
Supervised / Unsupervised learning
Machine leaning
데이터 특징(input) #답이라는 표현보다는, label이라 표현 하는 것이 좋다.
- 답(label)이 있는지
- 답label)이 없는지
목적(output)
- 예측(prediction)
- 분류(classification)
ML Cheat Sheets
Cluster
- instrumental variable: 수 많은 데이터의 origin이 되는 것
ex) 신앙책, 성경 등등 -> instrumental variable은 종교 - 클서스터링은 의미를 파악하는 행위! (PCA 후 클러스터링을 하면 안된다.)
Clustering 과정
1) 임의의 centroid를 설정한다.
2) centroid에서 근처 데이터를 assign하여 cluster를 구한다.
3) point의 평균값을 구해서 centroid를 옮긴다.
4) 다시 assign하여, 새로운 cluster를 구한다.
5) 3-4번을 유의미한 차이가 없을 때 까지 반복한다.
Elbow Method for optimal k
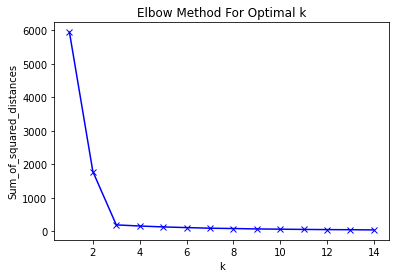
유의미한 cluster를 만들기 위한 k 결정
계층적 군집화(hierachical clustering)
: 여러개의 군집 중에서 가장 유사도가 높은 혹은 거리가 가까운 군집 두 개를 선택하여 하나로 합치면서 군집 개수를 줄여 가는 방법
- Agglomerative: 개별 포인트에서 시작후 점점 크게 합쳐감
- Divisive: 한개의 큰 cluster에서 시작후 점점 작은 cluster로 나눠감
Point assignment
- 시작시에 cluster의 수를 정한 다음, 하나씩 cluster에 배정시킴
Hard vs Soft clustering
- Hard Clustering에서 데이터는 하나의 cluster에만 할당
- Soft Clustering에서 데이터는 여러 cluster에 확률을 가지고 할당
- 일반적으로 Hard Clustering을 Clustering이라 칭함
clutering에 관한 생각 정리
-
Cluster의 순서
1) 임의의 centroid를 설정한다.
2) centroid에서 근처 데이터를 assign하여 cluster를 구한다.
3) point의 평균값을 구해서 centroid를 옮긴다.
4) 다시 assign하여, 새로운 cluster를 구한다.
5) 3-4번을 유의미한 차이가 없을 때 까지(optimize) 반복한다.(for loop) -
Elbow method에서 x축과 y축이 나타내는 것은? 최적의 x값은 어떻게 찾는가?(y로 설명)
x: k 즉, 클러스터의 개수
최적의 x는 기울기가 급격하게 작아지는 지점, 이후 지점과 큰 차이가 없는 reflection point 찾는다. -
y가 나타내는 것은 무엇인가?
y: 클러스터에서 data간 거리 -
clustering을 왜 해야 하나?
클러스터링을 통해 instrumental variable, 수 많은 데이터의 origin이 되는 것을 찾는다.
ex) 신앙책, 성경 등등 -> instrumental variable은 종교 -
clustering을 통해서 비슷한 데이터끼리 묶었다면 결과를 어떻게 해석할 것인가? (business context측면)
1) 새로운 데이터 값이 들어왔을 때 쉽게 분류한다.
2) 분류한 특징에 따라 데이터를 가공하거나 활용한다.
3) 우리가 알지 못하는 데이터의 특성(label)을 정의할 수 있다.
-
y 계산 방법
유클리드 거리 -
scree plot, elbow method와 같은 그래프가 궁극적으로 찾고자 하는 것은 무엇인가? 최소값을 찾고자 하는것인가?
x값을 변경하여 데이터의 특성을 가장 잘 반영할 수 있도록 탐색하는 것이다.
궁금증
Q. 금융권에서 사기거래 탐지도 클러스터링일까??
계좌를 언제 만들고 언제 해지 했는지, 어느 시간대의 송금이나 결제를 하는지를 feature로 삼아
계좌를 clustering하고, 평소와 다른 금융 계좌 패턴을 감지한다고 생각했다.
A. 아니다
클러스터링은 label이 없다. -> 우리가 해석
label이 있다 ->supervised machine learning -> 예측
- label 사기가 아니었다:0 사기였다:1
사기거래는 데이터가 imbalanced 하다.
