Knowlege Tracing은 학생의 문제 풀이 기록을 바탕으로 새로운 문제에 대한 정오를 예측하는 방법이다. DKT(Deep Knowledge Tracing) 등장 이전까지는 문제의 특성을 파악하기 위해 문제마다 전문가가 'knowledge concept'을 태깅하고 이 정보를 통해 정오를 예측했다. DKT는 정오예측에 딥러닝을 이용한 첫 시도로 문제(question)와 문제에 대한 답(question answer)만으로도 기존의 방법론보다 높은 AUC를 보여주었다.
Data
,
- : 문제 번호(question tag)
- : 정오(answered correctly)
Model
- 시퀀스는 사전에 정의된 시퀀스 길이에 따라 splitting과 padding을 이용한 정제가 필요하다.
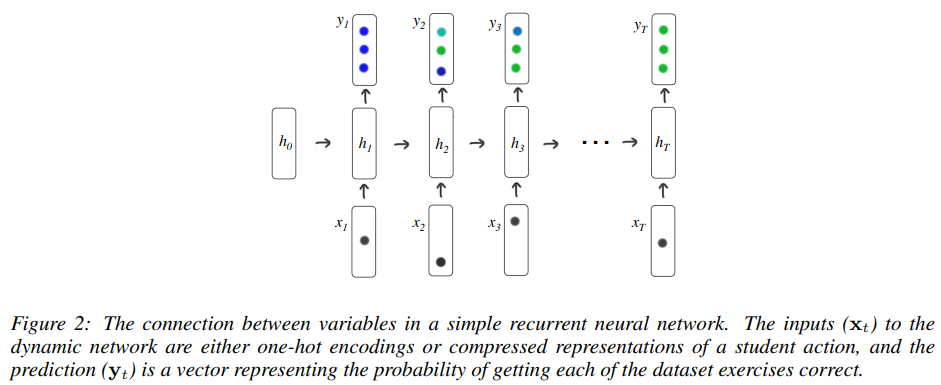
- 이후 RNN과 LSTM을 사용한여 정오를 예측한다. RNN의 경우는 아래 그림과 같다.
- 여기서 는 단일 문제에 대한 정답률이 아닌, 전체 문제에 대한 정답 확률로 loss를 계산하기 위해 해당 문항에 대해 masking을 해주어야 한다.
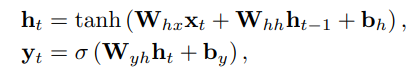
Result
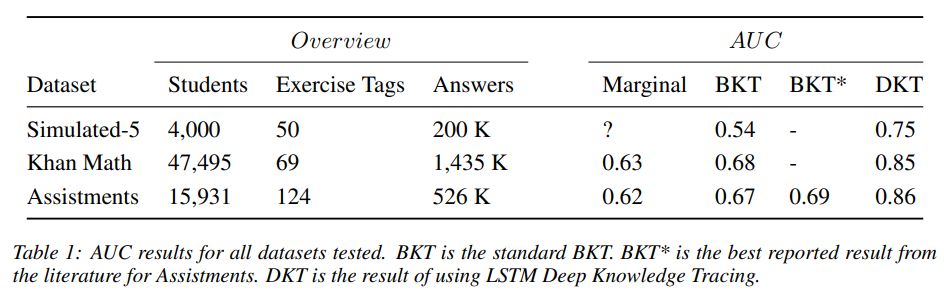
- 분석 결과를 통해 AUC가 상당히 많이 상승한 것을 확인할 수 있다.
Code
class DKT(nn.Module):
def __init__(self, num_q, emb_dim, hidden_dim):
super().__init__()
self.num_q = num_q
self.emb_dim = emb_dim
self.hidden_dim = hidden_dim
self.embedding = nn.Embedding(self.num_q*2, self.emb_dim)
self.lstm = nn.LSTM(
self.emb_dim, self.hidden_dim, batch_first=True
)
self.out = nn.Linear(self.hidden_dim, self.num_q)
self.dropout = nn.Dropout()
def forward(self, q, r):
x = q + self.num_q * r
h, _ = self.lstm(self.embedding(x))
y = self.out(h)
y = self.dropout(y)
y = torch.sigmoid(y)
return yDeep Knowledge Tracing
Knowledge Tracing Collection with PyTorch

까먹지 않기 위한 노트 (ว˙∇˙)ง