
고유값(eigenvalue)과 고유벡터(eigenvector)
행렬 A를 선형변환으로 봤을 때, 선형변환 A에 의한 변환 결과가 자기 자신의 상수배가 되는 0이 아닌 벡터를 고유벡터, 이 상수배 값을 고유값이라 한다.
즉, n x n 정방행렬(고유값, 고유벡터는 정방행렬에 대해서만 정의된다) A에 대해 Av = λv를 만족하는 0이 아닌 열벡터 v를 고유벡터, 상수 λ를 고유값이라 정의한다.
공분산 행렬의 고유벡터는 데이터가 어떤 방향으로 분산되어 있는지를 찾아준다.
고유값은 고유 벡터 방향으로 얼마만큼의 크기로 벡터 공간이 늘려지는지를 의미한다.
ex)
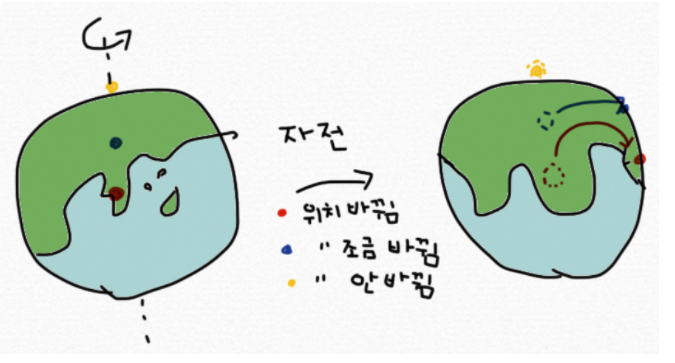
- 고유벡터는 transformation의 영향을 받지 않는 회전축(혹은 벡터 공간)을 말한다. 이는 데이터를 가장 잘 설명하는 축을 의미 한다.
- 여기서 변화하는 크기는 결국 스칼라 값으로 변화 할 수 밖에 없는데, 이 특정 스칼라 값을 고유값이라고 한다.
- eigenvector와 eigenvalue는 항상 쌍을 이루고 있다
- feature의 갯수 = eighgen vector(Eigenvector가 있는 n x n square matrix(정방행렬A)에는 n 개의 eigenvector가 존재
공분산 행렬
: 주어진 임의 벡터의 각 요소 쌍 간의 공분산을 제공하는 정방 행렬
- 데이터 구조적으로 i feature와 j feature의 변동이 얼마나 닮았나?
- (공분산: 2개의 확률변수의 선형 관계를 나타내는 값. 만약 2개의 변수중 하나의 값이 상승하는 경향을 보일 때 다른 값도 상승하는 선형 상관성이 있다면 양수의 공분산을 가진다.)
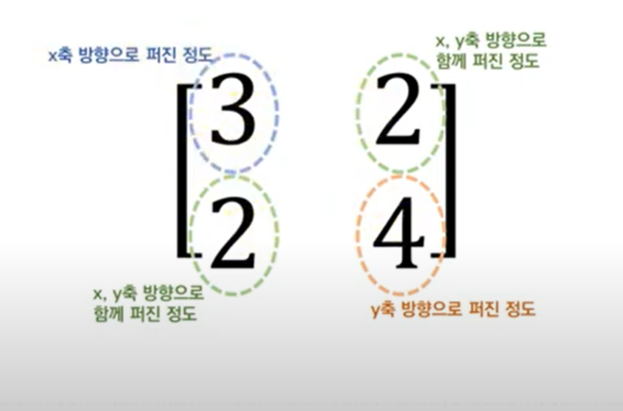
- 분산(1차원) vs 공분산(2차원 이상)
Dimesion Reduction
Dimension
Dimension 차원 = 변수(column)
Dimension이 늘어난다? 데이터를 바라보는 관점이 다양해진다.
Feature Selection
- 장점: 선택된 feature 해석이 쉽다.
- 단점 : feature들간의 연관성을 고려해야함.
