1. 개요

챌린지 팀 프로젝트에서 대용량 데이터를 다룰 때, 해당 데이터가 저장된 데이터베이스, 정확히는 RDBMS에서 순식간에 모든 데이터의 필드 값들이 업데이트되는 작업이 빈번했다. 당시야 백엔드의 B도 몰라서 열심히 노가다를 했었는데 얼마 전에 스프링 관련 공부를 하다가 스프링 배치에 대하여 알게 됐다.
키워드는 이미 들어봐서 예전에는 단순 스케줄러 느낌으로 받아들였는데, 생각 이상으로 다양한 기능 및 영속성과의 통합성을 제공하며 대용량 처리에 있어 아주 유용한 프레임워크라는 생각이 들었다. 호기심 반, 스킬 확장 반으로 무작정 뛰어들어봤다.
1) 배치 프로세싱(Batch Processing)
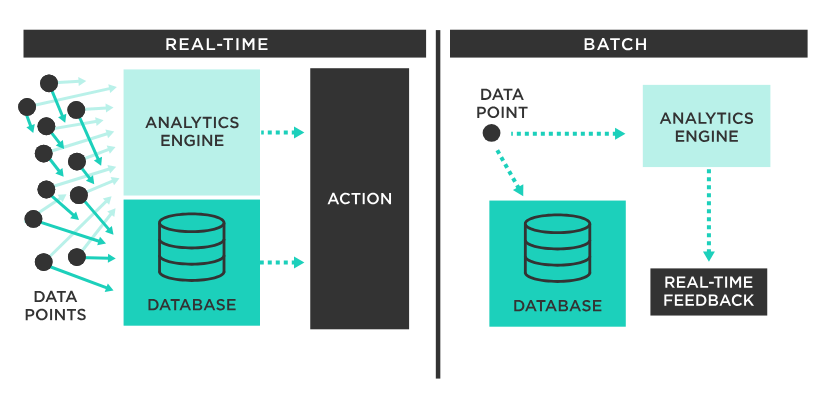
배치(Batch)라는 영단어는 일괄, 집단이라는 의미를 가진다. 그리고 스프링 배치가 수행하는 대규모 데이터의 일괄 처리 기능을 배치 처리(배치 프로세싱)이라고 하며, 이 배치 처리를 가지고 활용하는 프레임워크를 배치 프레임워크라 한다.
배치 프로세싱을 통해 얻을 수 있는 이점은 다음과 같다.
1. 대용량 데이터 반복 처리 효율화
설계 취지가 대용량 데이터 반복 처리의 효율성 향상이기 때문에 데이터 백업, 필터링, 정렬, 청구, 급여 처리, 월말 조정 등에서 강점을 보인다.
2. 비용 및 노동력 절감
이른바 '배치 기간' 동안 데이터를 일괄 처리함으로써, 조직은 지속적인 사람의 개입 없이도 컴퓨팅 리소스의 활용 선택 범위를 넓힐 수 있게 된다.
3. 데이터 일관성 및 무결성 향상
배치 처리로 여러 데이터 트랜잭션을 단일 배치로 결합하여 개별적인 처리 트랜잭션과 관련된 오버헤드를 줄여주기 때문에 처리 능력, 메모리 및 기타 컴퓨팅 리소스 사용 효율성이 증가한다.
4. 데이터 변환 및 강화
각각의 배치 처리에 미리 정의된 규칙, 계산 또는 변환 집합을 적용하여 데이터를 변환하고 보강할 수 있으므로, 원시 데이터에서 의미 있는 인사이트를 추출하고 데이터를 정제하거나 정규화하여 활용도를 높인다.
5. 확장성 및 에러 핸들링
데이터 일괄 처리의 크기를 쉽게 조정하고 워크로드에 따라 규모를 늘리거나 줄일 수 있어서 다양한 데이터 처리 수요에 능동적이다. 또한 오류 로깅 및 예외 처리 메커니즘을 제공한다.
