
오늘 배운 것
붓스트랩(Bootstrapping)
: sample에서 중복가능한 subset of data를 무작위 추출
- 모든 열은 포함하지만, 데이터의 갯수만 줄여서 추출(!= 열의 개수를 다르게 추출하는 것)
- 모수에 대한 추정치를 정확하게 보고 싶을 때 사용 (confidence interval)
- CLT를 기반으로 함
공분산

상관계수
분모를 나눠준 이유

- 공분산을 scailing 해준 것
- 전체 데이터로 나눠준 것
- 비교 가능해진다 (데이터 분석의 상대성)
평균, cov, corr는 모두 기댓값! -> 아웃라이어에 약함
데이터 분석에서 다른 고려사항도 같이 생각해야 함 ex) 중앙값, 독립
상관계수는 벡터의 내적이다.
📎상관계수=벡터의 내적
벡터의 내적
= vector a의 vector b로의 정사영 x vector b
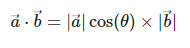
= 벡터 a의 변화를 벡터 b가 얼마만큼 설명해 줄 수 있는가?
수직인 벡터는 상관관계가 없다. (cos90 = 0)
선형결합/생성/기저벡터
1. xy 좌표계의 기저벡터(=단위벡터): i-hat, j-hat
- 스칼라 들이 스케일하는 실제 대상
- 벡터 공간의 기저는 공간 전체를 생성하는 선형 독립인 벡터의 집합
1) 스케일링: 벡터의 방향은 유지한 채, 그 크기는 늘이거나 줄이거나 뒤집는 과정
2) 스칼라: 벡터를 스케일하는 숫자(선대에서 주된 역할이기 때문에 '스칼라'='숫자'로 쓰임)
2. 선형결합(Linear combination)
1) 2차원

: 두 벡터를 스케일하고, 더하여 새 벡터를 얻을 수 있는 모든 연산
2) 3차원
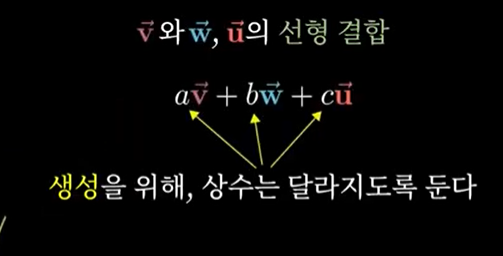
: 세 벡터를 스케일하고, 더하여 얻을 수 있는 모든 연산
3. 생성(span)
: 주어진 벡터 쌍의 선형결합으로 다다를 수 있는 모든 결과 벡터의 집합
1) 2차원
두 벡터의 선형생성 -> 벡터의 덧셈, 스칼라배
Q. 두가지 연산만으로 다다를 수 있는 모든 벡터는?
i. 대부분의 2차원 벡터 쌍(=2차원 벡터 공간 전체, 2차원 평면)
ii. 일렬인 벡터쌍(= 끝점이 직선에 한정되는 모든 벡터, 방향이 같음)
iii. 영벡터인 두 벡터 쌍의 생성(=원점)
2) 3차원
R³ 선형결합인 세 벡터들의 모든 집합
= 생성 in R³
i. 세번째 벡터가 다른 두 벡터의 선형생성에 있음(=같은 평면 위에 같힘)
ii. 세번째 벡터가 다른 두 벡터의 선형생성에 있지 않음(= 모든 가능한 3차원 벡터, 3차원 공간전체)
4. 선형종속 (Linearly Dependent Vector)
: 벡터 중 하나가 다른 벡터들의 선형결합으로 표현
(이미 다른 벡터들의 생성에 속하므로)
5. 선형독립 (Linearly Independent Vectors)
: 벡터 모두가 각자 생성에 다른 차원을 구성
(같은 선상에 있지 않은 경우)
Rank
: 매트릭의 열을 이루고 있는 벡터들로 만들 수 있는 공간의 차원
- 매트릭스의 차원과 다를 수 있음(행 or 열 벡터 중 서로 선형관계 있을 수 있기 때문)
- Rank 확인 방법 중 하나 Gaussian Elimination
Gaussian Elimination
: 매트릭스를 "Row-Echelon form"으로 바꾸는 계산과정
- Row-Echelon form: 각 행에 대해 왼쪽에 1 그 이후 부분은 0으로 이뤄진 형태

맨 마지막 줄 0,0,0 3개의 행이 선형관계가 있다.(다른 행들의 스칼라 곱과 합으로 표현됨)
Rank = 2
3x3 매트릭스이지만 만을 벡터들로 만들어 낼 수 있음
Linear Projection(정사영)
📎Vector Projection using Python
import numpy as np
# 1) 다른 벡터 위에 벡터 투영
u = np.array([1, 2, 3]) # vector u
v = np.array([5, 6, 2]) # vector v
v_norm = np.sqrt(sum(v**2))
proj_of_u_on_v = (np.dot(u, v)/v_norm**2)*v
# 2) 평면에 벡터 투영
u = np.array([2, 5, 8]) # vector u
n = np.array([1, 1, 7]) # n은 평면 P에 대한 직교 벡터
n_norm = np.sqrt(sum(n**2))
proj_of_u_on_n = (np.dot(u, n)/n_norm**2)*n
