tsfresh
시계열의 feature를 자동으로 추출하는 Library
각종 지표를 자동으로 추출함
사용 데이터 셋
from tsfresh.examples.robot_execution_failures import download_robot_execution_failures, load_robot_execution_failures
download_robot_execution_failures()
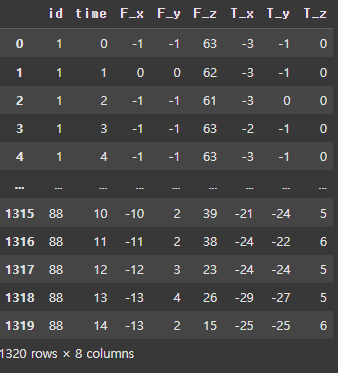
timeseries, y = load_robot_execution_failures()
timeseries
특징 추출
from tsfresh import extract_features
extracted_features = extract_features(timeseries, column_id="id", column_sort="time")
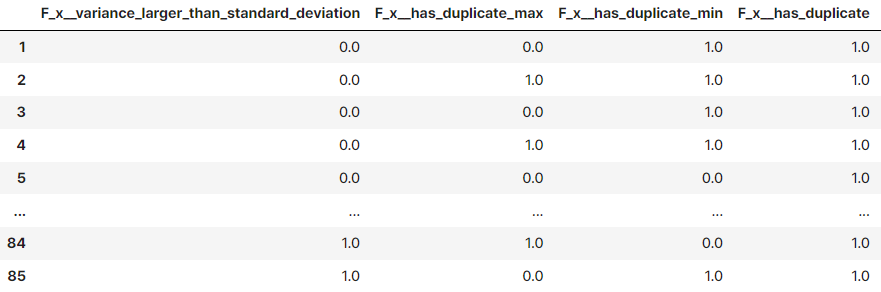
세부 특징 추출
특징이 추출된 데이터에서 모든 열의 중요성 확인 후 관련 특징 필터링
from tsfresh import select_features
from tsfresh.utilities.dataframe_functions import impute
# ⑥ impute
impute(extracted_features)
# ⑦ select_features(X, y)
features_filtered = select_features(extracted_features, y)

데이터셋 가공
Column 'ID'를 중심으로 나눠야 함
def custom_classification_split(x, y, test_size=0.3):
num_true = int(y.sum()*test_size)
num_false = int((len(y)-y.sum())*test_size)
id_list = y[y==False].head(num_false).index.to_list() + y[y==True].head(num_true).index.to_list()
y_train = y.drop(id_list)
y_test = y.iloc[id_list].sort_index()
X_train = x[~x['id'].isin(id_list)]
X_test = x[x['id'].isin(id_list)]
return X_train, y_train, X_test, y_test
X_train, y_train, X_test, y_test = custom_classification_split(timeseries, y)
MinimalFCParameters
feature를 최소로 하여 계산을 수행(데이터셋 크기가 큰 경우 minimal로 변경하여 테스트)
from tsfresh import extract_features
from tsfresh.feature_extraction import MinimalFCParameters
settings = MinimalFCParameters()
minimal_features_train = extract_features(
X_train,
column_id="id",
column_sort="time",
default_fc_parameters=settings
)
minimal_features_test = extract_features(
X_test,
column_id="id",
column_sort="time",
default_fc_parameters=settings
)
minimal_features_train
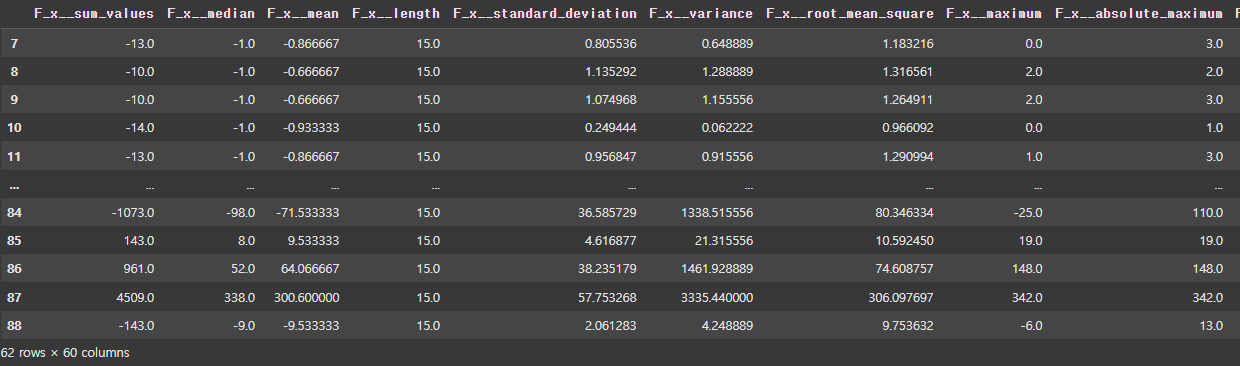
최소한의 데이터를 이용하여 모델 테스트
추출된 특징 시각화
plt.plot(minimal_features_train['F_x__sum_values'])
plt.show()
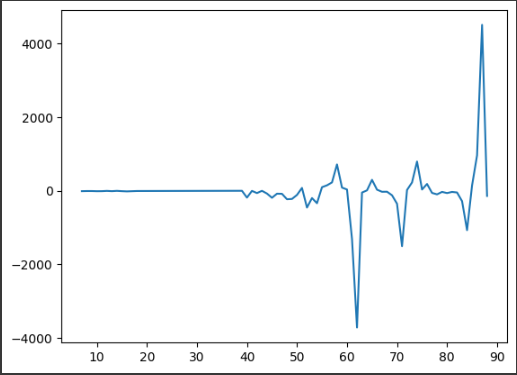
plt.plot(minimal_features_train['T_z__maximum'])
plt.show()
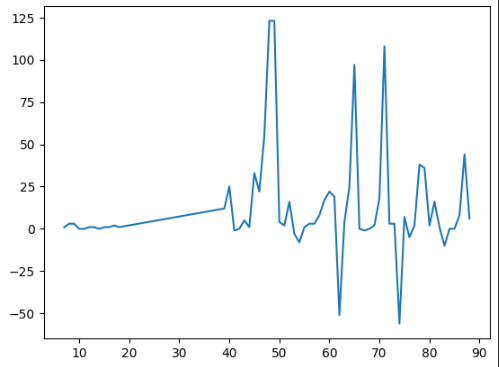
시계열 데이터의 경우 1개의 컬럼에 관해 다양한 지표를 내어 패턴 파악하면 좀 더 높은 성능의 기대값을 나타낼 수 있음
Modeling
# ⑨ Logistic Regression 사용하기
logistic = LogisticRegression()
logistic.fit(minimal_features_train, y_train)
logistic.score(minimal_features_test, y_test)
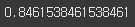
준수하게 나온 편
분류 성능 평가 지표 확인
classification_report(y_test, logistic.predict(minimal_features_test), target_names=['true', 'false'], output_dict=True)
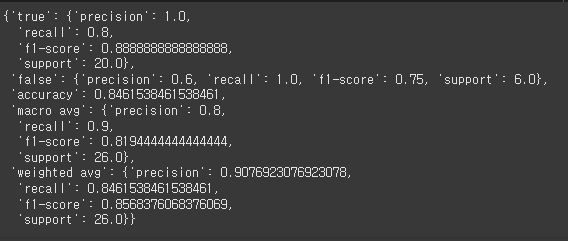
True의 정확도는 1이며 전부 다 맞춤
그에 반해 False 정확도는 0.6이며 60%가량 맞춤
