문제
어떤 수열이 다른 수열의 부분 수열이라는 것은 다음을 의미합니다.
해당 수열의 원소들이 다른 수열 내에서 순서대로 등장합니다.
예를 들어, 는 의 부분 수열이지만, 의 부분 수열은 아닙니다.
또한, 어떤 수열이 다른 수열보다 사전 순으로 나중이라는 것은 다음을 의미합니다.
두 수열 중 첫 번째 수가 큰 쪽은 사전 순으로 나중입니다. 두 수열의 첫 번째 수가 같다면, 첫 번째 수를 빼고 두 수열을 다시 비교했을 때 사전 순으로 나중인 쪽이 사전 순으로 나중입니다. 길이가 인 수열과 다른 수열을 비교하면, 다른 수열이 사전 순으로 나중입니다.
양의 정수로 이루어진 길이가 인 수열 이 주어집니다. 마찬가지로 양의 정수로 이루어진 길이가 인 수열 이 주어집니다.
수열 와 수열 가 공통으로 갖는 부분 수열들 중 사전 순으로 가장 나중인 것을 구하세요.
입력
첫 줄에 수열 의 길이 이 주어집니다.
둘째 줄에 개의 양의 정수 이 주어집니다.
셋째 줄에 수열 의 길이 이 주어집니다.
넷째 줄에 개의 양의 정수 이 주어집니다.
출력
와 의 공통 부분 수열 중 사전 순으로 가장 나중인 수열의 크기 를 출력하세요.
이라면, 다음 줄에 개의 수를 공백으로 구분해 출력하세요. 번째 수는 와 의 공통 부분 수열 중 사전 순으로 가장 나중인 수열의 번째 수입니다.
예제 입력 1
4
1 9 7 3
5
1 8 7 5 3
예제 출력 1
2
7 3
다음 수열들은 모두 와 의 공통 부분 수열입니다.
이 중 사전 순으로 가장 나중인 수열은 입니다.
아이디어
이 문제는 크게 두 단계로 나누어 풀이할 수 있다. 첫 번째는 순서까지 일치하는 공통된 부분 집합을 구하는 것, 두 번째는 가능한 수열 중 가장 나중인 것을 구하는 것이다. 첫 번째
첫 번째 풀이
-
테스트 케이스는 통과, 제출했을 때 틀림
-
부분 수열 조건과 사전 순 정렬을 두 가지 단계로 나누어 코드를 구현함
-
수열을 찾는 find 함수에서A의 원소와 B의 원소가 동일하면 B의 앞 부분을 삭제하도록 코드를 구현했다. 아래 케이스의 경우 {1, 3, 4}과 {1, 5, 4} 모두 공통된 수열이다. 그러나 내 코드의 논리대로면 {1, 3, 4}만 검사해 이 코드의 논리가 잘못되었음을 알 수 있다.
-
예시 케이스
4
1 3 5 4
4
1 5 3 4
import sys
def find(A,B):
stack = []
for i in range(len(A)):
curra = A[i]
for j in range(len(B)):
if B[j] == curra:
del B[:j+1]
stack.append(curra)
break
return stack
def sort_dict(arr):
answer = []
while(arr):
max_idx = arr.index(max(arr))
answer.append(arr[max_idx])
del arr[:max_idx+1]
return answer
N = int(sys.stdin.readline().strip())
A = list(map(int,sys.stdin.readline().split()))
M = int(sys.stdin.readline().strip())
B = list(map(int,sys.stdin.readline().split()))
if N<M:
inter = find(A,B)
else:
inter = find(B,A)
print(inter)
answer = sort_dict(inter)
print(len(answer))
if len(answer)!=0:
for a in answer:
print(a,end=' ')두 번째 풀이
- 통과
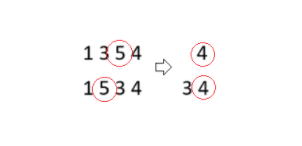
- 첫 번째 풀이의 잘못된 논리를 해결하기 위해서는 공통된 수열이 여러 개 발생할 수 있음을 파악하고 그리디하게 공통된 수열을 찾도록 구현해야 한다. 그리디하게 원소를 선택하는 조건은 사전식 순서를 고려하면 된다. 따라서 A와 B에서 가장 큰 공통된 값을 찾고 그 값의 뒤에 있는 원소들에 대해서 계속적으로 가장 큰 공통된 값을 찾도록 구현한다. 따라서 아래 예시 케이스의 경우 아래 그림의 순서대로 탐색하게 된다.
- 예시 케이스
4
1 3 5 4
4
1 5 3 4
import sys
sys.setrecursionlimit(10**6)
def find(A,B,answer):
#print("find ",A,B,answer)
if len(A) == 0 or len(B) == 0:
return answer
a_max,b_max = max(A),max(B)
a_idx,b_idx = A.index(a_max), B.index(b_max)
if a_max == b_max:
answer.append(a_max)
return find(A[a_idx+1:],B[b_idx+1:],answer)
elif a_max > b_max:
A.pop(a_idx)
return find(A,B,answer)
else:
B.pop(b_idx)
return find(A,B,answer)
N = int(sys.stdin.readline().strip())
A = list(map(int,sys.stdin.readline().split()))
M = int(sys.stdin.readline().strip())
B = list(map(int,sys.stdin.readline().split()))
temp = find(A,B,[])
if temp:
print(len(temp))
for t in temp:
print(t,end=' ')
else:
print(0)
