3. 스프링 배치 구현 개요

스프링 배치는 단순 스케줄러 개념이 아닌, 다양한 영속성과 통합하여 대용량 일괄 처리를 수행하는 프레임워크다. 여기서 말하는 영속성은 쉽게 말해서 저장소다.
대용량 일괄 처리를 실무적인 수준으로 고안하는 건 아직 내 수준에서는 어려워서... 일단은 간단하게 데이터베이스 테이블 간의 복사와 테이블 일괄 업데이트를 구현해봤다. 현재는 영속성을 RDBMS로 두고 스프링 배치를 구현하지만, 차후의 포스팅에서는 NoSQL(아마 익숙한 Redis나 MongoDB가 될 것 같음)와의 통합 구현도 수행해 볼 예정이다.
1) 사전 준비
앞서 말했듯, 스프링 배치에는 메타데이터 저장소 구축도 필요하다. 만약 배치 처리 대상이 RDBMS이고, 메타데이터 저장소도 RDBMS로 선택한다면 멀티 데이터베이스 연결 설정을 해줘야 한다. 이외에도 기타 여러 설정들이 존재하기 때문에, 우선은 환경 설정부터 해본다.
참고로 나는, 배치 처리 대상과 메타데이터 저장소를 둘 다 MySQL로 진행한다.
(1) 의존성 추가
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-batch'
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.boot:spring-boot-starter-web'
compileOnly 'org.projectlombok:lombok'
runtimeOnly 'com.mysql:mysql-connector-j'
annotationProcessor 'org.projectlombok:lombok'
testCompileOnly 'org.projectlombok:lombok'
testAnnotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testImplementation 'org.springframework.batch:spring-batch-test'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}제일 중요한 스프링 배치 의존성을 추가하고, 개발에 용이한 롬복, JPA 활용을 위한 Spring Data JPA, 컨트롤러 기반 배치 처리 호출을 위한 Spring Web, MySQL 연결을 위한 의존성을 추가했다.
(2) application.yml
spring:
application:
name: batch-practice
batch:
# prevent auto batch when app is initialized
# to use endpoint or scheduling
job:
enabled: false
# meta data table for managing batch job
jdbc:
initialize-schema: always
schema: classpath:org/springframework/batch/core/schema-mysql.sqlspring.batch.job.enabled는 앱이 실행될 때 자동으로 배치 처리를 수행할 지를 여부를 정하기 때문에 나는 false로 설정했다. spring.batch.jdbc는 메타데이터 저장소의 테이블 관리를 맡으며 MySQL 기반 스크립트를 사용하고 스키마를 실행할 때마다 재생성하도록 설정한다.
# meta data DB info(like record)
datasource-meta:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3307/meta_db?useSSL=false&useUnicode=true&serverTimezone=Asia/Seoul&allowPublicKeyRetrieval=true
username: user
password: password
# process data DB info
datasource-data:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3308/data_db?useSSL=false&useUnicode=true&serverTimezone=Asia/Seoul&allowPublicKeyRetrieval=true&postfileSQL=true&logger=Slf4JLogger&maxQuerySizeToLog=999999&rewriteBatchedStatements=true
username: user
password: password원래 스프링부트 앱은 디폴트가 하나의 RDBMS 연결을 상정하기 때문에 여러 개의 RDBMS 연결 설정을 하면 앱 실행이 안되기 때문에 멀티 데이터베이스 연결을 위한 설정 클래스를 별도로 작성해야 한다. 일단은, 배치 처리 대상 데이터베이스 정보와 메타데이터 저장소 정보를 명시해둔다.
2) 다중 데이터베이스 연결
(1) 데이터베이스 연결 설정 클래스
/**
* meta DB config for batch
*/
@Configuration
public class MetaDBConfig {
@Primary // @Primary 설정한 테이블에 테이블을 자동으로 메타데이터 테이블 생성
@Bean
@ConfigurationProperties(prefix = "spring.datasource-meta")
public DataSource metaSource() {
return DataSourceBuilder.create().build();
}
@Primary
@Bean
public PlatformTransactionManager metaTransactionManager() {
return new DataSourceTransactionManager(metaSource());
}
}메타데이터 저장소 연결을 위해 yml 파일에서 설정한 설정 접두어를 properties로 빈 메소드에 부여한다. @Primary 어노테이션이 등록되면 해당 테이블에 자동으로 메타데이터 테이블을 생성하게 된다.
/**
* data DB config for batch
*/
@Configuration
@EnableJpaRepositories(
basePackages = "com.example.batchpractice.repository",
entityManagerFactoryRef = "dataEntityManager",
transactionManagerRef = "dataTransactionManager"
)
public class DataDBConfig {
@Bean
@ConfigurationProperties(prefix = "spring.datasource-data")
public DataSource dataSource() {
return DataSourceBuilder.create().build();
}
/**
* JPA 사용한 데이터베이스 연결을 위한 EntityManagerFactory 설정하는 코드
* JDBC 배치 처리와는 직접적인 연관 x
*/
@Bean
public LocalContainerEntityManagerFactoryBean dataEntityManager() {
LocalContainerEntityManagerFactoryBean factoryBean = new LocalContainerEntityManagerFactoryBean();
factoryBean.setDataSource(dataSource());
factoryBean.setPackagesToScan("com.example.batchpractice.entity");
factoryBean.setJpaVendorAdapter(new HibernateJpaVendorAdapter());
Map<String, Object> properties = new HashMap<>();
properties.put("hibernate.hbm2ddl.auto", "update");
properties.put("hibernate.show_sql", true);
factoryBean.setJpaPropertyMap(properties);
return factoryBean;
}
@Bean
public PlatformTransactionManager dataTransactionManager() {
JpaTransactionManager transactionManager = new JpaTransactionManager();
transactionManager.setEntityManagerFactory(dataEntityManager().getObject());
return transactionManager;
}
@Bean
public PlatformTransactionManager jdbcTransactionManager() {
return new DataSourceTransactionManager(dataSource()); // JDBC 트랜잭션 관리
}
@Bean
public JdbcTemplate jdbcTemplate() {
return new JdbcTemplate(dataSource());
}
}배치 처리 대상이 되는 데이터베이스 연결 설정에서 나는 JPA와 JDBC를 같이 구현하기 위해 둘의 연결 설정을 별도로 구현했다. 데이터 소스 생성 메소드를 빈으로 등록해서 각각의 트랜잭션 관리 메소드와 JdbcTemplate에 부여해줬다. 참고로 JPA는 EntityManager에 상호작용할 대상 데이터베이스 정보 명시가 필요하기 때문에 EntityManagerFactory 설정도 빈으로 추가했다.
(2) 도커 컴포즈 세팅
사실 MySQL이 로컬에 세팅되어 있으면 의미없지만, 나는 도커 연습을 위해 도커 컴포즈로 배치 처리 대상 RDBMS와 메타데이터 저장소 RDBMS를 간단하게 컨테이너로 띄웠다. 배치 처리 연습이 목적이라서 볼륨 세팅은 따로 하지 않았다.
services:
meta-db:
image: mysql:latest
container_name: mysql-meta
ports:
- "3307:3306"
environment:
MYSQL_ROOT_PASSWORD: root_meta
MYSQL_USER: user
MYSQL_PASSWORD: password
MYSQL_DATABASE: meta_db
data-db:
image: mysql:latest
container_name: mysql-data
ports:
- "3308:3306"
environment:
MYSQL_ROOT_PASSWORD: root_data
MYSQL_USER: user
MYSQL_PASSWORD: password
MYSQL_DATABASE: data_db여기까지 했으면 멀티 데이터베이스 소스 기반 앱 실행 준비가 끝났다. 이제, 스프링 배치 구현을 해보자.