2) 배치 처리 vs 스트림 처리
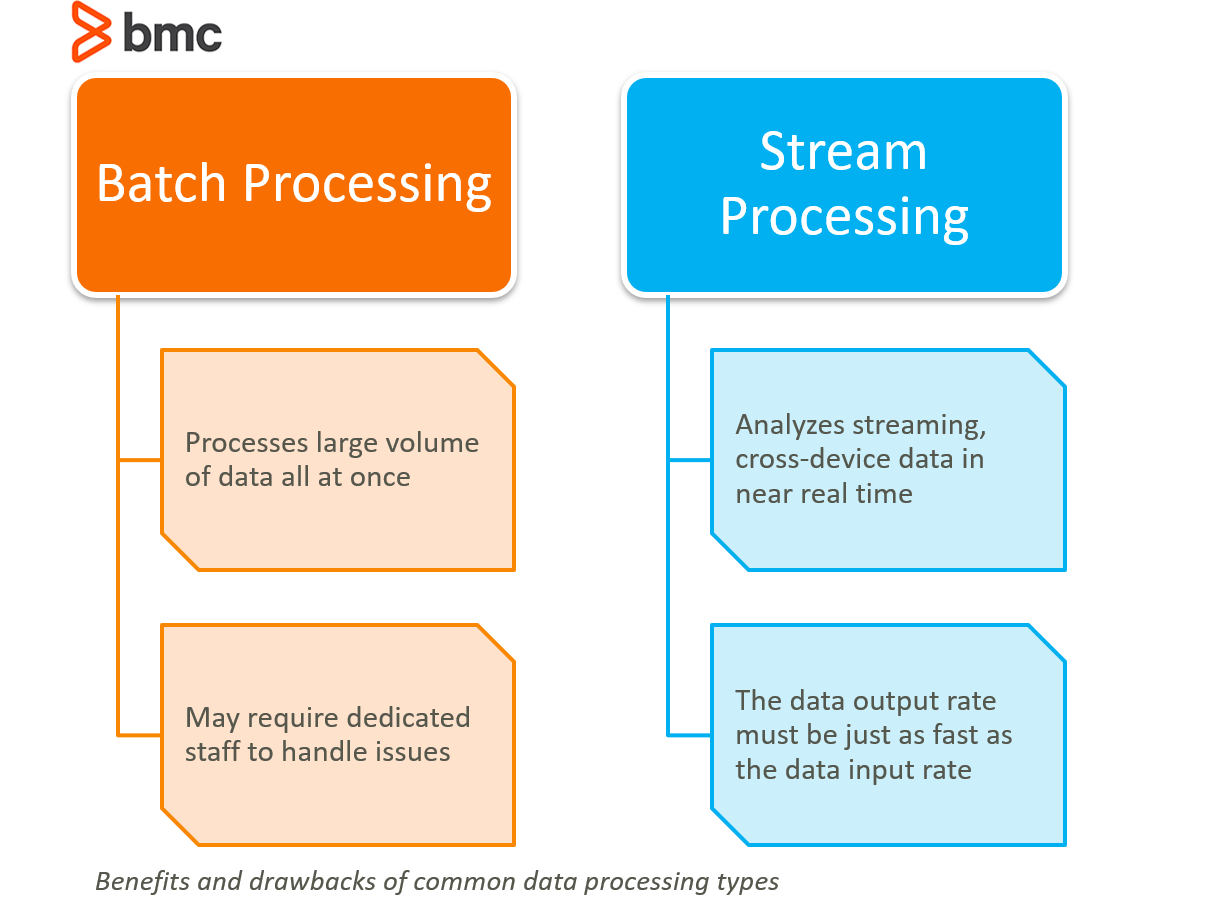
사실 자바 코드를 다루면서 뭔가 비슷한 애를 본 느낌이 들었는데, 자바 8 버전에서 추가됐던 스트림이었다. 스트림의 목적인 데이터 처리 및 변환이 배치 처리와 일부 겹치는 느낌이었다. 물론 파이프라인을 구축해서 즉각적인 데이터 레코드에 반응하는 확실한 차이점을 알고 있었지만 조금 더 정확한 개념 비교를 위해 내용을 비교해봤다.
