Intro
이미지와 텍스트 등 비정형 데이터 분야에서는 DL 모델이 기존의 KNN, PCA, Naive Bayes등 ML 모델의 성능을 크게 뛰어넘었다. 그러나 정형 데이터(tabular data)에서는 여전히 Random Forest, Boosting과 같은 트리 기반 모델(Tree-based model)이 DL 모델들에 비해 우수한 성능을 보이고 있다.
해당 논문에서는 다양한 기준을 통해 선별한 45개의 데이터셋으로 트리 기반 모델(이하 tree로 지칭)이 DL 모델(이하 nn으로 지칭)에 비해 여전히 준수한 성능을 내는 모습을 보여준다. 또한 어떤 inductive bias로 인해 tree 모델이 nn보다 좋은 성능을 내는지 알아보기 위해 다양한 bias 조건을 비교하며 연구를 진행한다. 논문의 데이터 분석 결과는 제외하고 Findings에 대해서만 정리한다.
여기서 bias는 Bias-Variance trade off의 bias가 아니라 '모델이 데이터를 잘 학습하기 위해 가지고 있는 가정'정도로 생각하면 된다. (예를 들어, CNN은 Locality란 bias를 가지고 있어 Spatial translation에 invariant하고 이미지를 학습할 때 이점을 가진다.)
Findings
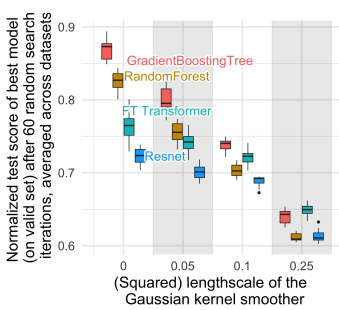
Finding 1. NNs are biased to overly smooth solutions
Finding 1을 실험하기 위해 gaussian kernel을 이용한 target smoothing을 수행한다. (smoothing은 model이 target function의 irregular한 패턴을 학습하는 것을 완화시킨다.) 아래 그림에서 length-scale이 커짐에 따라(target function이 더 smooth해짐에 따라) tree와 nn 모델의 score 격차가 줄어드는 것을 확인할 수 있다. 이를 통해 nn은 smooth한 패턴을 학습하는데 편향되어 있음을 알 수 있다.
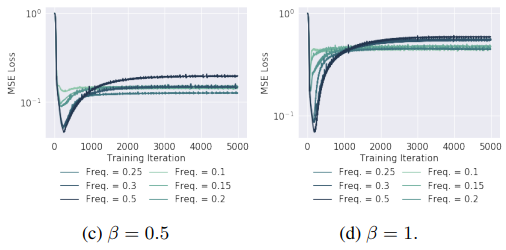
nn은 iteration이 증가함에 따라 target function의 irregular한 패턴도 학습하지만, 이에 앞서 low-freq(low-frequency) noise signal을 먼저 학습한다. (Low frequence는 local 하게 튀지 않는 global한 패턴을 의미한며, 아래 그림에서 iteration이 적을 때의 초록 선과 같은 패턴을 나타낸다.)

Noise의 진폭(amplitude) 와 빈도(frequency) 에 대해 아래 그림을 통해 nn은 먼저 low-freq. noise signal을 학습하는 것 다시 한 번 확인할 수 있다.