4. 배치 처리 - 테이블 복사
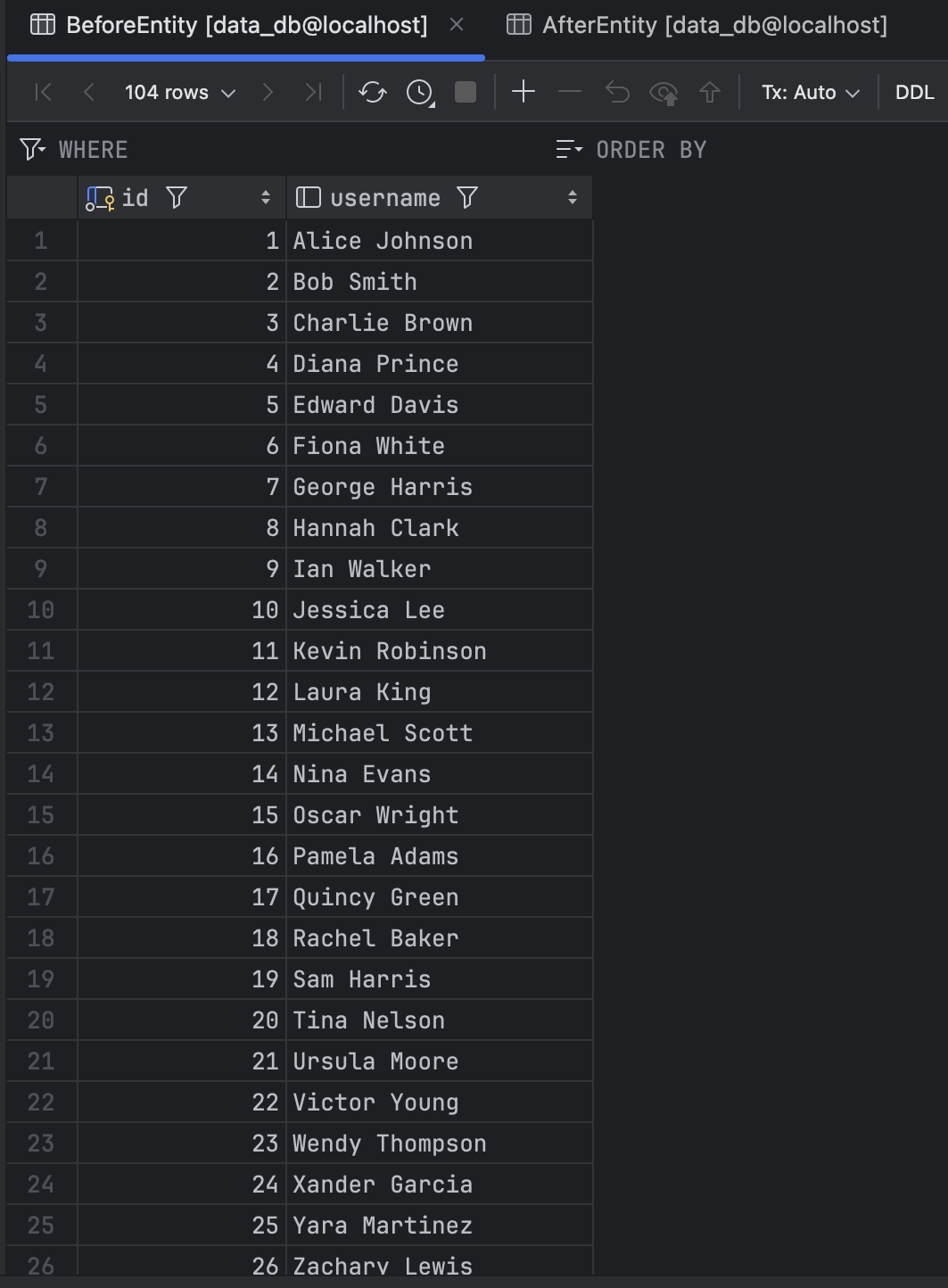
시나리오 및 그에 따른 임시 엔티티(BeforeEntity, AfterEntity)는 다음과 같다.
특정 테이블(BeforeEntity)의 모든 데이터를 다른 테이블(AfterEntity)에 그대로 복사한다.
@Entity(name = "BeforeEntity")
@Getter
@Setter
public class BeforeEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String username;
}@Entity(name = "AfterEntity")
@Getter
@Setter
@NoArgsConstructor
public class AfterEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String username;
public AfterEntity(String username) {
this.username = username;
}
}BeforeEntity 테이블에 미리 데이터를 삽입하고, 비어 있는 AfterEntity에 복사가 이뤄질 거라서, 미리 BeforeEntity에 데이터를 산입시킨다.
1) JPA 기반 스프링 배치 구현
ORM 바탕의 인터페이스인 JPA는 스프링부트로 간단한 CRUD 구현에서 용이하게 쓰이는 편이다. JPA 구현체인 Hibernate를 통해 데이터베이스와의 객체 매핑을 실현한다. 자주 쓰이기 때문에 JPA 기반으로 스프링 배치를 먼저 구현해본다.
(1) 코드 작성
@Slf4j
@Configuration
@RequiredArgsConstructor
public class FirstJpaBatch {
private final JobRepository jobRepository;
private final PlatformTransactionManager transactionManager;
private final BeforeJpaRepository beforeJpaRepository;
private final AfterJpaRepository afterJpaRepository;
@Bean
public Job firstJob() {
log.info("JPA: before 엔티티 테이블 -> after 엔티티 테이블 옮기기");
return new JobBuilder("firstJob", jobRepository) // 파라미터: 작업명 및 트래킹용 레포
.start(firstStep()) // 스탭 파라미터
// .next() // 스탭 파라미터
.build();
}
@Bean
public Step firstStep() {
log.info("JPA: 첫 번쨰 스탭");
return new StepBuilder("firstStep", jobRepository)
.<BeforeEntity, AfterEntity>chunk(10, transactionManager)
.reader(beforeReader()) // 읽기 메소드 파라미터
.processor(middleProcessor()) // 처리 메소드 파라미터
.writer(afterWriter()) // 쓰기 메소드 파라미터
.build();
}
@Bean
public RepositoryItemReader<BeforeEntity> beforeReader() {
return new RepositoryItemReaderBuilder<BeforeEntity>()
.name("beforeReader")
.pageSize(10) // findAll 메소드의 페이징 처리
.methodName("findAll")
.repository(beforeJpaRepository)
.sorts(Map.of("id", Sort.Direction.ASC)) // 자원 낭비 방지용 sort
.build();
}
@Bean
public ItemProcessor<BeforeEntity, AfterEntity> middleProcessor() {
return item -> {
AfterEntity afterEntity = new AfterEntity();
afterEntity.setUsername(item.getUsername());
// 대응되는 AfterEntity 엔티티를 생성
return afterEntity;
};
}
@Bean
public RepositoryItemWriter<AfterEntity> afterWriter() {
return new RepositoryItemWriterBuilder<AfterEntity>()
.repository(afterJpaRepository)
.methodName("save") // save 메소드
.build();
}
}(1) Reader
BeforeEntity에서 모든 데이터를 읽어온다(2) Processor
BeforeEntity에 대응되는 모든 데이터와 동일한 내용의 AfterEntity를 생성한다.(3) Writer
모든 AfterEntity를 저장한다.
