Intro
CTR 예측 모델에서 변수(feature)를 다루는 것은 관측된 변수의 관계(ex, co-occurence)들을 통해(Memorization) 새로운 변수의 결합(feature combination)으로 확장시키는 것(Generalization)이다. Regression의 경우 과거 기록이 없는 경우, 다시말해 train data에 변수간의 관계(interaction)가 존재하지 않는 경우 두 변수의 관계를 일반화(generalization)할 수 없다. 반면 Embedding을 이용하는 방법은 두 변수의 관측된 관계가 없는 상황에서도 잠재 변수(latent vector)와 같은 dense embedding vector를 이용할 수 있는데, 이는 자칫하면 과대일반화(over-generalization)로 이어질 수 있다. Wide&Deep 모델은 위의 두 방법을 통해 상호 보완적인 관계의 모델을 제시한다.
Model
Wide&Deep 모델의 구조는 아래 그림과 같으며, Wide와 Deep에서 각각 결과 값(log odds)을 얻어 더한 후 sigmoid를 취하는 형태로 되어 있다.
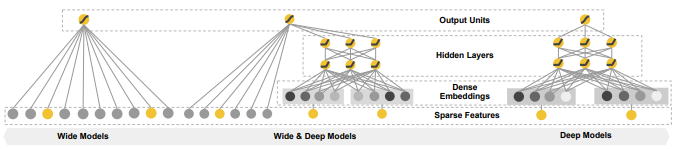
Wide
Wide는 단순한 회귀 모델(regression)이다. 여기서 는 단일 feature 뿐 아니라 다양한 변수를 포함한다. 변수 생성은 전문가들의 feature engineering을 필요로 하며, 변수의 관계(interaction)를 계산하는 cross-product transformation 식은 아래와 같다.

Deep
Deep은 임베딩값을 인풋(input)으로 받는 NN(Neural Network) 모델이다. 활성화 함수(activation function) 로는 ReLU를 사용한다.

Note
-
예측 모델 서빙(serving) 과정
- 모든 유저에 대해 모든 아이템의 선호 순서를 매기는 것은 매우 비효율적이기 때문에 쿼리(query)와 데이터베이스(database)의 정보를 이용하여 연관성이 있는 100개의 item만 추출한 후(Retrieval, candidate generation) 랭크(rank)를 매긴다.
- 유저의 반응(Logs)을 이용하여 모델을 지속적으로 보완한다.

-
구글 플레이(Google play)에서는 2개의 hidden layer를 갖는 MLP 모델을 Deep으로 사용했으며 구조는 다음 그림과 같다.
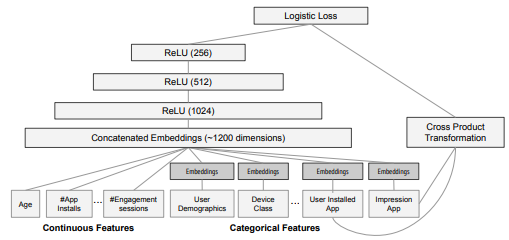
-
이 모델의 핵심은 Wide를 잘 설계하는 것이다. Deep은 wide, 즉 regression의 잔차(residual)를 학습하는 역할을 한다.
-
Wide를 잘 설계한다는 것은 결국 feature selection, feature extraction 등 다양한 feature engineering 방법을 통해 변수를 설계해야하는 일로 전문가 인력과 더불어 상당한 시간을 필요로 한다. 이 때문인지 DeepFM, xDeepFM, AutoInt 등의 이후 연구들은 처음부터 끝까지 모델만으로 학습 가능한 모델에 초점을 둔다.
Code
※ CTR 시리즈의 모든 코드는
FuxiCTR을 참고했으며 함수 구조와 이름 등은 개인적으로 수정하여 사용하였다.
-
feature_dict은 각 변수의 설명이 들어있는 dict()이다. (ex, Dict[str, Dict[str, int]])EmbeddingDict()은 각 필드의 임베딩 벡터(embedding vector)를 반환하는ModuleDict()으로 아웃풋은 [배치(batch) 크기, 필드 수, 임베딩 크기] 형태이다. -
WideDeep 모델은 LR과 DNN의 합으로 이루어져 있다. DNN의 경우 임베딩(embeding) 값을 인풋으로 받으며, 해당 코드에서는 모든 변수의 임베딩 크기를 같게 설정했다.
class WD(BaseModel):
def __init__(self, hidden_dim_list, feature_dict=feature_dict, embed_dim=CFG.embed_dim):
super(WD, self).__init__()
self._num_fields = len(feature_dict)
self.embedding = EmbeddingDict(feature_dict=feature_dict)
self.lr = LR(feature_dict=feature_dict)
self.dnn = DNNLayer(input_dim=embed_dim * self._num_fields,
hidden_dim_list=hidden_dim_list)
# training method
# self.compile(CFG.optimizer, CFG.loss, CFG.learning_rate)
# self.init_params()
# self.model_to_device()
def forward(self, inputs):
X, y = self.inputs_to_device(inputs)
X_embed = embedding(X)
lr_output = self.lr(X)
dnn_output = self.dnn(X_embed.flatten(start_dim=1))
y_pred = lr_output + dnn_output
return {"y_true": y, "y_pred": y_pred}DNN의 기본 구조는 간략히 아래같이 구성했으며, 다른 argument들을 고려하여 (activation function, dropout rate, BN 유무 등) 다양하게 구성할 수 있다.
class DNNLayer(nn.Module):
def __init__(self,
input_dim,
hidden_dim_list,
output_dim=1):
super(DNNLayer, self).__init__()
dlayers = []
hidden_dim_list = [input_dim] + hidden_dim_list
for idx in range(len(hidden_dim_list) - 1):
dlayers.append(nn.Linear(hidden_dim_list[idx], hidden_dim_list[idx+1], bias=True))
dlayers.append(nn.BatchNorm1d(hidden_dim_list[idx+1]))
dlayers.append(nn.ReLU())
dlayers.append(nn.Dropout(0.3))
dlayers.append(nn.Linear(hidden_dim_list[-1], output_dim, bias=True))
self.dnn = nn.Sequential(*dlayers)
def forward(self, inputs):
return self.dnn(inputs)LR을 앞의 FM 문서에 있어 생략한다.