차이점 비교
| 특징 | 배치 처리 (Batch Processing) | 스트림 처리 (Stream Processing) |
|---|---|---|
| 시간 민감도 | 데이터를 일정 기간 동안 모아서 처리 (예: 시간별, 일별, 주별). | 데이터가 발생하는 즉시 처리, 실시간 분석 및 반응에 적합. |
| 지연 시간 (Latency) | 데이터를 모은 후 처리하므로 지연 시간이 길다. | 개별 데이터나 이벤트를 즉시 처리하므로 지연 시간이 짧다. |
| 데이터량 (Volume) | 한 번에 대량의 데이터를 처리하도록 설계됨. | 지속적으로 들어오는 고속 데이터 스트림 처리에 적합. |
| 복잡성 (Complexity) | 데이터를 한꺼번에 처리하기 때문에 복잡한 변환, 집계, 계산이 가능. | 개별 데이터 단위나 짧은 시간 내의 데이터만 처리하므로 간단한 연산과 실시간 반응에 초점. |
사용 사례별 비교
| 사용 사례 | 배치 처리 예시 | 스트림 처리 예시 |
|---|---|---|
| 로그 분석 | 로그 데이터를 모아 하루나 일주일 단위로 보고서 생성. | 로그를 실시간으로 분석하여 오류 발생 시 즉시 감지. |
| 금융 거래 | 하루가 끝난 후 거래 내역을 정산하거나 보고서 생성. | 실시간으로 이상 거래를 감지하고 경고. |
| ETL (추출-변환-적재) | 데이터 웨어하우스로 대량 데이터 마이그레이션 및 변환. | 스트리밍 데이터를 실시간으로 데이터베이스에 적재하거나 대시보드로 전달. |
| 추천 시스템 | 구매 기록 등 과거 데이터를 기반으로 추천 모델 학습. | 사용자가 실시간으로 활동할 때 즉각적인 상품 추천 제공. |
| IoT 애플리케이션 | 수집된 IoT 센서 데이터를 일정 기간 동안 분석하여 트렌드 도출. | 온도 변화나 모션 데이터를 실시간으로 감지하여 즉시 알림. |
요약하자면, 배치 처리는 누적된 데이터들의 일괄적인 처리를 위해 수집을 기다리는 과정에서 지연 시간이 생기지만 복잡한 계산 및 변환이 가능하며 스트림 처리는 상대적으로 볼륨이 작은 고속 데이터 스트림 처리에 집중하여 이벤트성으로 동작하기 때문에 실시간성에 특화됐다고 볼 수 있다.
2. 스프링 배치 개념
1) 스프링 배치 아키텍처
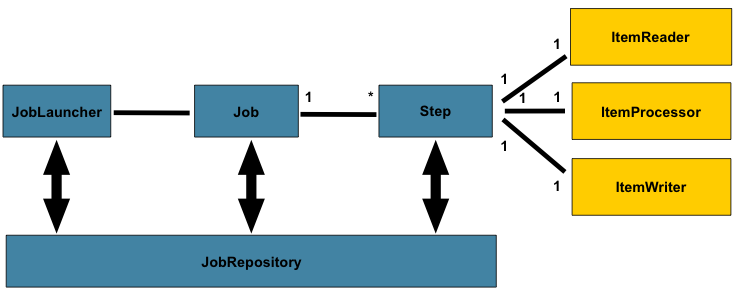
자바 기반의 스프링 배치 이전(C, C#, 코볼 등등..)에도 웬만한 배치 프레임워크는 위의 청사진을 따랐다고 봐도 무방하다. 이후의 다양한 배치 프레임워크도 위와 같은 아키텍처를 기반으로 설계됐다. 스프링 배치와 관련돼서 우선 숙지할 키워드는 Job, Step, 그리고 Reader-Processor-Writer 구조다. 각각의 관계는 아래의 문장으로 설명할 수 있다.