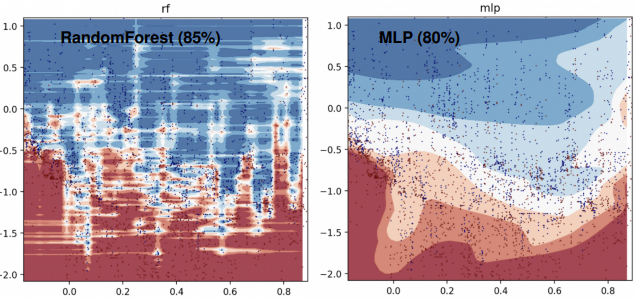
데이터의 decision boundary를 보면 tree는 격자로 데이터를 학습하기 때문에 아래 그림처럼 가로 패턴이 눈에 띄면서 irregular pattern들을 잘 학습하는 모습을 보여준다. 반면 nn은 activation function과 layer를 통해 highly-nonlinear pattern을 학습하여 smooth한 경계선이 나타나는 모습을 확인할 수 있다. (그림에서 x, y 축은 데이터의 변수, 검은 글씨는 test acc.를 의미한다,)
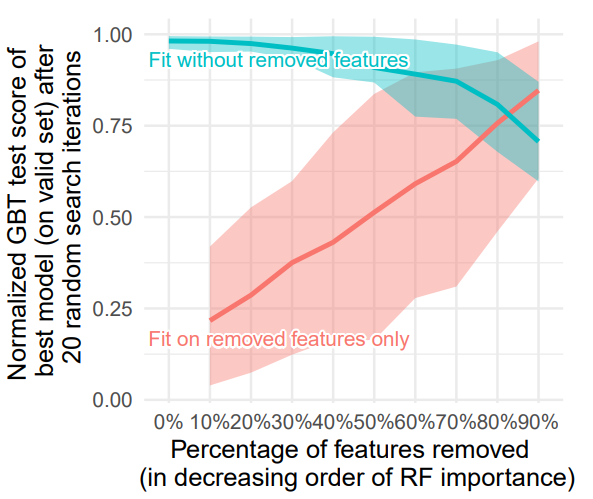
Finding 2. Uninformative features affect more MLP-like NNs
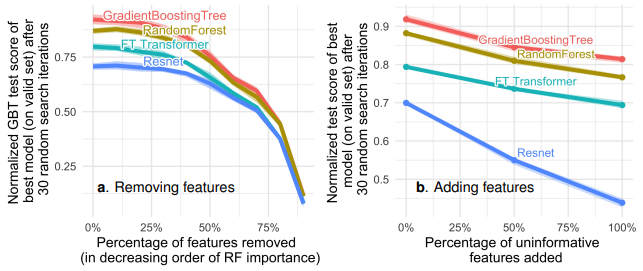
Tabular dataset은 uninformative feature를 포함하는 경우가 많다. 아래 그림의 하늘색 선을 통해 전체 feature중 약 절반(50%)를 제외하고 예측 모델을 생성하더라도 test score가 크게 변하지 크게 떨어지지 않는 모습을 확인할 수 있다.
Uninformative feature들을 feature importance에 따라 제거하는 비율을 늘려보면 tree와 nn 모델의 성능 간격이 조금씩 줄어든다(a). 반면 uninformative feature를 추가하는 비율을 늘리면 성능 차이가 크게 벌어지는 모습을 보인다(b). 이를 통해 nn이 uninformative feature에 robust하지 않음을 알 수 있다.
Finding 3. Data are non invariant by rotation, so should be learning procedure
nn은 tree에 비해 더 Rotationally Invariant(RI)하다. 해당 가설은 데이터를 matrix rotation하여 실험한다. 아래 그림에서 RestNet은 No Rotation/Rotation 상관없이 성능이 일정한 결과를 보이며, Rotation으로 모델의 성능이 반전되는 현상 또한 확인할 수 있다.
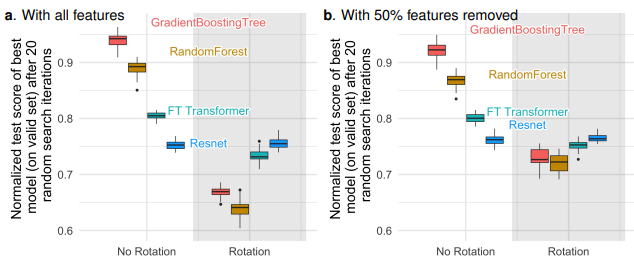
Tabular data는 각 열(feature)마다 다른 특성을 가지고 있는데 RI 모델은 이러한 데이터의 성질을 제대로 반영하지 못한다. 모델에 Embedidng layer를 추가하여이와같은 RI의 영향을 제어할 수 있다.
Why do tree-based models still outperform deep
learning on tabular data?
On the Spectral Bias of Neural Networks
Feature selection, L1 vs. L2 regularization,
and rotational invariance