각 메소드별 설명은 이전 포스팅에서 상세히 서술해뒀기 때문에 생략한다.
(2) 배치 처리 실행 방법
이제 이렇게 생성한 배치 작업("firstJob")을 실행하는 방법은 API 호출 실행과 스케줄러 기반 실행이 있다. 둘 다 실행해본 다음, 성능 테스트를 수행해보자.
REST API 호출 기반
컨트롤러에 API 호출 메소드를 세팅하고, Job 파라미터를 직접 제공하면서 호출하는 방식이다.
@Controller
@RequestMapping("/jpa")
@RequiredArgsConstructor
public class JpaBatchController {
// job 실행을 위한 의존성들
private final JobLauncher jobLauncher;
private final JobRegistry jobRegistry;
@GetMapping("/first")
public ResponseEntity<?> firstApi(@RequestParam("value") String value) throws Exception {
JobParameters jobParameters = new JobParametersBuilder()
.addString("date", value)
.toJobParameters();
jobLauncher.run(jobRegistry.getJob("firstJob"), jobParameters);
return new ResponseEntity<>("first batch complete for JPA", HttpStatus.OK);
}
// ...Job 실행을 위해 의존성으로 JobLauncher와 JobRegistry를 주입받아 컨트롤러 메소드에서 배치 처리 실행을 맡긴다.
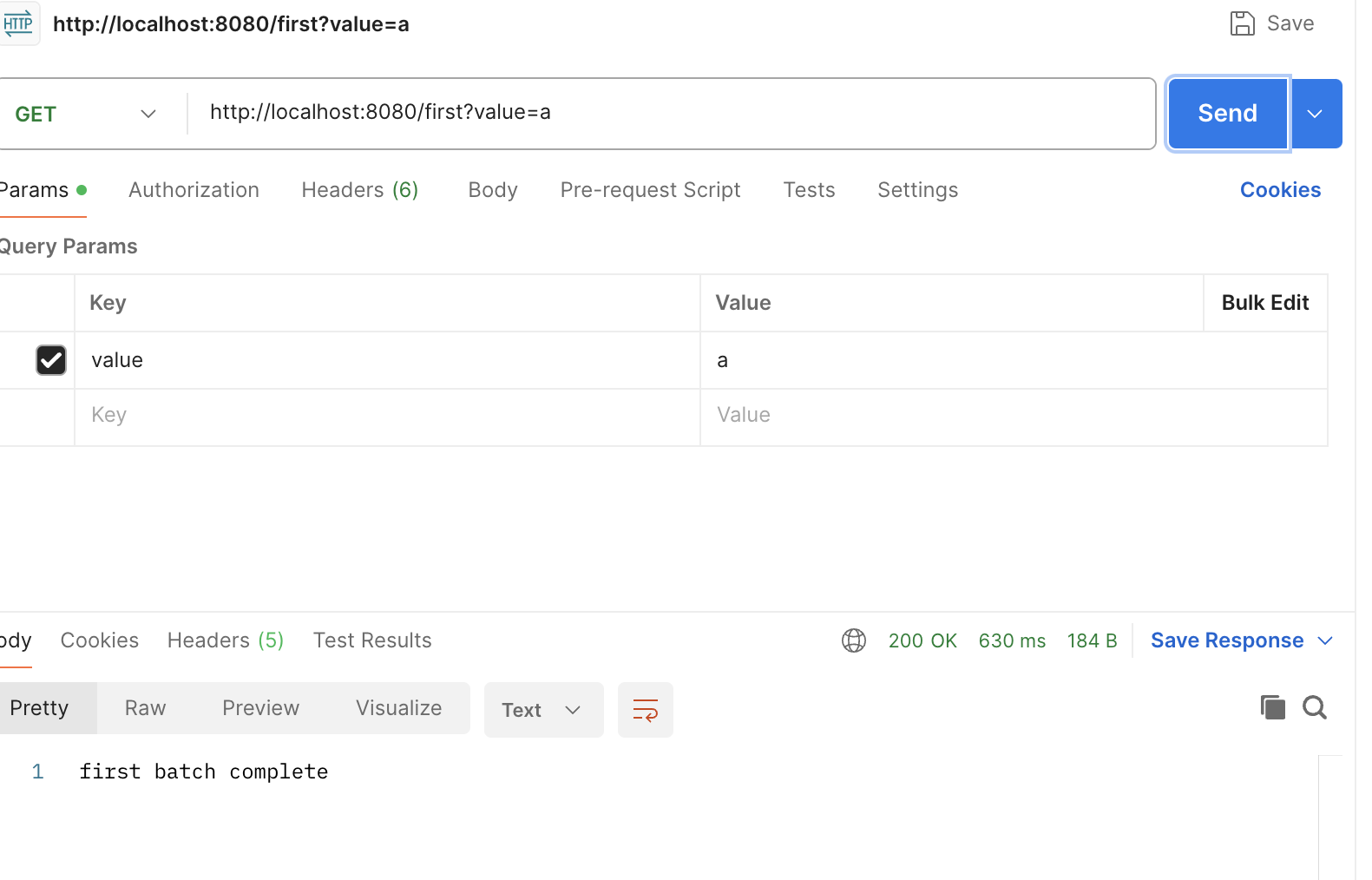
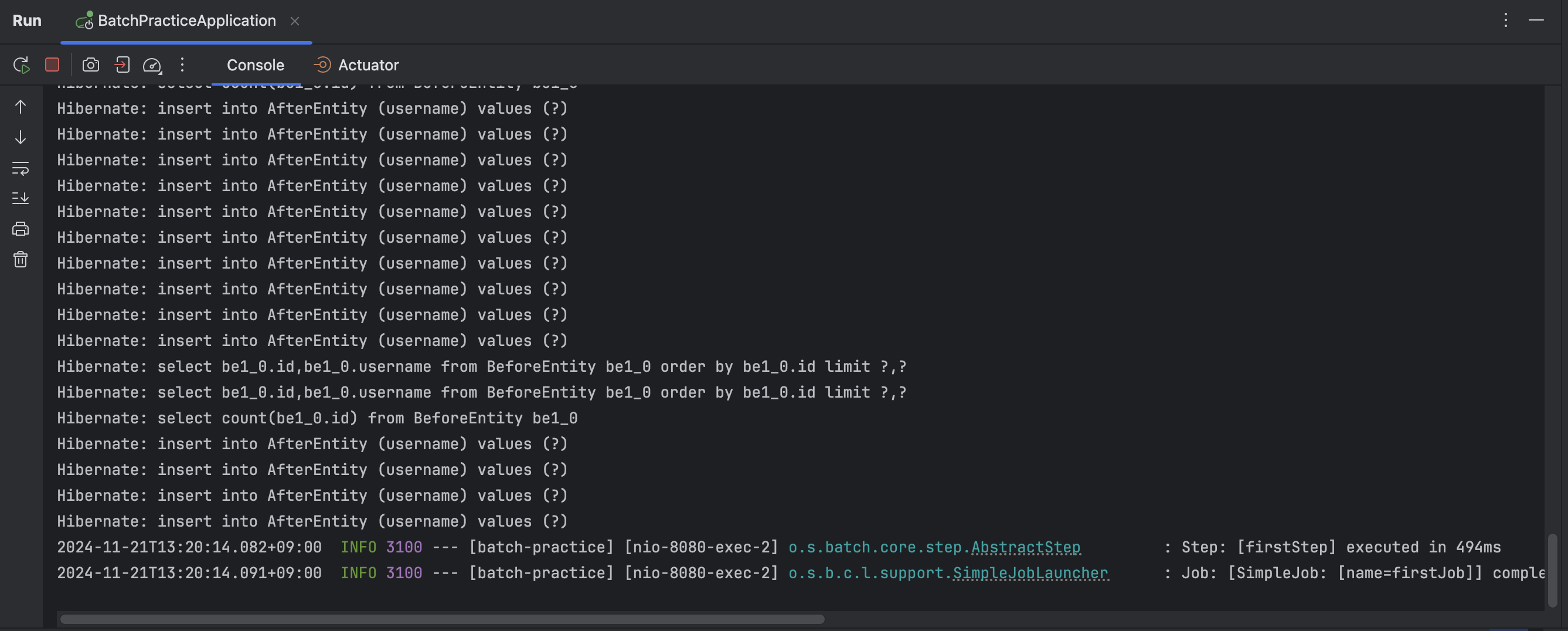

포스트맨으로 해당 API 엔드포인트를 호출한 결과, 배치 처리가 되면서 AfterEntity에 데이터가 복사된 것을 확인할 수 있다.