배치 처리의 단위인 Job은 여러 Step으로 구성되며, Step은
Reader-Processor-Writer구조로 구성되어 있다.
이게 무슨 말인지 각 키워드들에 대해 파악해보자.
2) Job
실무적인 배치 처리는 상당히 복잡한 여러 과정들이 얽히고 섥혀있다. 그래서 더욱 중요한 것이 배치 처리 작업의 단위화를 통해 구별해야 하는데, 이 단위가 곧 Job이 된다. 조금 더 IT스럽게(?) 표현하자면 Job은 단위 배치 프로세스를 캡슐화한 엔티티가 된다. 후술할 Step이 조금 더 실체화된 개념에 가깝고 Job은 그런 Step들을 모아 묶어주는 인스턴스 컨테이너 개념에 가깝다.
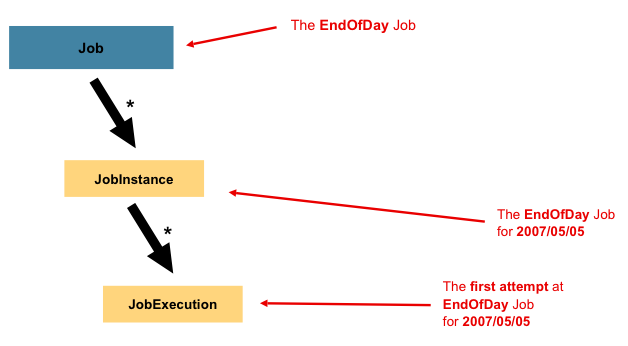
- Job : 특정 작업
- JobInstance : 며칠에 혹은 반복적으로 진행될 특정 작업
- JobExecution : 며칠에 혹은 반복적으로 몇 번째에 진행될 특정 작업
이런 Job도 결국 인스턴스나 실행 개념을 가지고, 스프링 배치에서는 이를 JobInstance와 JobExecution으로 구현했다. 위의 그림을 보면 정리할 수 있다. 이런 식으로 계층을 세분화하는 이유는 나중에 등장할 메타데이터 저장을 위해서다.
@Bean
public Job footballJob(JobRepository jobRepository) {
return new JobBuilder("footballJob", jobRepository)
.start(playerLoad())
.next(gameLoad())
.next(playerSummarization())
.build();
}스프링 배치는 JobBuilder를 활용해서 Job을 빌드하면서 해당 Job의 명칭을 정해줄 수 있다. 그리고 해당 명칭을 통해 배치 처리를 수행할 때, 내가 원하는 작업을 호출할 수 있는데, JobRegistry를 통해 가져올 수 있다. 아래 코드처럼 가지고 올 수 있다.
private final JobRegistry jobRegistry;
// ...
jobLauncher.run(jobRegistry.getJob("footballJob"), jobParameters);앞서 말했듯 Job은 인스턴스화된 개념인 JobInstance가 존재한다. 이것 역시 개념에 불과하기 때문에 코드로 다루거나 직접 관여할 일은 없다. 하지만, 특정 Job(시급 산정을 예로 들자)에 있어서 3월 1일에 진행한 배치 처리 작업과 3월 2일에 진행한 배치 처리 작업은 다르게 취급되어야 한다. 바로 이것이 JobInstance의 존재 이유가 되고, 기록의 필요 근거가 된다.
이것을 그럼 스프링 배치에서는 어떻게 구별하냐면, 바로 JobParameter를 통해서다.