- 예시 : LASSO, Genetic algorithm 등
Feature Extraction
- 장점 : feature 들간의 연관성 고려됨. feature수 많이 줄일 수 있음
- 단점 : feature에 대한 개별적 해석이 어려움.
- 예시 : PCA, Auto-encoder 등
PCA(Principal component analysis)
: 고차원의 데이터를 저차원의 데이터로 linear projection을 통해 환원시키는 기법
- 분산이 가장 커지는 축을 첫 번째 주성분, 두 번째로 커지는 축을 두 번째 주성분으로 놓이도록 선형변환 한다.
- 중요한 성분들은 공분산 행렬의 고유 벡터이기 때문에 직교하게 된다.
- 데이터가 가지고 있는 분산의 형태를 최대한 유지할 수 있는 결합을 만드는 것(drop이 아님)
PCA를 하는 이유
-
메모리상 효율적으로 바꿔준다.
-
모델의 성능이 올라간다. 머신에 넣었을 때 계산을 쉽게 하기 위함
-
해석이 용이한 것은 아니다.(pca는 의미 도출이 불가하기 때문)
Projecting data onto eigenvectors of 공분산 행렬
ex) 3차원 데이터의 경우
3개의 eigenvector가 나옴
이 중 eigenvalue가 큰 두개의 eigenvector가 이루는 평면에 데이터를 정사영할 수 있음(분산을 가장 크게하는 축을 찾기 위해). 이를 통해 2차원으로 감소된 데이터를 획득할 수 있음.
-> 고유벡터에 데이터를 정사영하여 얻은 data의 variance가 최대가 된다.
data의 정보는 variance이다?
분산이란 x와 평균의 차이를 의미한다.
즉, 예측값이 대푯값으로 부터 멀리 흩어져 있으면 결과의 분산이 높다고 말한다.
(feature의 관측값이 data이다.)
한 feature 내의 variance가 큰 것은 의미가 없지만,
x-y(예측하고자 하는 관계)에서는 variance가 크면 정보를 추출함에 유의미하다.
Data Scailing
PCA, 회귀분석 등을 하기 전에는 스케일링이 필요하다.
Why?
- 판단: 알고리즘을 보고 판단. 데이터의 거리를 최소화하는 방향으로 만드는 알고리즘에 적용.(아닌 알고리즘도 있음)
- 역할: 데이터를 보는 것이 스케일링 역할
ex) 나 10점 만점의 10점 vs 친구 100점 만점의 20점
이러한 숫자를 비교 가능하게 만듬
선형변환(Linear Transformation)
: 첫 번째 집합의 임의의 한 원소를 두 번째 집합의 오직 한 원소에 대응시키는 이항 관계. 쉽게 말해, 한 점을 한 벡터공간에서 다른 벡터공간으로 이동시키는데 그 이동 규칙을 선형변환이라 한다.
- 행렬 = 선형변환, 벡터 공간을 다른 벡터 공간으로 mapping
- linear projection도 vector transformation의 일부이다.
Scree Plot
- 다변량 통계에서 scree plot은 분석에서 주성분 고유 값에 대한 선 그림이다.
- scree plot은 주성분에서 유지해야 할 요인의 수를 결정하는 데 사용된다.
- reflection point를 찾는 것(기울기가 급격하게 작아지는 지점, 이후 지점과 큰 차이가 없을때)

x축은 차원의 수(0이 pca1일때를 나타냄)이고, y축은 고유값이다.
주성분의 수는 이 고윳값의 크기를 사용하여 결정할 수 있다. 고유값이 가장 큰 주성분을 유지한다.
이를 수치적으로 보기 위해 데이터 프레임으로 표현해보았다.

기여율은 각각의 주성분이 설명할 수 있는 비율이다.
여러 주성분을 사용할 때 설명 가능한 비율은 누적기여율을 통해 확인할 수 있다.
누적기여율은 기여율의 합이다.
차원이 3개일 때, 97.3% 로 90%의 내용을 설명할 수 있다.