앞서 말했듯, 파라미터는 고유값이기 때문에 중복된 파라미터를 제공해 새로운 JobInstance를 생성하려 하면 예외를 반환시킨다. 이를 한 번 확인해보자. 아까 위에서 제공한 파라미터는 문자열 a이다. 여기서 똑같은 파라미터를 제공해서 배치 처리를 실행해본다.
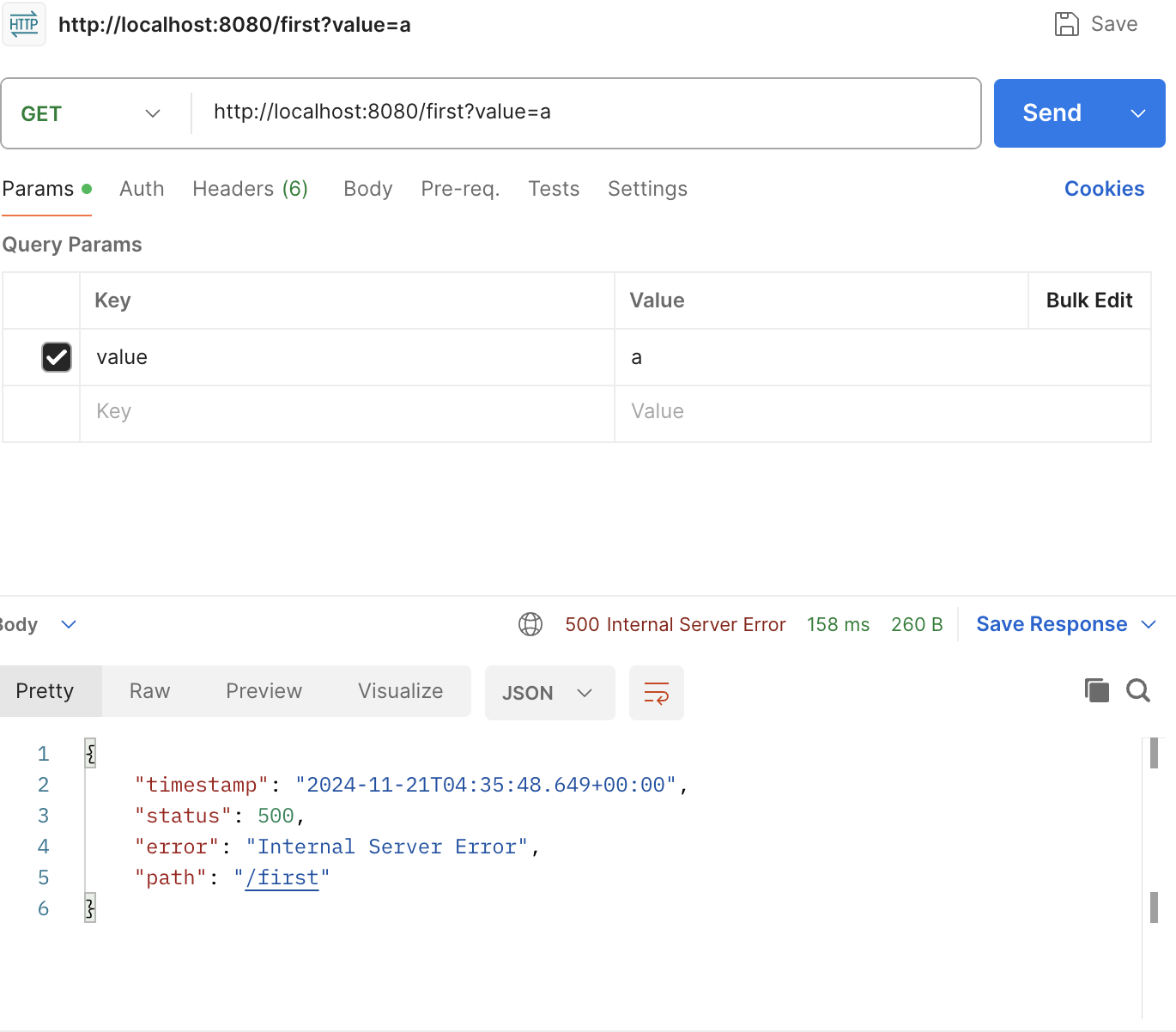
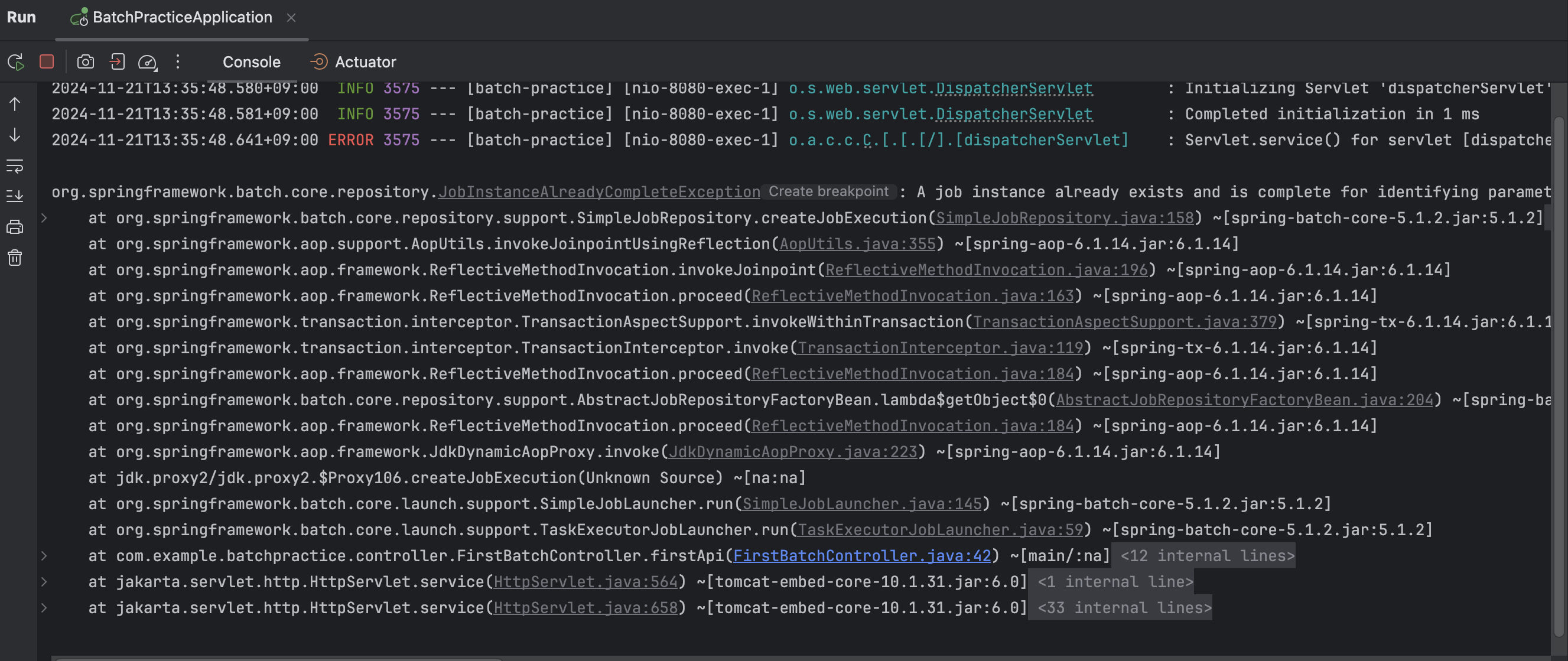
보다시피 예외를 반환하는 것을 확인할 수 있다. 즉, 파라미터는 고유값을 항상 제공해야 배치 처리가 반복 실행될 수 있다. 아래처럼 문자열 b라는 고유값을 파라미터로 제공하면 실행이 된다.

