-
지금 tabular 데이터를 다루고 있기도 하고, 얼마전에 tabnet을 돌렸을 때 accuracy가 lightgbm에 비해 낮게 나오던 차에 이 논문을 발견했다. 사실 제목이 재밌어서 읽었다. (이제 알았는데 Transformer를 오마주한 논문 제목이 꽤 있다.)
-
내용은 간단하다. tabular data를 다루는 deep learning model들이 boosting보다 결과가 좋다고 하는데 그건 결과가 좋게 나오는 데이터를 쓰기 때문이라는 것이다.
(근데 나라도 그럴ㄱ...) -
저자는 4개의 DL model이 사용했던 데이터와 추가적인 데이터의 결과를 통해 이를 보여준다.
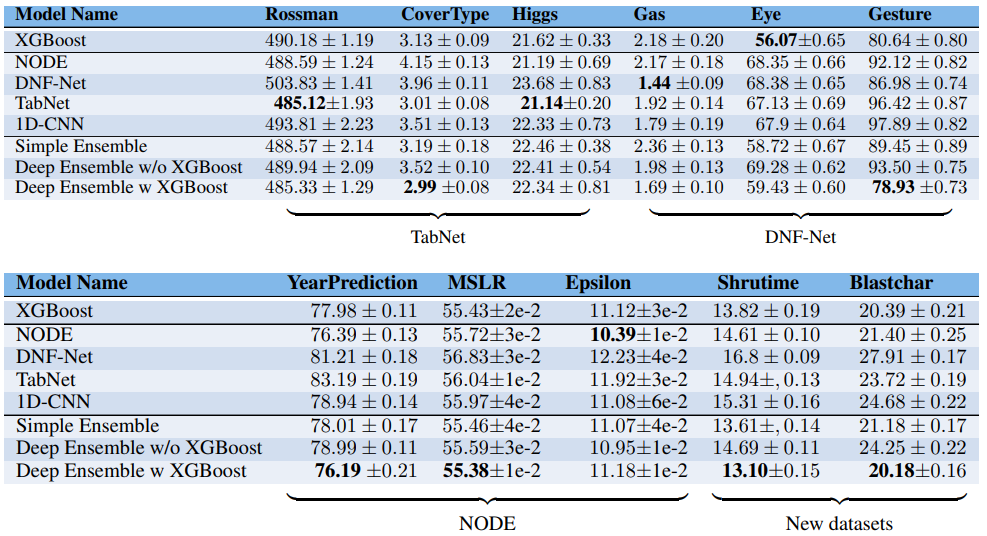
-
'There is no free lunch' 모든 데이터에서 최선의 결과를 내는 model은 존재하지 않으니 열심히 일하자.
-
그러나 모든 모델을 돌려 비교하는 것은 사실상 어렵기때문에 (1) Boosting을 하거나 (2) Ensemble을 하는 것이 괜찮은 선택지가 될 수 있다.
-
저자는 Average Relative Performance(%)를 계산했는데 이는 데이터마다 최적의 모델이 낸 결과값과 각 모델의 차이를 구해 평균 낸 값이다. 아래 그림을 통해 xgboost가 다른 모델에 비해 차이가 작은 것을 확인할 수 있다. (ensemble 제외)
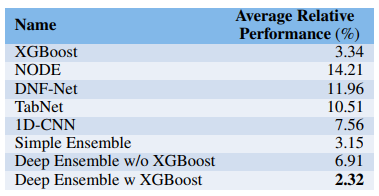
- 저자는 boosting을 포함한 여러 모델의 ensemble을 제안한다. 주어진 시간이 허락한다면 ensemble은 대부분의 경우 좋은 선택지이다.

까먹지 않기 위한 노트 (ว˙∇˙)ง