R을 통해 GDP 성장률 지표를 크롤링하는 것하고 이를 시각화 하는 것을 실습해 보겠습니다. 지난 포스팅에서는 API에 대한 개략적인 설명을 하였습니다. 아래의 링크를 확인하시면 되겠습니다.
오픈 API를 이용 하는 과정은 다음과 같습니다.
-
패키지 실행
-
인증키 및 각종 요청인자 할당
-
API 호출 URL 작성
-
웹에서 XML 파일 다운로드
-
XML 문서를 데이터 프레임으로 변환
-
데이터 클렌징
-
데이터 시각화
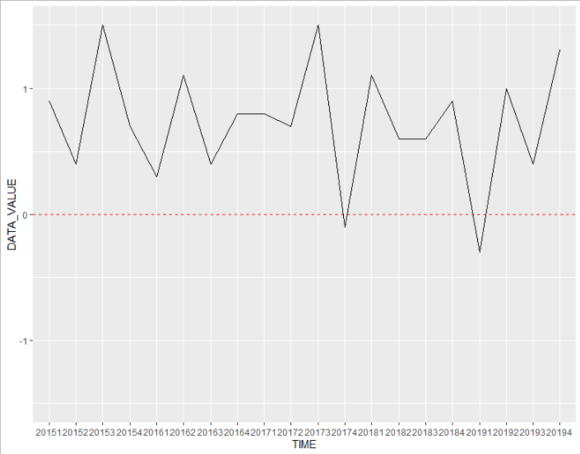
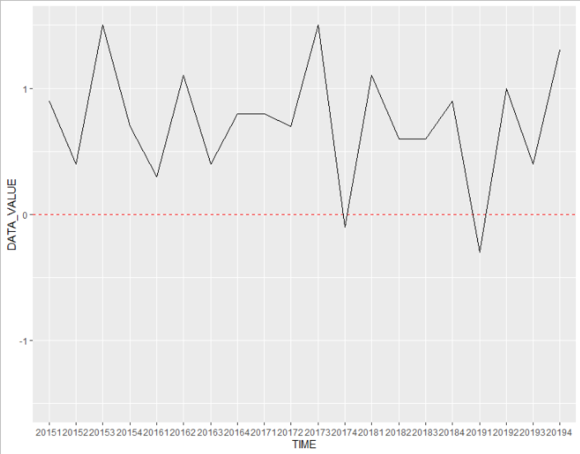
위의 과정을 통해서 이러한 그래프를 그려내 실수가 있습니다.
- 패키지 실행
우선 가장 먼저 XML과 ggplot2패키지를 실행해 주셔야 합니다.
코드는 다음과 같습니다.
library(XML)
library(ggplot2)1) XML패키지를 통해서 xml 편집이 가능하며
2)ggplot2 패키지를 통해 쉽게 시각화 하실 수 있습니다.
- 인증키 및 각종 요청인자 할당
인증키 및 각종 요청인자를 할당해 줍니다. API 호출 URL의 구조는 다음 과 같습니다.
http://ecos.bok.or.kr/api/서비스명/인증키/요청타입/언어/요청시작건수/오쳥종료건수/통게코드/주기/검색시작일자/검색종료일자/항목코드
물론 이대로 직접 입력해 주셔도 되지만, 효율적인 코드 작성을 위해 각 요소들을 변수화 시켜 줍니다.
api_key=자신의 api키를 입력해 주시면 됩니다.
mainindex='111Y055'
date_b='20150101'
date_e='20200601'
gdp_q='10111'- API 호출 URL 작성
그다음으로 paste0를 사용하여, API 호출 URL을 작성해 주시면 됩니다.
url_gdp_g=paste0('http://ecos.bok.or.kr/api/StatisticSearch/',api_key,'/xml/kr/1/100/',mainindex,'/QQ/',date_b,'/',date_e,'/',gdp_q,'/')paste0 함수는 함수 속 객체와 문자열을 이어 붙이는데 사용됩니다. 실제로 함수를 실행하면 다음과 같은 값이 나옵니다.
> url_gdp_g
[1] "http://ecos.bok.or.kr/api/StatisticSearch/자신의 api 키/xml/kr/1/100/111Y055/QQ/20150101/20200601/10111/"
-
웹에서 XML 파일 다운로드
호출 URL을 통해 웹에서 XML파일을 파싱해 줍니다..
xmefile_gdp<-xmlParse(url_gdp_g)
xmlRoot(xmefile_gdp)
이번에 사용한 함수의 용도는 다음과 같습니다.