스케줄러 기반
사실 배치 처리 실행은 스케줄러가 더 큰 의미가 있는데, 보통 JobInstance의 파라미터값으로 중복되지 않는 값을 부여해야 하는데 생각할 수 있는 대표적인 것이 날짜이기 때문이다. 날짜는 계속 시간 단위로 변하기 때문에 절대로 중복될 수 없으며 반복 실행에도 부합한 파라미터다.
일단 Truncate Table AfterEntity 명령어로 테이블을 전부 비우고 ID 순서 조정을 한 다음, 스케줄러를 구현하자.
@Slf4j
@Configuration
@RequiredArgsConstructor
public class FirstSchedule {
private final JobLauncher jobLauncher;
private final JobRegistry jobRegistry;
@Scheduled(cron = "10 * * * * *", zone = "Asia/Seoul") // 매 분 10초마다 해당 배치 실행
public void firstSchedule() throws Exception {
log.info("first schedule start");
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd-hh-mm-ss");
String date = dateFormat.format(new Date());
JobParameters jobParameters = new JobParametersBuilder()
.addString("date", date)
.toJobParameters();
jobLauncher.run(jobRegistry.getJob("firstJob"), jobParameters);
}
}크론식을 써서 매 10초가 되면 해당 배치 처리가 실행되도록 스케줄러를 세팅했다.
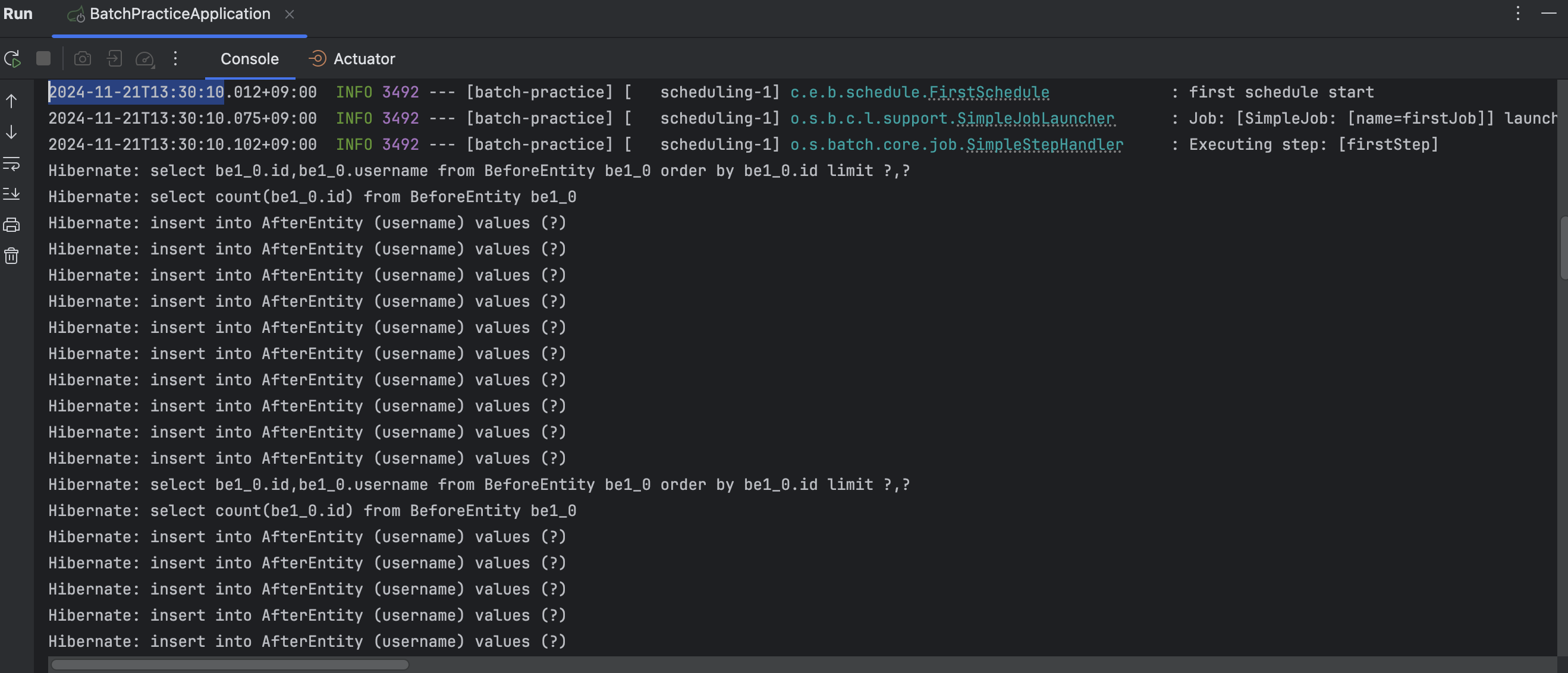
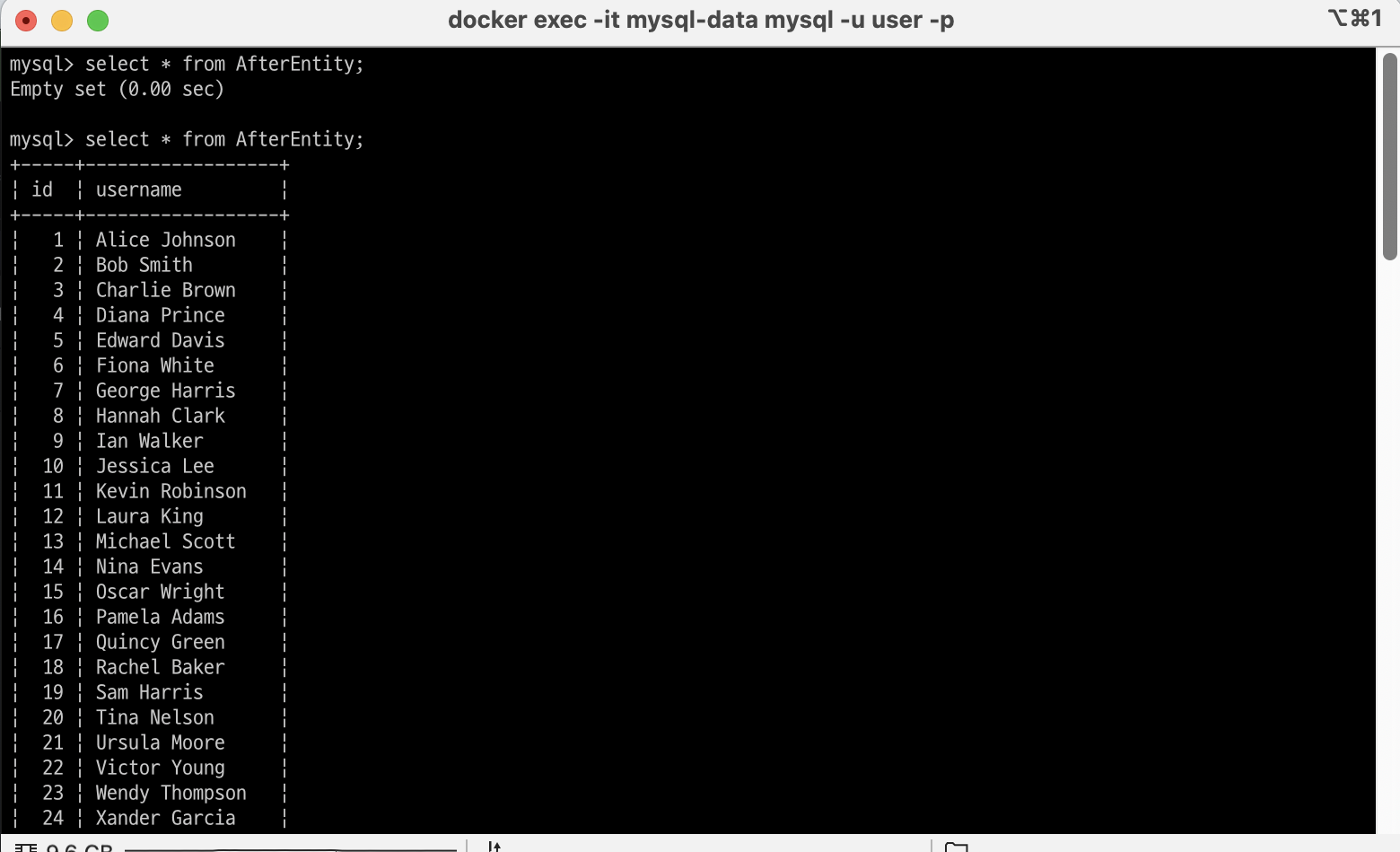
별도의 실행 명령이 없어도 자동으로 10초가 되면 배치 처리가 이뤄지는 것을 확인할 수 있다.
(3) 메타데이터 저장소 확인
아까 설정에서 MySQL로 메타데이터 저장소를 구축했었다. 메타데이터 저장소에 실제로 파라미터와 작업명이 저장되는 지를 확인할 수 있다.
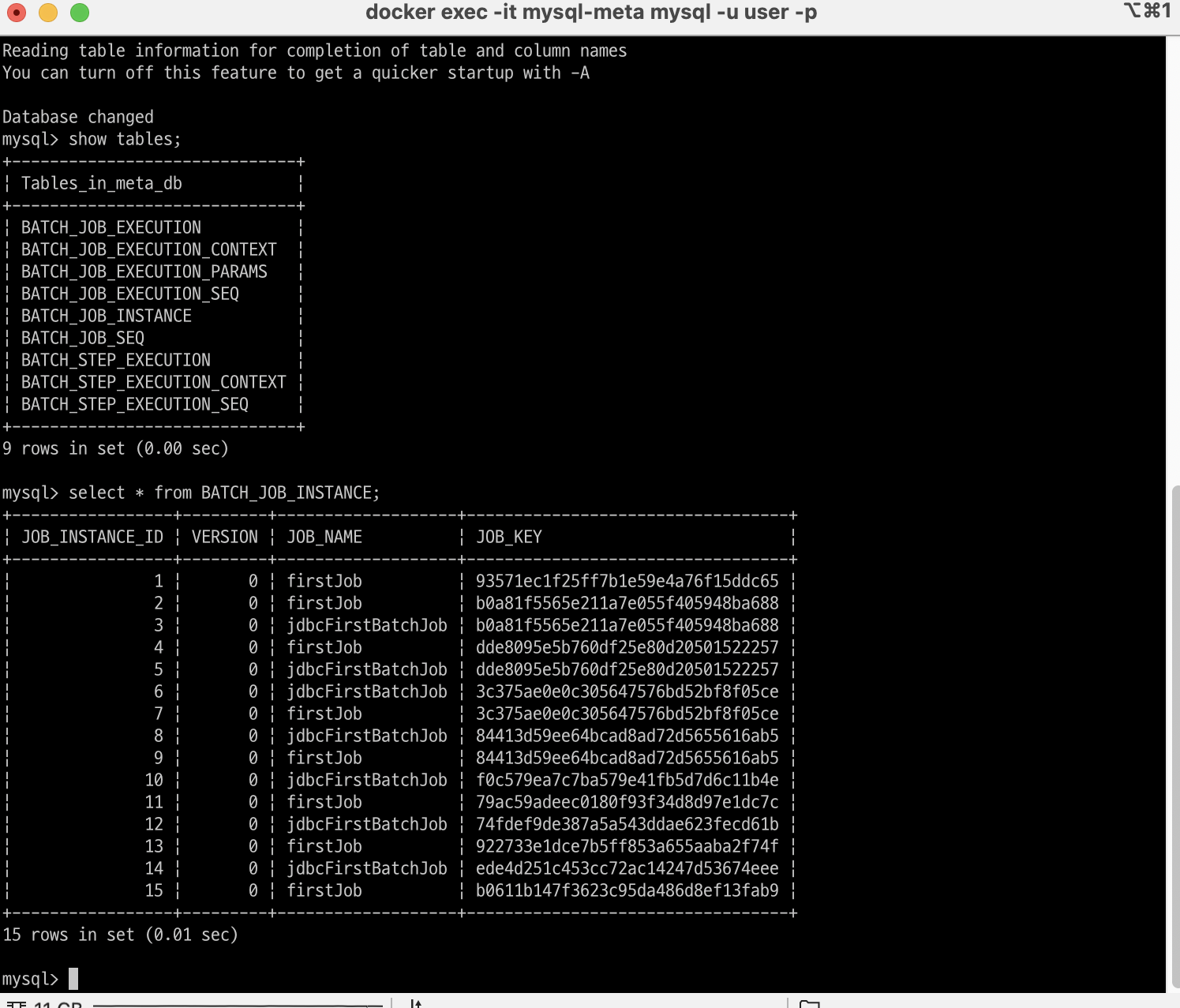
보다시피 메타데이터 테이블이 MySQL 스크립트 기반으로 생성되어 있으며, JobInstance의 작업명 및 해시화된 파라미터 키가 저장되어 있는 것을 확인할 수 있다. 이것을 통해 효율적인 배치 처리 관리가 가능해진다.