JobParameters jobParameters = new JobParametersBuilder()
.addString("date", value)
.toJobParameters();JobParameter는 외부에서 부여된 중복되지 않는 값을 해시 알고리즘으로 고유 해시값을 생성해서 각 JobInstance를 구별하는 Key 역할을 하게 된다. 이 내용들은 메타데이터 저장소에서 확인이 가능하다. 이렇게 파라미터를 부여해서 JobLauncher를 통해 스프링 배치 처리의 단위 작업을 실행할 수 있게 된다.
3) Step
Step은 배치 Job의 독립적이고 순차적인 단계를 캡슐화한 도메인 객체다. 정확히 말하자면, 실제 배치 처리의 모든 정보를 담고 순차화한 것이다. Step의 범위는 단순 처리에서부터 복잡한 비즈니스 로직까지 다양하게 정할 수 있기 때문에 그 개념의 범위는 모호한 편이다. 개발자에 따라 Job을 Step처럼 쓸 수도 있고 Step을 여러 개로 나눠 Job을 논리적으로 세분화할 수도 있다.
@Bean
public Step firstStep() {
log.info("JPA: 첫 번쨰 스탭");
return new StepBuilder("firstStep", jobRepository)
.<BeforeEntity, AfterEntity>chunk(10, transactionManager)
.reader(beforeReader()) // 읽기 메소드 파라미터
.processor(middleProcessor()) // 처리 메소드 파라미터
.writer(afterWriter()) // 쓰기 메소드 파라미터
.build();
}스프링 배치에서 Step은 JobBuilder 기반의 메서드 체이닝에서 파라미터로 들어가는 빈 메소드로 생성이 되며, 그 재부 구조는 Reader-Processor-Writer 단계의 파라미터를 요구하게 된다. StepBuilder를 통해 Step을 생성할 수 있다.
4) Reader-Processor-Writer
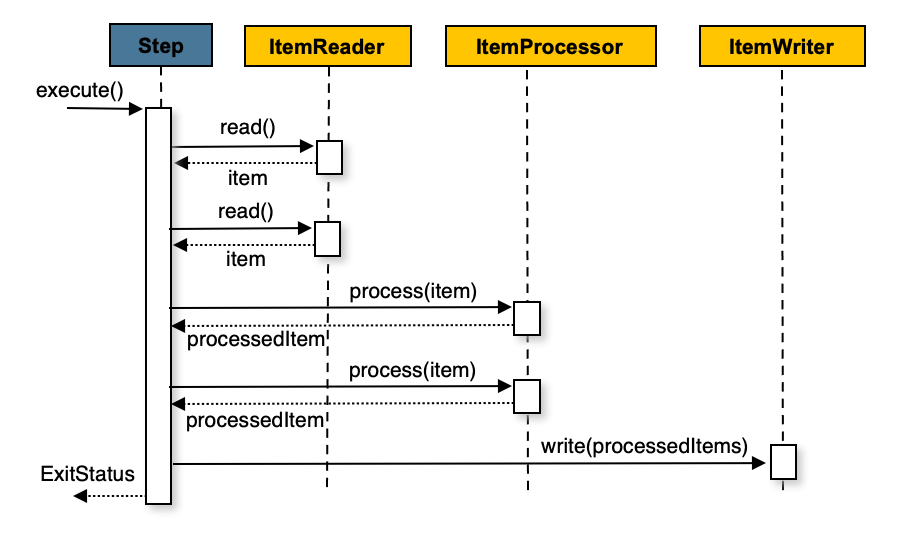
논리적으로 대규모의 데이터를 처리하려면, 처리 대상인 데이터를 확인(읽기)하고, 해당 데이터를 처리한 다음, 처리된 데이터를 업데이트(쓰기)하는 단계를 가지게 될 것이다. 그 구조를 아키텍처로써 명시한 것이 Reader-Processor-Writer 형태가 되는 것이며 스프링 배치에서도 이를 채택하고 있다.