예를 들어 실제로 99.9% 사기 아니고, 0.1%가 사기일때,
예측을 100% 사기라고 한다면, 정확도 99.9%가 나와 결과값이 무의미해진다.
따라서, 데이터의 balance를 맞춰주어 예측할 수 있도록 만들어야 한다.
단, 여기서 데이터 balance를 맞춰주는 역할이 clustering이 될 수 있다.
예를 들어 사기거래의 label이 주어진 지도학습상황에서, 사기 거래 갯수만큼 데이터를 줄여주는 방법이 있다.
사기 거래 갯수가 5개라면 k=5로 잡고, k-means 클러스터링을 활용하여 실시한다.
hierachical clustering 실습
- discussion에 올려두었으니 답변을 기다리거나, 추후에 다시 고민해보자.
저는 일단 다음과 같이 과제를 진행했습니다.
1. 데이터 불러오기
from scipy.cluster.hierarchy import dendrogram, linkage
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
cancer
여기서 data와 target, feature_names, target_names 등을 확인 했습니다.
- 데이터 전처리
labels = pd.DataFrame(cancer.target)
labels.columns = ['labels']
data = pd.DataFrame(scaler.fit_transform(cancer.data))
data.columns=['mean radius', 'mean texture', 'mean perimeter', 'mean area',
'mean smoothness', 'mean compactness', 'mean concavity',
'mean concave points', 'mean symmetry', 'mean fractal dimension',
'radius error', 'texture error', 'perimeter error', 'area error',
'smoothness error', 'compactness error', 'concavity error',
'concave points error', 'symmetry error',
'fractal dimension error', 'worst radius', 'worst texture',
'worst perimeter', 'worst area', 'worst smoothness',
'worst compactness', 'worst concavity', 'worst concave points',
'worst symmetry', 'worst fractal dimension']
df=pd.concat([data,labels],axis=1)
df.head()
데이터가 어떻게 생겼는지 확인하고 싶어서 데이터 프레임을 만들었고,
데이터프레임을 만드는 과정에서, 이전에 만든 scaler = StandardScaler() 를 통해 data를 스케일러 하였습니다.
- hierarchical clustering 및 시각화
linked = linkage(Z, method ='complete')
plt.figure(figsize=(20, 10))
plt.title('Hierarchical Clustering Dendrogram(truncated)')
plt.xlabel('sample index')
plt.ylabel('distance')
dendrogram(linked, leaf_rotation=90., truncate_mode='lastp', p=8)
plt.show()
x축은 각 노드에 포함되는 sample에 갯수이고, y 축은 element끼리의 거리입니다.
임의로 method ='complete' 로 설정하였습니다.
표시 클러스터의 개수 또한 임의로 8개로 설정하였습니다.
이번 도전 과제 하면서 4가지 물음이 생겼는데 아시는 분이 계시면 답변해주시면 감사하겠습니다.
1. scipy.cluster.hierarchy.linkage 를 쓸 때 y 도 포함된 데이터를 넣는 건가요?
Hierarchical clustering을 이용한 데이타 군집화 이 자료를 참고하여 과제를 수행하였는데, 위 자료에서는 y 값이 포함된 데이터 전체를 linkage 함수에 넣어서 의문이 들었습니다.
- 위 같은 자료에서 Hierarchical clustering 해석 방법으로 Cross tabulation 분석을 사용하는데
from scipy.cluster.hierarchy import fcluster
predict = pd.DataFrame(fcluster(linked,15,criterion='distance'))
predict.columns=['predict']
ct = pd.crosstab(predict['predict'],labels['labels'])
print(ct)
위 내용의 의미가 어떻게 되나요?
-
method를 고르는 기준이 무엇인가요?
자료의 특성을 고려하여 method를 결정한다고 설명이 많은데, 이 특성이 무엇인가요? -
Hierarchical clustering은 적절한 클러스터링 개수를 어떻게 결정하나요?
k-means 같은 경우에 Elbow method를 통해 적절한 k값을 결정하는데 Hierarchical은 어떻게 결정하나요?
과제 수행 하며 참고한 자료
Hierarchical clustering을 이용한 데이타 군집화
Scipy Hierarchical Clustering
SciPy Hierarchical Clustering and Dendrogram Tutorial
클러스터링 실습 (1) (EDA,Sklearn)