2) JDBC 기반 스프링 배치 구현
JPA와 JDBC의 가장 큰 차이점은, SQL에 얼마나 관여하는가의 차이일 것이다. 객체와 데이터베이스의 매핑을 실현하는 JPA의 가장 큰 장점이 SQL 관여도를 낮춤으로써 비즈니스 로직에 집중하는 데에 반면 JDBC는 SQL문까지 개발자가 직접 건드려야 한다.
근데 이것을 반대로 생각하면, SQL문의 책임이 ORM으로 인해 넘겨져서 리소스 소모가 그만큼 가중돼 성능이 저하되는 것과 같고, 대용량 처리가 전제되는 배치 처리에서는 JDBC가 더 유리할 거라는 결론을 낼 수 있다. 그래서 이번에는 JDBC로 동일 시나리오를 구현하고 둘의 성능 비교를 간략히 해본다.
(1) 레포지토리 코드 구현
JpaRepository 인터페이스를 기반으로 간단히 DAO를 구현하는 JPA와 달리, JDBC는 직접 DAO를 세팅해야 한다. BeforeEntity와 AfterEntity의 JDBC DAO는 아래처럼 작성했고, 나는 오프셋 페이징 조회와 배치 저장을 활용했다.
@Repository
@RequiredArgsConstructor
public class BeforeJdbcRepository {
private static final String SQL
= "SELECT id, username FROM BeforeEntity ORDER BY id LIMIT ? OFFSET ?";
private final JdbcTemplate jdbcTemplate;
@Transactional
public List<BeforeEntity> findAll(int pageSize, int offset) {
return jdbcTemplate.query(SQL,
(rs, rowNum) -> {
BeforeEntity entity = new BeforeEntity();
entity.setId(rs.getLong("id"));
entity.setUsername(rs.getString("username"));
return entity;
},
pageSize, offset // 가변 인자 형태로 전달
);
}
}@Repository
@RequiredArgsConstructor
public class AfterJdbcRepository {
private static final String SQL
= "INSERT INTO AfterEntity (id, username) VALUES (?, ?)";
private final JdbcTemplate jdbcTemplate;
@Transactional
public void save(AfterEntity afterEntity) {
jdbcTemplate.update(SQL, afterEntity.getId(), afterEntity.getUsername());
}
@Transactional
public void batchSave(List<? extends AfterEntity> afterEntities) {
jdbcTemplate.batchUpdate(SQL, afterEntities, afterEntities.size(),
(ps, afterEntity) -> {
ps.setLong(1, afterEntity.getId());
ps.setString(2, afterEntity.getUsername());
});
}
}(2) 배치 코드 구현
@Slf4j
@Configuration
@RequiredArgsConstructor
public class FirstJdbcBatch {
private final JobRepository jobRepository;
private final PlatformTransactionManager transactionManager;
private final BeforeJdbcRepository beforeJdbcRepository;
private final AfterJdbcRepository afterJdbcRepository;
@Bean
public Job jdbcBatchJob() {
log.info("JDBC: before 엔티티 테이블 -> after 엔티티 테이블 옮기기");
return new JobBuilder("jdbcFirstBatchJob", jobRepository)
.start(jdbcBatchStep())
.build();
}
@Bean
public Step jdbcBatchStep() {
log.info("JDBC: 첫 번쨰 스탭");
return new StepBuilder("jdbcFirstBatchStep", jobRepository)
.<BeforeEntity, AfterEntity>chunk(10, transactionManager)
.reader(jdbcReader()) // Reader
.processor(jdbcProcessor()) // Processor
.writer(jdbcWriter()) // Writer
.build();
}
// Reader: 데이터를 페이지 단위로 읽어오는 로직
@Bean
public ItemReader<BeforeEntity> jdbcReader() {
return new ItemReader<>() {
private int offset = 0; // 현재 오프셋
private List<BeforeEntity> entities; // 읽어온 엔티티 리스트
private int currentIndex = 0; // 현재 인덱스 (한 페이지에서 읽은 데이터 내 인덱스)
@Override
public BeforeEntity read() {
// 한 번에 데이터를 읽어오고, 다음에 계속 처리할 수 있도록
if (entities == null || currentIndex >= entities.size()) {
int pageSize = 10;
entities = beforeJdbcRepository.findAll(pageSize, offset); // 새로운 페이지 데이터 읽기
if (entities.isEmpty()) {
return null; // 더 이상 데이터가 없을 경우 null 반환 (Spring Batch 종료 조건)
}
offset += pageSize; // offset 증가
currentIndex = 0; // 인덱스를 처음으로 초기화
}
return entities.get(currentIndex++); // 하나씩 순차적으로 반환
}
};
}
// Processor: 데이터를 변환 (BeforeEntity -> AfterEntity)
@Bean
public ItemProcessor<BeforeEntity, AfterEntity> jdbcProcessor() {
return item -> {
AfterEntity afterEntity = new AfterEntity();
afterEntity.setId(item.getId()); // ID를 그대로 유지
afterEntity.setUsername(item.getUsername()); // Username 그대로 복사
return afterEntity;
};
}
// Writer: 배치 저장
@Bean
public ItemWriter<AfterEntity> jdbcWriter() {
return chunk -> {
// Chunk 에서 AfterEntity 리스트 추출
List<? extends AfterEntity> items = chunk.getItems();
// 배치 저장 호출
afterJdbcRepository.batchSave(items); // Batch Insert 호출
};
}
}(1) Reader
BeforeEntity에서 오프셋 페이징 방식으로 데이터를 읽어온다(2) Processor
BeforeEntity에 대응되는 모든 데이터와 동일한 내용의 AfterEntity를 생성한다.(3) Writer
모든 AfterEntity를 청크 단위로 저장한다.
