Intro
FFM은 FM에 필드(field)의 개념을 접목시킨 모델이다. 필드에 대한 설명은 앞의 FM에서 확인할 수 있다.
Model
FM은 아래 식과 같이 변수(feature)의 field를 고려하지 않고 모든 관계(interaction)를 계산한다.

그러나 모든 feature는 특정 field 그룹에 속해있고 각 그룹의 특성은 다르기 때문에, field를 고려하여 변수의 관계(interaction)를 구성하는 것이 합리적이다. 따라서 FFM은 잠재 벡터(latent vector) 에 field 정보를 주어 interaction을 계산한다. FFM 식은 아래 그림과 같으며, 의 첨자가 field, 가 feature를 나타낸다.
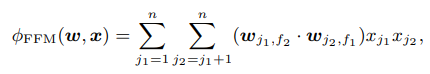
문제는 field별로 feature를 고려하다보니 학습해야 할 파라미터(parameter)의 수가 크게 증가한다는 점이다. 총 파라미터의 수는 (#features) X (#fields) X (latent vector size)로 FM에 비해 만큼 늘어난다.

그러나 field별로 feature를 학습시키기 때문에 FM보다 를 작게 설정할 수 있어 어느정도 보완하여 사용가능하다.()
Code
※ CTR 시리즈의 모든 코드는
FuxiCTR을 참고했으며 함수 구조와 이름 등은 개인적으로 수정하여 사용하였다.
-
feature_dict은 각 변수의 설명이 들어있는 dict()이다. (ex, Dict[str, Dict[str, int]])EmbeddingDict()은 각 필드의 임베딩 벡터(embedding vector)를 반환하는ModuleDict()으로 아웃풋은 [배치(batch) 크기, 필드 수, 임베딩 크기] 형태이다. -
FFM 코드의 핵심은
field_aware_interaction메서드이다. 해당 메서드는 필드별 임베딩 행렬을 (field-1)개 만큼 확장시킨embedding_list로 feature interaction을 계산하여 field를 고려한 효과를 낸다.
class FFM(BaseModel):
def __init__(self, feature_dict, embed_dim=CFG.embed_dim):
super(FFM, self).__init__()
self._num_fields = len(feature_dict)
self.lr = LR(feature_dict=feature_dict)
self.embedding_list = nn.ModuleList([
EmbeddingDict(feature_dict=feature_dict) for _ in range(self._num_fields-1)
])
# training method
# self.compile(CFG.optimizer, CFG.loss, CFG.learning_rate)
# self.init_params()
# self.model_to_device()
def forward(self, inputs):
X, y = self.inputs_to_device(inputs)
field_aware_emb_list = [emb(X) for emb in self.embedding_list]
ffm_out = self.field_aware_interaction(field_aware_emb_list)
lr_out = self.lr(X)
y_pred = lr_out + ffm_out
return {'y_true': y, 'y_pred': y_pred}
def field_aware_interaction(self, field_aware_emb_list):
dot = 0
for i in range(self._num_fields-1):
for j in range(i + 1, self._num_fields):
v_ij = field_aware_emb_list[j-1][:, i, :]
v_ji = field_aware_emb_list[i][:, j, :]
dot += torch.sum(v_ij * v_ji, dim=1, keepdim=True)
return dotField-aware Factorization Machines for CTR Prediction
FuxiCTR Github