| 메서드 | 기능 |
|---|---|
| xmlParse() | XML 또는 HTML 파일에 대해 R에서 인식하는 구조로 변환 |
| xmlRoot() | xml 문서 객체의 루트 노드에 접근 |
> xmlRoot(xmefile_gdp)
<StatisticSearch>
<list_total_count>20</list_total_count>
<row>
<STAT_CODE>111Y055</STAT_CODE>
<STAT_NAME>10.1.2. 분기지표</STAT_NAME>
<ITEM_CODE1>10111</ITEM_CODE1>
<ITEM_NAME1>국내총생산(GDP)(실질, 계절조정, 전기비)</ITEM_NAME1>
<ITEM_CODE2> </ITEM_CODE2>
<ITEM_NAME2> </ITEM_NAME2>
<ITEM_CODE3> </ITEM_CODE3>
<ITEM_NAME3> </ITEM_NAME3>
<UNIT_NAME>% </UNIT_NAME>
<TIME>20151</TIME>
<DATA_VALUE>0.9</DATA_VALUE>
</row>
...생략
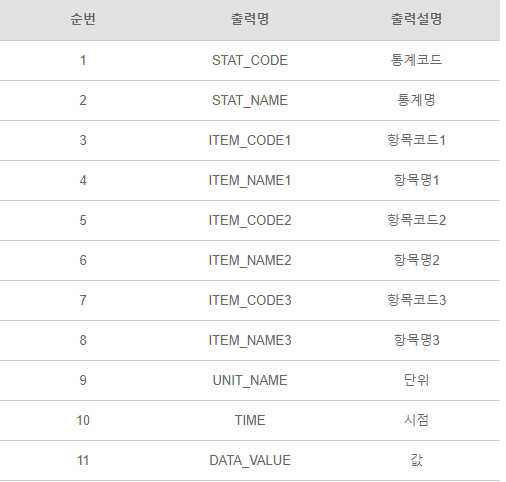
출력값은 다음 과 같은 구조를 띄고 있습니다. 엘리먼트의 서브엘리먼트들이 나열되고 있으며 ECOS의 개발명세서를 확인 하면 다음과 같은 출력값임을 알 수 있습니다.
출력값(Out Result)
-
XML 문서를 데이터 프레임으로 변환
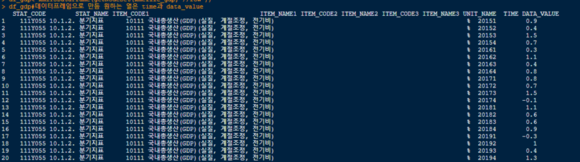
이대로는 데이터를 정제 할 수 없기 때문에 XML문서를 데이터 프레임으로 변환하겠습니다.
df_gdp<-xmlToDataFrame(getNodeSet(xmefile_gdp,'//row'))
위 코드에서 사용된 함수는 다음과 같습니다.| 메서드 | 기능 |
|---|---|
| xmlToDataFrame() | xml문서로 부터 데이터 추출 |
| getNodeSet() | xml노드 검색 |
getNodeSet()을 통해 xmefile_gdp(xml 문서)의 노드 이름이 row인 모든 노드의 서브 노드들의 항목명으로 하는 데이터 프레임을 만들 수 있습니다.
출력값은 다음과 같습니다.
- 데이터 클렌징
str(df_gdp)를 통해 데이터 프레임의 구조를 살표보면 DATA_VALUE가 numeric이 아니기 때문에 그래프를 작성할 때 오류가 발생합니다. 그렇기 때문에 as.numeric 함수를 사용하여, 숫자형 데이터로 바꿔줘야 합니다.
함수는 다음과 같습니다.
df_gdp$DATA_VALUE<-as.numeric(as.charcter(df_gdp$DATA_VALUE)함수를 살펴보면 as.numeric()을 실행하기 전에 미리 as.character을 사용하는 것을 확일 하실 수 있습니다. 이는 바로 숫자형 데이터로 변환시 오류가 생겨 엉뚱한 수로 변환이 되는 것을 방지 합니다.
- 데이터 시각화
ggplot()을 이용해 시계열 그래프를 작성해 보겠습니다.
ggplot(data=df_gdp,aes(x=TIME,y=DATA_VALUE,group=1))+
geom_hline(yintercept = 0,linetype='dashed',color='red')+
coord_cartesian(ylim = c(-1.5,1.5))+
geom_line()1)ggplot()을 이용해 df_gdp를 사용하여 x축은 TIME, y축은 DATA_VALUE로 하는 그래프의 뼈대를 작성해 줍니다. 여기서 group=1을 기입해 주셔야 시계열 그래프 작성시 오류가 발생하지 않습니다.
2)geom_hline()을 통해 0%를 기준선을 만들어 줍니다.
3)coord_cartesian()을 통해 그래프의 범위를 정해 줄 수 있습니다. 저는 y축의 범위를 -1.5 +1.5로 한정 지어 0%를 중앙에 오게 코딩했습니다.
4)마지막으로 geom_line을 통해 시계열 그래프를 그려주시면 됩니다.