Intro
FM(Factorization Machine)은 Support Vector Machine과 Factorization 아이디어를 합친 모델로 과거 회귀 모형(regression)이나 SVM이 좋은 성능을 내지 못하던 매우 스파스(sparse)한 고차원(high_dimensional) 데이터에서 준수한 성능을 내는 모델이다.
Data
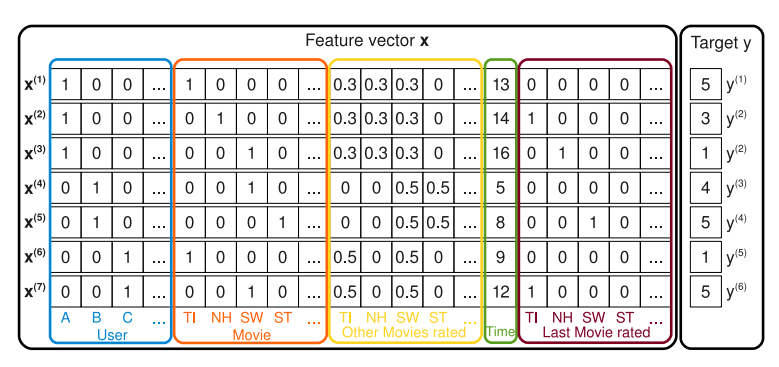
연속형, 범주형 등 다양한 타입의 데이터를 사용할 수 있다. Target y의 타입에 따라 회귀(regression)와 분류(classification) 문제를 모두 수행할 수 있지만, CTR을 중점적으로 다루기 때문에 분류 문제만 생각한다. CTR에서는 보통 OHE(One-Hot Encoding)을 수행한 이후 {0, 1}, 이진(binary) 값을 갖는 열을 변수(feature)라 부르고, 해당 변수의 그룹을 필드(field)라고 한다. 아래 그림에서 [User, Movie, ...]는 field, [A, B, C, TI, NH, ...]는 feature이다.
Model

두 변수의 관계만 고려한 d=2 모델의 수식은 위 그림과 같다.
- (1)에서 는 bias를, 는 각 feature의 weight를 의미한다.
- 는 각 feature의 잠재 벡터(latent vector)로 {0, 1}의 값을 갖는 feature와 달리 빽빽한 벡터(dense vector)이다.
- 두 변수의 관계(interaction)는 latent vector 의 내적으로 정의된다.
Note
- FM은 아래와 같이 식 변형을 이용하여 연산 속도를 감소시켰다.
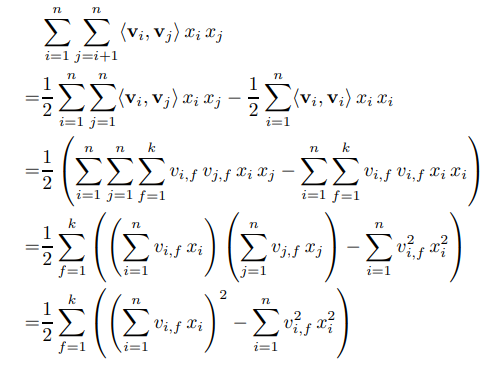
FFM(Field-aware FM)에서 다루는 내용이지만 FM은 field를 구분하여 학습하지 않는다. 다시 말해, field를 상관하지 않고 모든 feature의 interaction을 계산한다.- 모든 feature의 interaction을 계산하기 때문에 연산속도가 빠름에도(linear complexity), 고차원 데이터에서는 2차 이상의 interaction을 갖는 모델은 사용하기 어렵다.
Code
※ CTR 시리즈의 모든 코드는
FuxiCTR을 참고했으며 함수 구조와 이름 등은 개인적으로 수정하여 사용하였다.
-
feature_dict은 각 변수의 설명이 들어있는 dict()이다. (ex, Dict[str, Dict[str, int]])EmbeddingDict()은 각 필드(field)의 임베딩 벡터(embedding vector)를 반환하는ModuleDict()으로 아웃풋은 [배치(batch) 크기, 필드 수, 임베딩 크기] 형태이다. -
FM클래스의 경우 임베딩 값을 FMLayer()에 넣는 구조로 되어있는데, FM 자체가 다른 모델들에서 사용되는 경우가 많기 때문에 FMLayer()를 따로 정의한 것이다.
class FM(BaseModel):
def __init__(self, feature_dict):
super(FM, self).__init__()
self.embedding = EmbeddingDict(feature_dict=feature_dict)
self.fm_layer = FMLayer(feature_dict=feature_dict)
# training method
# self.compile(CFG.optimizer, CFG.loss, CFG.learning_rate)
# self.init_params()
# self.model_to_device()
def forward(self, inputs):
X, y = self.inputs_to_device(inputs)
X_emb = self.embedding(X)
y_pred = self.fm_layer(X, X_emb)
return {"y_true": y, "y_pred": y_pred} FMLayer는 LR(Logistic Regression)과 InnerProduct로 구성되어 있다.LR은 를,innerProdcut는 를 계산한다.
class FMLayer(nn.Module):
def __init__(self, feature_dict):
super(FMLayer, self).__init__()
self.lr = LR(feature_dict=feature_dict)
self.inner_product = InnerProduct(model='FM', feature_dict=feature_dict)
def forward(self, X, X_emb):
return self.lr(X) + self.inner_product(X_emb)EmbeddingDict()은 임베딩 벡터를 반환하는 클래스이다.LR에서는 임베딩 크기를 1로 설정하여 바로 weight로 사용한였다.
class LR(nn.Module):
def __init__(self, feature_dict, use_bias=True):
super(LR, self).__init__()
self.bias = nn.Parameter(torch.zeros(1), requires_grad=True) if use_bias else None
self.embedding = EmbeddingDict(feature_dict=feature_dict, embed_dim=1)
def forward(self, X):
lr_out = self.embedding(X).sum(dim=1)
if self.bias is not None:
lr_out += self.bias
return lr_outInnerProduct에서는 위의 Note.1의 변형된 식을 계산한다.X_embed는 임베딩 행렬로 각 행은 feature의 임베딩 벡터를 나타낸다. (latent vector로 생각하면 된다.)
class InnerProduct(nn.Module):
def __init__(self, feature_dict, model='FM', X_dim=None, device=CFG.device):
super(InnerProduct, self).__init__()
self._model = model
self._num_fields = len(feature_dict)
self._num_interactions = int(self._num_fields * (self._num_fields - 1) / 2)
def forward(self, X_emb):
if self._model == 'FM':
sum_of_square = X_emb.sum(dim=1) ** 2
square_of_sum = torch.sum(X_emb ** 2, dim=1)
fm_out = (sum_of_square - square_of_sum) * 0.5
return fm_out.sum(dim=-1, keepdim=True)
