시계열
시계열 데이터 : 일정 시간 간격으로 배치된 데이터들의 열
시계열 분석 : 시간 순서대로 정렬된 데이터에서 의미 있느 요약과 통계정보를 추출
추세(Trend)
장기적으로 증가, 감소하는 경향성이 존재하는 것
시계열에서 기울기가 증가하거나 감소할 때 관찰 됨
일정 기간 동안 지속되는 변화(장기적 방향성)
확정적 추세 : 변동성이 존재하지 않는 추세임
확률적 추세 : 주가 처럼 변동성이 존재하는 추세

계절성 (Seasonality)
일정 기간 안에 반복적으로 나타나는 패턴
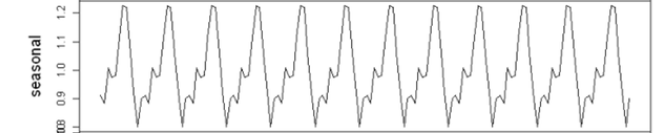
주기성 (Cycle)
정해지지 않은 빈도
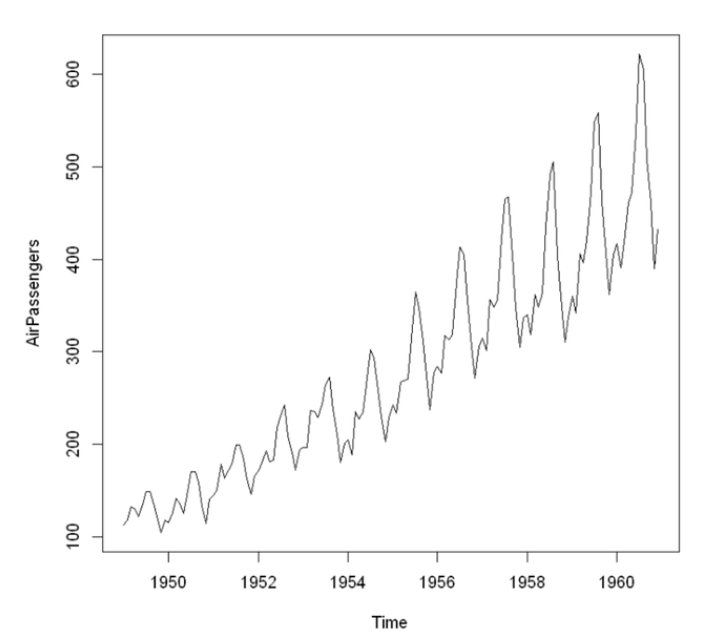
observed : Original Data
Trend : 확정적 추세을 뽑아서 시각화
Seasonal : 구간별로 12번씩 비슷한 모양으로 반복
random : 잔차(residual), trend - seasonal (더이상 뽑아낼 수 있는 시계열의 성질이 없음)
정상성
시간에 상관 없이 시계열이 일정한 성질을 가지고 있음
강정상성 : 모든 데이터가 시간에 상관이 없음
약정상성 : 시간에 따라 일정한 평균, 분산, 공분산을 갖는 확률 과정으로 정의
정상성 검증
KPSS 검증
귀무 가설 : 시계열 과정이 정상적이다.
대립 가설 : 시계열 과정이 비정상적이다.
# Kpss 불러오기
from statsmodels.tsa.stattools import kpss
# 시계열 테스트 데이터
time_series_data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# KPSS 검정 수행
kpss_outputs = kpss(time_series_data)
print('KPSS test 결과 : ')
print('--'*15)
print('KPSS Statistic:', kpss_outputs[0])
print('p-value:', kpss_outputs[1])
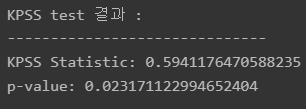
p-value가 0.05보다 작으므로 귀무가설 기각
ADF 검증
귀무 가설 : 시계열에 단위근이 존재함
대립 가설 : 시계열이 정상성을 만족함
# adfuller 불러오기
from statsmodels.tsa.stattools import adfuller
# 시계열 테스트 데이터
time_series_data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# ADF 검정 수행
adf_outputs = adfuller(time_series_data)
print('ADF Test 결과 : ')
print('--'*15)
print('ADF Statistic:', adf_outputs[0])
print('p-value:', adf_outputs[1])
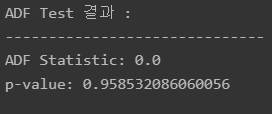
p-value가 0.05이상이므로 귀무가설 채택
중요!
확정적 추세가 존재하는 경우 검증 결과에 차이가 존재(안정성에 관한 여부를 평가하는 방식이 상이)
그래프를 그려 시각적으로 안정성을 띄는지 확인 필요
정상성 부여 방법
1. 로그 변환(분산을 일정하게)
2. 회귀 (평균을 일정하게) : 선형 회귀 모델을 사용하여 실제값과 예측값의 차이를 통해 평균을 조정
3. 평활 (평균을 일정하게) : 시계열 데이터의 잡음 제거 위함
4. 차분 (평균을 일정하게) : 시간에 따른 현재 데이터와 과거 데이터의 차이를 구함(여러번 수행 가능)
