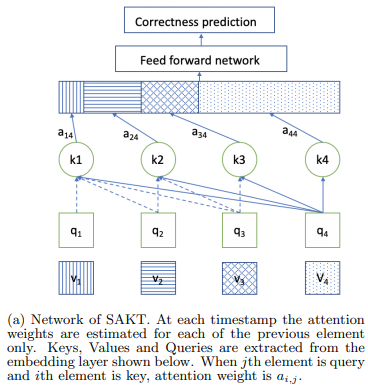
SAKT는 attention을 이용한 KT 모델로 정오 예측에서 과거 문제 풀이 기록에 가중치를 주어 예측한다. SAKT는 아래 그림에서 의 정오를 예측할 때, 연관된 knowledge concept을 가진 에 높은 attention score를 준다.

Data
- interaction
- : exercise tag
- : answer correctness
predict
Model
1. interaction 는 아래와 같이 계산된다. (embedding index를 겹치지 않게 하는 용도)
(여기서 는 전체 문제 수를 의미한다.)
2. splitting과 padding을 통해 지정된 시퀀스 길이 n으로 interaction 시퀀스의 길이를 맞춰준다.
3. embedding 후 positional embedding을 더해서 input을 생성한다.
- interaction embedding
- exercise embedding
- positional embedding
,
4. Transformer의 encoder + masking을 통해 예측한다.
은 query로, 은 key와 value로 사용된다. Transformer의 encoder에서는 masking이 사용되지 않았지만, 학생이 문제를 푼 순서와 정보를 반영하기 위해 SAKT에서는 masking을 사용한다.
A Self-Attentive model for Knowledge Tracing
Attention Is All You Need
Knowledge Tracing Collection with PyTorch

까먹지 않기 위한 노트 (ว˙∇˙)ง