여기서 나오는 개념이 Chunk(이하 청크)인데, 청크는 배치 처리에서 데이터를 읽고 처리하고 쓰는 기본 단위가 된다. 한 번에 모든 데이터를 읽고 처리하고 쓰면 이론상 빠르겠지만 메모리 사용량과 트랜잭션 처리량이 엄청 높아지면서 성능이 저하되기 때문에 끊어서 처리하는 단위인 청크가 필요한 것이다.
청크 단위가 너무 작으면 I/O 처리가 많아지고 오버헤드가 발생할 수 있고, 너무 크면 적재 및 자원 사용에 대한 비용과 실패시 부담이 커지기 때문에 프로젝트 상황에 맞춰 적절한 청크 단위 지정이 요구된다.
/**
* BeforeEntity 테이블에서 읽어오는 Reader
* JPA 기반 쿼리 수행이므로 RepositoryItemReader 사용
*/
@Bean
public RepositoryItemReader<BeforeEntity> beforeReader() {
return new RepositoryItemReaderBuilder<BeforeEntity>()
.name("beforeReader")
.pageSize(10) // findAll 메소드의 페이징 처리
.methodName("findAll")
.repository(beforeJpaRepository)
.sorts(Map.of("id", Sort.Direction.ASC)) // 자원 낭비 방지용 sort
.build();
}
/**
* 읽어온 데이터를 처리하는 Process
* (큰 작업을 수행하지 않을 경우 생략 가능, 지금과 같이 단순 이동은 사실 필요 없음)
*/
@Bean
public ItemProcessor<BeforeEntity, AfterEntity> middleProcessor() {
return item -> {
AfterEntity afterEntity = new AfterEntity();
afterEntity.setUsername(item.getUsername());
// 대응되는 AfterEntity 엔티티를 생성
return afterEntity;
};
}
/**
* AfterEntity 테이블에 처리한 결과를 저장하는 Writer
*/
@Bean
public RepositoryItemWriter<AfterEntity> afterWriter() {
return new RepositoryItemWriterBuilder<AfterEntity>()
.repository(afterJpaRepository)
.methodName("save") // save 메소드
.build();
}스프링 배치에서는 ItemReader, ItemProcessor ItemWriter 인터페이스를 제공하며, 이 인터페이스를 구현하여 커스터마이징한 청크를 구축할 수 있다. 구체적으로 우리가 흔히 생각하는 RDBMS에서의 배치 처리 뿐만 아니라, NoSQL, 메세지 큐, 엑셀 파일 등의 다양한 영속성의 청크를 구현할 수 있게 된다. 이 세 개의 인터페이스 빌더 빈 메소드들은 Step의 메서드 체이닝 파라미터로 제공돼서 단일 Step을 이루게 된다.
5) 메타데이터 저장소
아까 위의 JobInstance의 구분에서 잠깐 말했는데, 스프링 배치는 모든 Job 및 그 내부의 Step의 실행을 기록한다. 그 실행을 기록하는 곳이 메타데이터 저장소가 된다. 실제로 메타데이터 저장소에 접근하면 이제까지 실행됐던 배치 작업들과 관련하여 상세히 기록되어 있다.
이는 작업 상태를 정확하게 추적하고, 실패한 작업에 대하여 이전 상태를 참조해서 재시작을 지원해주고 정보를 조회하게 하는 등, 메타적인 부분에 대한 지원 때문이다. 모든 JobInstance를 구분하는 파라미터 역시 메타데이터 저장소에 기록되어 있기 때문에 중복된 파라미터를 부여하면 배치 처리가 실행되지 않는 것이다.
지금까지 알아본 내용들은 배치 처리 및 스프링 배치와 관련된 개념적인 부분이고, 다음 포스팅에서는 JPA 및 JDBC 환경 하에서 실제로 스프링 배치를 활용해 구현해본다.
출처
https://spring.io/projects/spring-batch
https://www.digitalroute.com/resources/glossary/batch-processing/