(3) 실행 결과 확인 및 JPA 배치 처리와의 비교
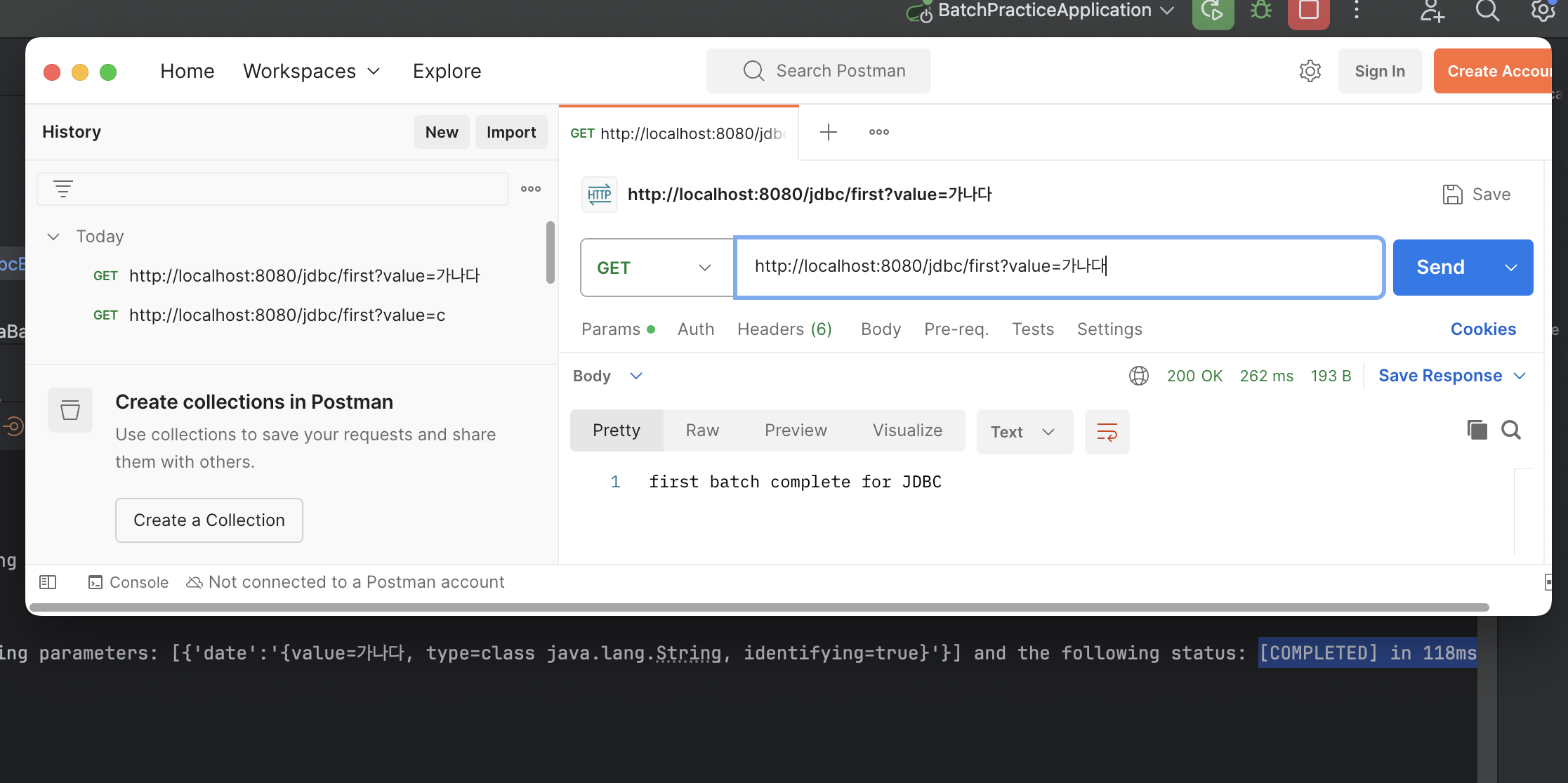
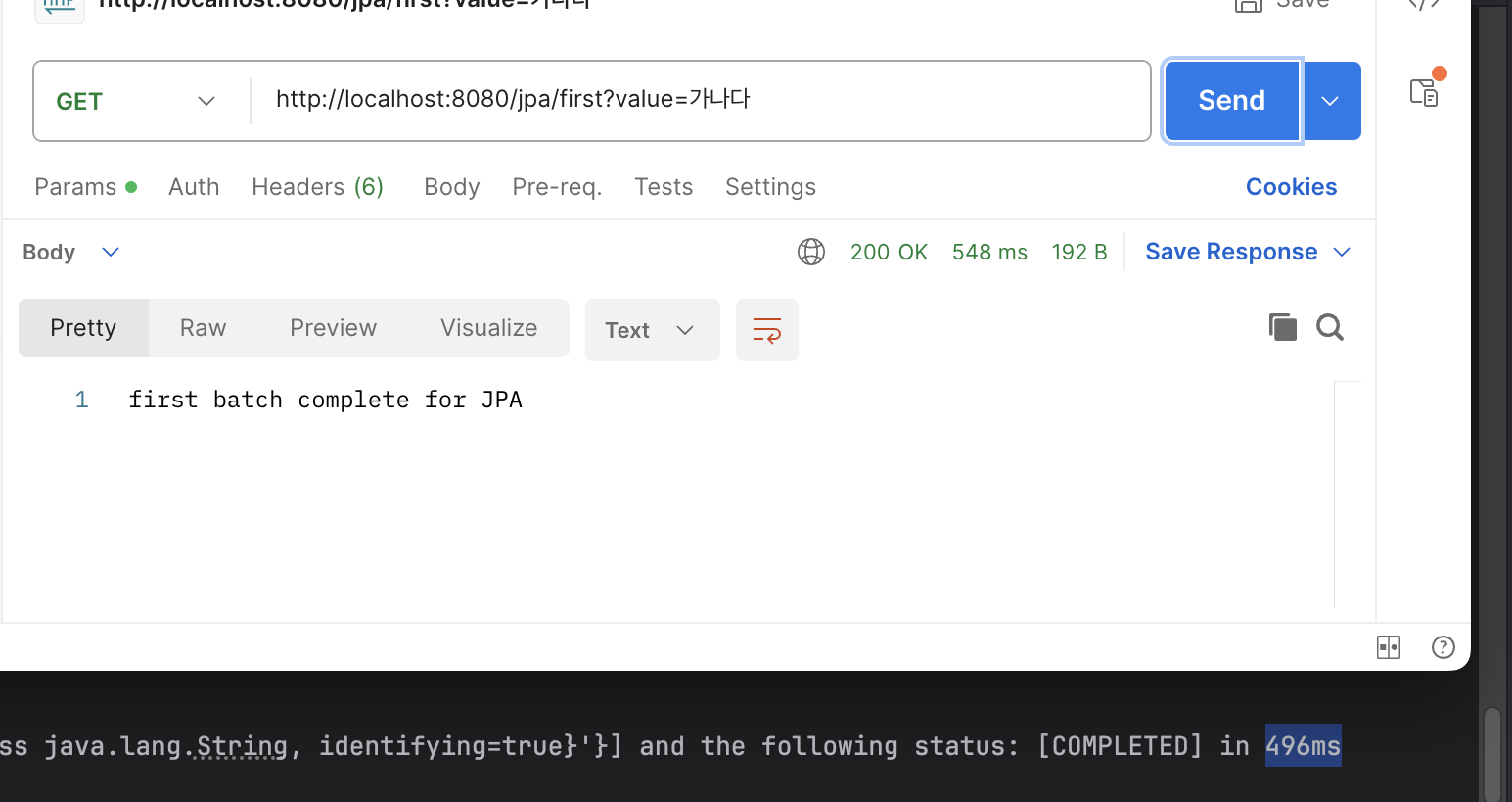
동일 조건에서 JDBC와 JPA 배치 처리를 실행하고 시간을 비교한 결과 JDBC 기반 배치 처리가 근소하게 앞섰다. 아직 데이터베이스에 데이터가 100개 밖에 없어서 10000개로 늘이고 다시 확인해야겠다.
포스팅이 너무 길어진 관계로 다음 포스팅에서는 JUnit 기반으로 실제 실행시간을 측정하고, 테이블 일괄 수정 시나리오를 해본다.
