있지 않으면 검색 시간이 늘어나고 더 많은 메모리를 소요한다는 단점이 있다.
